探索Spark编程模型:RDD与应用程序架构
需积分: 31 65 浏览量
更新于2024-07-20
收藏 1.5MB PDF 举报
本资源是一份由DATAGURU专业数据分析社区提供的Spark大数据平台第一版讲师马军辉讲解的课程内容,主要针对Spark编程模型进行深入解析。课程分为两部分:Spark编程模型和相关技术细节。
首先,课程从上周回顾开始,介绍了Spark的基本生态环境,强调了Spark的核心地位以及RDD(Resilient Distributed Datasets)的重要性,它是Spark数据处理的基础和连接Spark和分布式计算的桥梁。Spark的部署包括集群部署和应用程序部署,Spark应用程序主要由Driver和executor组成,同时提及了Spark的两个常用工具:spark-shell(用于交互式开发)和spark-submit(用于提交作业到集群)。
本周内容主要聚焦于Spark编程模型的具体细节。Spark应用程序的核心结构是Driver和Executor,Driver负责调度任务,而Executor执行实际的计算。Spark应用程序中的基本概念涉及如何通过Driver程序创建SparkContext(用于管理Spark环境和RDD),以及Executor如何接收Driver的指令执行RDD操作,如数据转换(Transformation)和行动(Action)。
Spark编程模型中的关键组件包括DriverProgram,即SparkContext,它提供了与Spark环境的交互接口,允许用户创建、操作和执行RDD。Executor则是运行在集群节点上的执行单元,负责对RDD执行各种操作,如map、filter、reduce等,以完成数据处理任务。
此外,课程还涵盖了Spark-shell的程序调试技巧,这对于理解和优化Spark应用程序至关重要。IDEA(IntelliJ IDEA)作为常用的Java IDE,也被提及为另一种可能的程序调试工具。
本课程深入剖析了Spark编程模型的内在逻辑,从基础概念到实战应用,旨在帮助学习者掌握Spark的大数据处理能力,并能有效地调试和优化Spark应用程序。对于想要深入了解Spark技术的开发者和数据分析师来说,这是一份极其有价值的教育资源。
DATAGURU 专业数据分析社区
Spark 大数据平台 第一版 讲师:马军辉
8
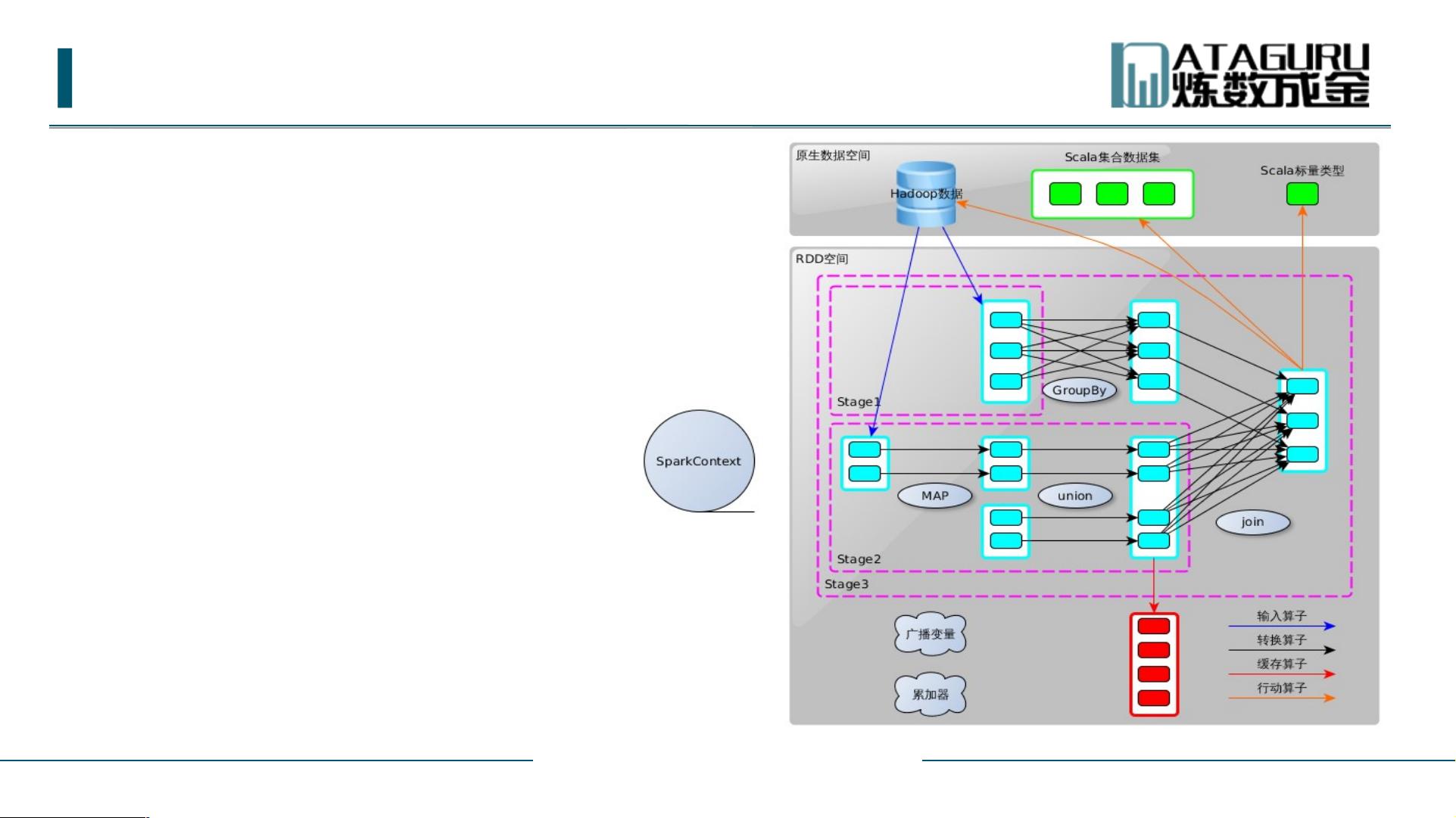
Spark 编程模型
Spark 应用程序编程模型
–
Driver Program ( SparkContext )
–
Executor ( RDD 操作)
●
输入 Base-> RDD
●
Transformation RDD->RDD
●
Action RDD->driver or Base
●
缓存 Persist or cache()
–
共享变量
●
broadcast variables
●
accumulators
剩余40页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2019-08-06 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
2017-02-24 上传









