Spark Standalone集群部署与工作流程详解
需积分: 49 173 浏览量
更新于2024-09-11
收藏 739KB DOCX 举报
Spark standalone分布式集群是一种流行的运行模式,用于在多台机器上分布式地执行Spark应用程序。这种模式允许用户在没有预定义的集群管理器(如YARN或Mesos)的情况下,自行管理和启动Spark集群。以下是关于Spark standalone部署配置和运行的关键知识点:
1. Standalone架构:
Spark standalone模式基于一个Master节点和Worker节点的架构。Master节点负责任务调度和协调,而Worker节点则负责执行实际的计算任务。用户可以通过手工指定slaves列表,将Worker节点添加到集群中。
2. 配置步骤:
- 手动启动集群: 在master节点上,通过`sbin/start-all.sh`脚本来启动所有服务。
- 配置文件:
- `slaves`文件用于指定Worker节点的地址。
- `spark-defaults.conf`存储Spark作业的默认配置。
- `spark-env.sh`包含了Spark的环境变量设置。
- WebUI访问: 集群启动后,可以通过`http://master-ip:8080/`访问Spark的Web用户界面(默认端口为8080,可自定义)。
3. Job提交与运行:
用户可以使用`bin/spark-submit`命令提交Spark作业,例如:
```
./bin/spark-submit --master spark://client:7077 --class org.apache.spark.examples.SparkPi spark-examples-1.6.1-hadoop2.6.0.jar
```
这里`--master`选项指定了集群的URL,`--class`指定要运行的主类。
4. High Availability (HA):
Spark standalone提供了高可用性选项,包括:
- Zookeeper Standby Masters: 使用Zookeeper来监控和切换Master节点,确保即使主节点故障,也能快速恢复。
- Single-Node Recovery with Local FileSystem: 单节点故障时,可以通过本地文件系统实现任务的自动恢复。
5. Spark工作流程:
SparkContext是程序的入口点。在初始化时,它创建了两个主要的调度模块:DAGScheduler和TaskScheduler。DAGScheduler负责作业的高级调度,将任务划分为依赖关系明确的阶段,并考虑数据的本地性;TaskScheduler负责调度具体的任务到Worker节点执行。
总结来说,Spark standalone分布式集群的搭建涉及配置文件的管理、集群的启动和停止,以及通过命令行工具进行作业的提交和监控。了解并掌握这些配置和操作流程,是使用Spark进行大规模分布式计算的基础。同时,理解Spark的工作流程,有助于优化性能和解决常见的故障恢复问题。
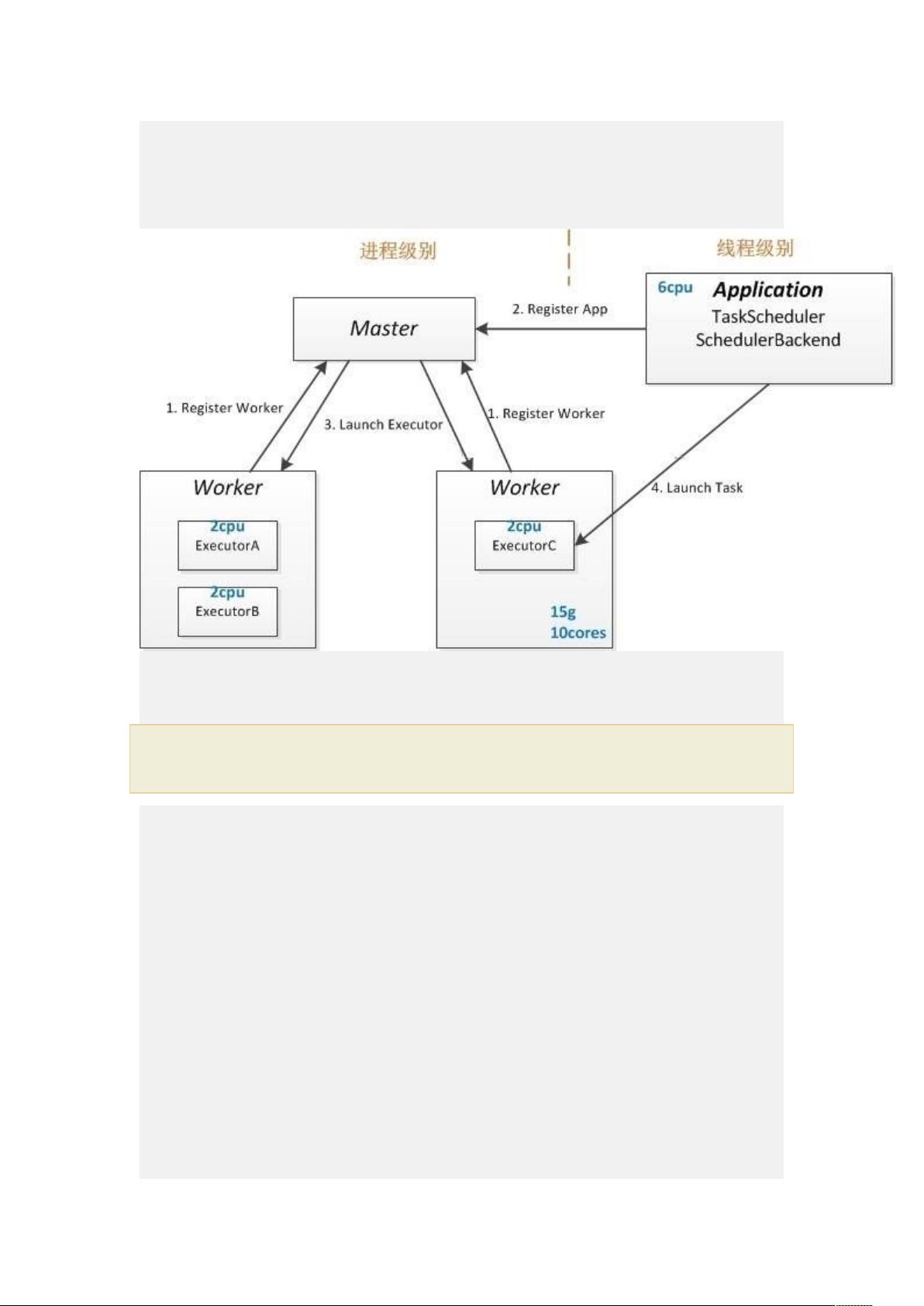
Spark standalone 运行模式
Spark Standalone 部署配置---Standalone 架构
Spark Standalone 部署配置---手工启动一个 Spark 集群
http://spark.apache.org/docs/latest/spark-standalone.html#starting-a-
cluster-manually
Spark Standalone 部署配置---通过脚本启动集群
修改如下配置:
● slaves--指定在哪些节点上运行 worker(下载)
● spark-defaults.conf---spark 提交 job 时的默认配置
● spark-env.sh—spark 的环境变量(下载)
● 在打算作为 master 的节点上启动集群:./sbin/start-all.sh
Spark Standalone 部署配置---访问 web ui
下载后可阅读完整内容,剩余5页未读,立即下载
605 浏览量
606 浏览量
109 浏览量
688 浏览量
152 浏览量
111 浏览量
308 浏览量
566 浏览量
2024-08-24 上传

weixin_42136745
- 粉丝: 0
 我的内容管理
展开
我的内容管理
展开







最新资源
- Sybase15系统管理指南:AdaptiveServerEnterprise中文手册
- Sybase15 AdaptiveServerEnterprise 中文系统表手册
- Eclipse IDE详解:从基础到高级设置
- 深入学习Java:Bruce Eckel的第四版思维之书
- Eclipse整合开发工具基础教程详解
- NIOS II 开发教程:从用户指令到DMA与UART实战
- 操作系统的LRU页面置换算法实现
- STL实战指南:提升编程效率与应对挑战
- TMS320C54XX DSP硬件结构与设计解析
- 自编数据结构文本编辑器实现与错误修正
- VC++6.0实现密码学大数加减乘除源代码示例
- Java贪吃蛇游戏实现:SnakeGame.java代码解析
- 适应性外包发展:寻找最合适的技术与策略
- Libsvm与Matlab集成:教程与路径设置详解
- Oracle 10g 数据库基础概念详解
- S3C6410 RISC Microprocessor User's Manual
