分布式大数据处理框架:Hadoop与Spark解析
需积分: 5 97 浏览量
更新于2024-07-17
收藏 2.32MB PPTX 举报
"这是一份关于Hadoop的PPT讲义,涵盖了Hadoop框架、HDFS分布式文件系统和MapReduce计算模型,以及Spark的相关内容。由Nalini Venkatasubramanian教授讲解,旨在深入介绍Hadoop的起源、优势、架构细节以及在业界的应用。"
Hadoop是一个开源的分布式计算框架,最初由Doug Cutting和Michael J. Cafarella开发,目的是支持Nutch搜索引擎项目的分布式处理,该项目由雅虎资助,并于2006年正式成为Apache软件基金会的项目。Hadoop的设计目标是提供可靠、可扩展和分布式的计算与数据存储解决方案,尤其适合在大规模的商品硬件集群上运行。
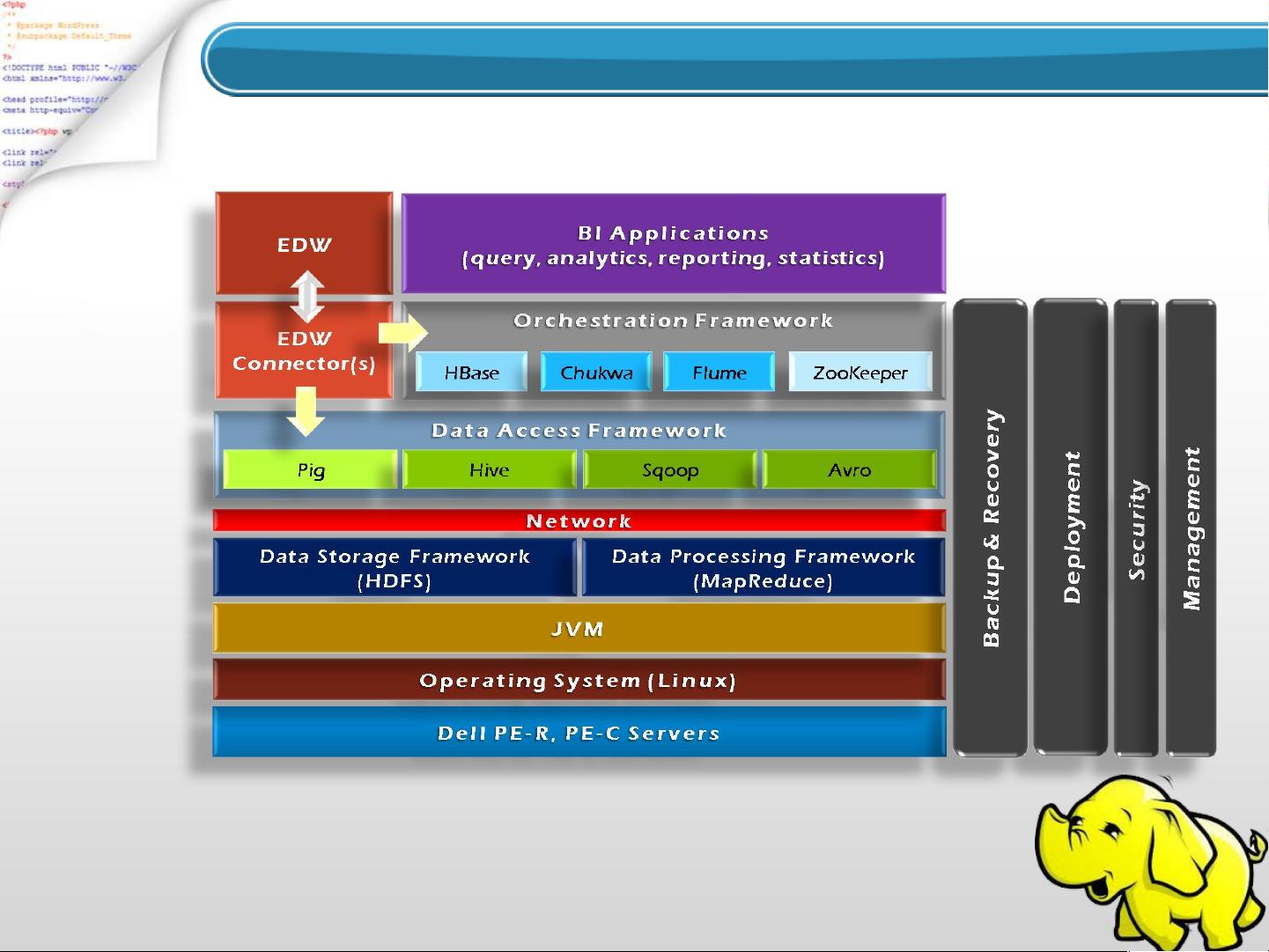
Hadoop的历史可以追溯到1990年代的搜索引擎时代,当时的Google等搜索引擎面临着如何高效处理海量数据的挑战。Hadoop的诞生部分受到了Google的启发,尤其是Google的GFS(Google File System)和MapReduce计算模型。Hadoop的两个主要组成部分是HDFS(Hadoop Distributed File System)和MapReduce。
HDFS是Hadoop的核心,它是一个分布式文件系统,能够将大型数据集分布在成千上万的廉价硬件节点上。HDFS具有高容错性和高吞吐量的特点,即使单个节点故障,也能保证数据的可用性。它的设计原则是数据冗余和本地计算,减少了网络传输,提高了整体性能。
MapReduce是Hadoop的并行计算模型,通过将大任务分解为许多小的“映射”任务和“化简”任务,在各个节点上并行执行。映射阶段对数据进行预处理,化简阶段则聚合和整理结果。这种模型使得Hadoop能够处理PB级别的数据。
随着时间的推移,Hadoop生态系统不断发展,出现了如Avro(一种数据序列化系统)和Chukwa(用于大型分布式系统的数据收集系统)等新工具。此外,随着大数据处理需求的增加,Spark作为一个快速、通用且可扩展的数据处理框架,逐渐与Hadoop结合,提供了更高效的内存计算和交互式查询能力,弥补了MapReduce在迭代计算和实时处理上的不足。
Hadoop在业界的应用广泛,包括互联网公司、电信、金融、零售等多个领域,用于数据分析、用户行为分析、推荐系统、日志处理等多种场景。例如,通过Hadoop,公司可以快速地对海量的用户点击流数据进行分析,从而优化产品推荐和服务质量。
Hadoop及其相关技术的发展极大地推动了大数据处理和分析的能力,为各行各业提供了强大的工具,应对日益增长的海量数据挑战。随着技术的不断进步,Hadoop生态系统将继续演化,为大数据时代提供更加高效和灵活的解决方案。

What is Hadoop?
:
Hadoop:
:
%!&&%
"!$!
!"!(
:
Goals / Requirements:
:
!&!'!'&
';''
:
!%!
:
''
:
'!"
:
<!=!>7!
:
6%!
:
"!
剩余54页未读,继续阅读
2018-09-19 上传
2022-12-24 上传
2021-10-11 上传
2021-08-06 上传
2022-11-02 上传
2021-06-02 上传
2021-09-19 上传

KOBE1288
- 粉丝: 1
- 资源: 5
 我的内容管理
展开
我的内容管理
展开







