中文分词资源概览:语料、工具与研究平台
需积分: 10 184 浏览量
更新于2024-07-17
1
收藏 2.5MB PPTX 举报
在自然语言处理领域,特别是中文分词的研究中,语料资源的丰富性和质量对于模型的训练和性能至关重要。【标题】"中文分词资源简介"深入探讨了汉语分词过程中所需的各种关键资源,如语料库的构建和使用。
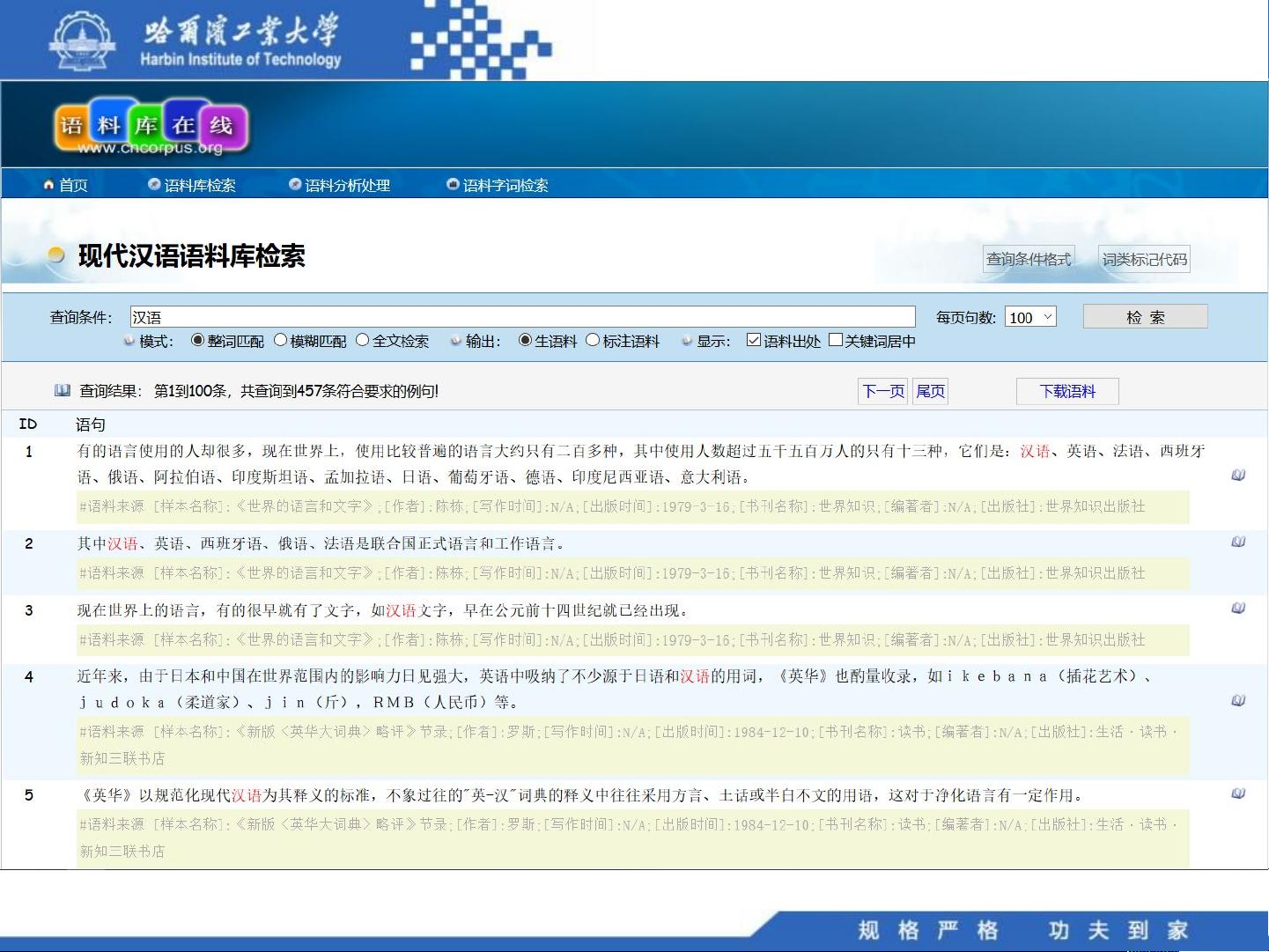
语料库是研究的基础,它是指在实际语言使用中收集并整理的大规模文本数据,对于中文分词而言,它包含了各种类型的文本,如现代汉语通用平衡语料库,该库不仅提供约2000万字的现代汉语分词和词性标注语料,还增加了古代汉语的生语料,共计一亿字,这对于研究古代汉语和词汇变迁非常有价值。例如,国家语委的在线语料库平台(<http://corpus.zhonghuayuwen.org/>)不仅提供检索服务,还配备有分词、词性标注软件、词频和字频统计工具,方便教学和研究。
哈工大信息检索研究中心的语言技术平台(<http://ir.hit.edu.cn/demo/ltp/Sharing_Plan.htm>)和台湾“中央研究院”的现代汉语语料库(<http://lingcorpus.iis.sinica.edu.tw/modern/>)也都是重要的资源,前者提供了一些语言技术工具,后者则有丰富的语料库资源,但对外部用户有限制条件,以保护数据安全。
中文语言资源联盟(CLDC,<http://www.chineseldc.org/>)作为一个学术性、公益性和非盈利性的组织,旨在推动中文语言资源的建设和共享,它的目标是建立国际水平的中文语言资源库,为中文信息处理研究和应用开发提供强有力的支持,促进技术进步。
在选择和使用这些资源时,研究者应考虑语料库的规模、来源的权威性、标注的准确性以及是否包含特定领域的文本。评估和比较不同的分词工具,如谢沛昇中文分词语料库,对于优化分词算法和提高模型性能至关重要。这个PowerPoint文件为从事中文分词工作的专业人士提供了全面的资源指南,帮助他们更好地理解和利用这些宝贵的数据资产。

语料库检索
语料分析处理
资源下载
剩余39页未读,继续阅读
2018-11-30 上传
2018-12-01 上传
2019-07-30 上传
2013-06-03 上传
2018-01-03 上传

PS_Xie
- 粉丝: 10
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- c代码-神奇的代码
- 基于springboot+springSecurity+jwt实现的基于token的权限管理的一个demo,适合新手
- 可制作:个人网站
- moviereview-api:解析印度时报网站,获取最新电影评级和评论
- TypeScript
- stupidedi:用于解析和生成ASC X12 EDI事务的Ruby API
- c#仓库管理系统.zip
- 2023的测试代码,没有任何用处,只是不想丢掉
- 美萍茶楼管理标准版v4.2.rar
- JSM2018_ecosystem:JSM 2018“用于数据科学统计教育的新兴生态系统”
- c代码-UPDATE PROGRAM (ENGLISH EDITION) v4.7.8.5
- TranslucentScrollView
- aipets-springboot:aipets springboot服务器端
- url_shortener
- redditUpvoteDownloader:下载个人认可的reddit图像
- upload:FuelPHP框架-文件上传库
