Python Scrapy租房信息爬取与Django数据展示工具实战
版权申诉
198 浏览量
更新于2024-06-22
收藏 4.16MB DOCX 举报
本篇论文深入探讨了在Python爬虫框架Scrapy下进行租房信息的高效抓取与数据分析的应用。随着互联网的普及,线上租房已成为年轻人的首选,但海量且分散的网络信息使得用户体验成为关键挑战。论文首先介绍了当前互联网环境下的租房市场趋势,强调了提升用户满意度的必要性。
作者以Scrapy作为核心技术,Scrapy是一款强大的Python爬虫框架,能够有效地从多个租房信息网站提取数据,支持分布式爬取,具有高度的可扩展性和效率。通过Scrapy,作者构建了一个定制化的租房信息爬虫系统,它能自动抓取包含租房信息的各类在线平台上的动态内容,如房源详情、价格、位置等关键数据。
数据抓取后,论文着重讨论了数据存储问题。为了方便管理和分析,作者选择了非结构化数据库来存储这些抓取的数据。非结构化数据库如MongoDB或Couchbase,能够灵活地存储和查询各种复杂的数据结构,适应租房信息这种多样化的数据形式。
进一步,论文介绍了基于Python开源Web框架Django的数据展示系统的设计与实现。Django提供了丰富的功能和易于维护的特性,用于搭建用户友好的租房信息展示平台。该系统能够从非结构化数据库中检索和整合数据,以列表、地图等形式呈现给用户,提供直观的房源搜索和筛选功能,极大地提升了用户的租房体验。
同时,为了更好地理解和利用这些抓取的数据,论文还涵盖了数据可视化的部分。通过数据可视化工具,如Matplotlib、Seaborn或Plotly,作者将复杂的租房数据转化为图表和图形,帮助用户快速理解市场动态、价格分布以及热门区域等关键信息。这不仅有助于决策者做出明智的选择,也增强了数据分析的价值。
这篇论文通过实际项目展示了如何结合Scrapy、Django和非结构化数据库的优势,构建一个完整的租房信息获取与数据展示系统,为提升在线租房市场的用户体验提供了实用的解决方案。关键词包括Scrapy、Django、非结构化数据库和数据可视化,突出了论文的核心技术和应用价值。

7
存储的影响。然后采用 python 开源网站搭建框架 Django 完成对爬取到的租房信息的
web 端展示。除此之外,本系统采用高德地图 API 提供的“坐标拾取器”功能完成位置
信息与经纬度之间的转换,并将爬取到的数据可视化展示在地图上,一并展示于前端页
面。在爬虫部分,除了对房屋租赁信息的爬取外,还实现了对网上免费代理的爬取、存
储、有效性验证与维护。本系统还涉及到的技术有:MongoDB 与 scrapy 框架的集成,
MongoDB 与 Django 框架的集成,semantic UI 快速 html5 界面开发等。
1.4 论文的整体结构
本论文共由六章组成,各章节安排如下:
第一章绪论,说明了该系统开发的可行性与现实应用意义,介绍了爬虫技术及反爬
虫技术的发展现状,介绍了开发该系统所预期达到的目标及所需做的工作。
第二章对系统中涉及到的相关技术进行了介绍,并说明了相关技术在本系统中的作
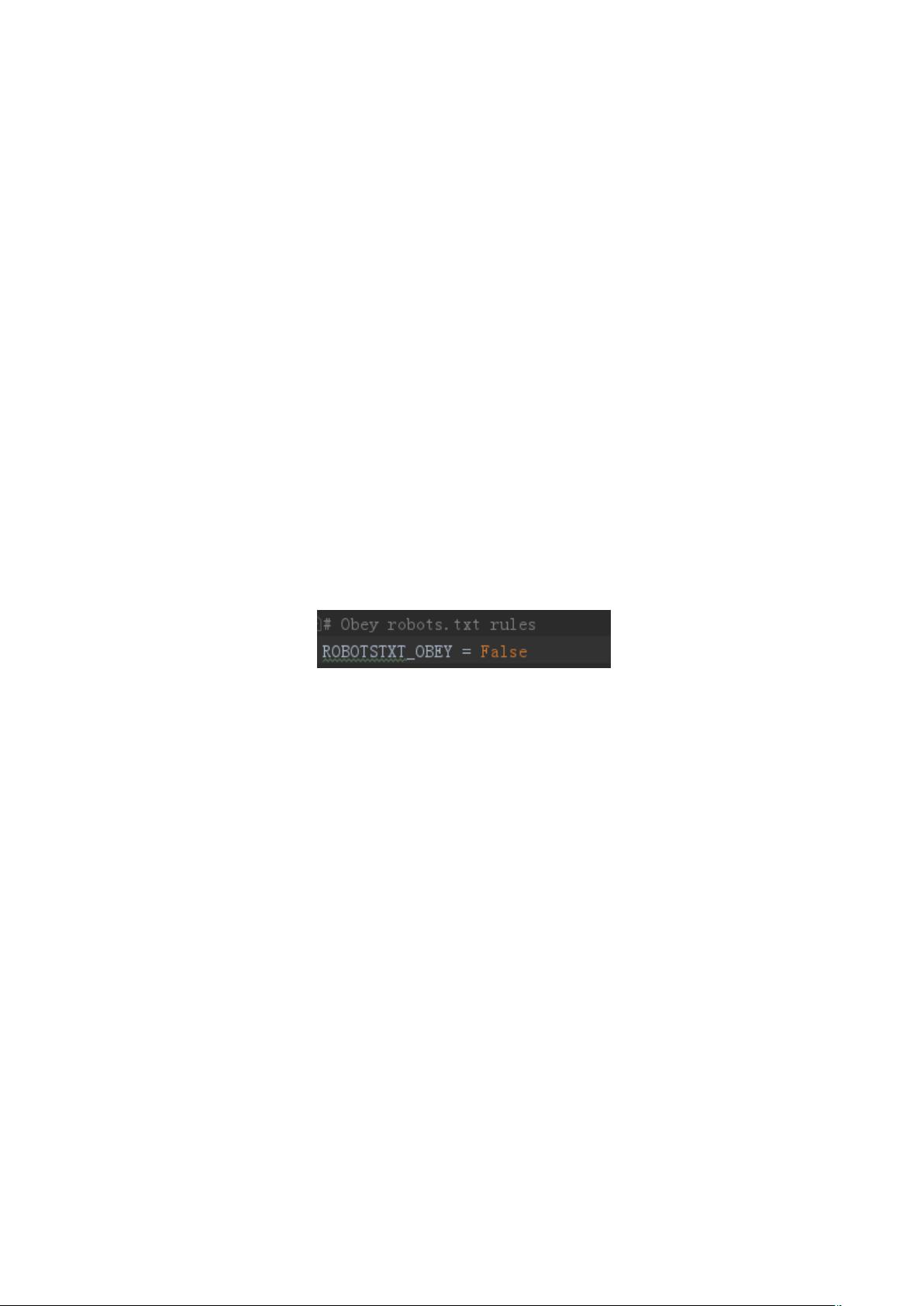
用。如 Robot 协议等,其中着重对爬虫架构 scrapy、非结构化数据库 MongoDB、开源
网站框架 Django 进行了介绍。
第三章为系统分析与设计,本章对所要完成的系统进行了整体分析设计。分析了系
统所要实现的功能,设计出总体架构,对其进行细分,分成各个模块,然后对各个模块
进行了介绍。
第四章为系统设计实现与成果展示,本章编写代码实现了爬虫,对数据库进行了设
计,并完成了数据展示模块。最后对本系统的运行成果进行了展示。
第五章系统测试。本章对整个系统进行测试,包括对测试环境的描述,对系统的功
能性测试和非功能性测试。
第六章总结与展望,本章对系统进行总结,并总结了开发过程中的一些所思所想。
然后对本系统的进一步研究方向进行了展望。
1.5 本章小结
本章主要是对该系统进行了介绍。首先介绍了研究该问题的背景、可行性及现实意
义,接着对国内外相关领域的研究进行了分析。接着根据以上分析引出了本系统的主要
研究内容,最后对本篇论文的结构进行了介绍。

剩余68页未读,继续阅读
2023-11-03 上传
2022-06-24 上传
2020-12-17 上传
2023-08-06 上传
2024-04-22 上传
2022-02-13 上传
2019-08-10 上传
2017-05-01 上传

豆包程序员
- 粉丝: 1w+
- 资源: 3937
 我的内容管理
展开
我的内容管理
展开







最新资源
- 几乎所有的findIndex练习:Springboard软件工程职业生涯跟踪子单元8.2的练习
- pyg_lib-0.2.0+pt20cpu-cp310-cp310-linux_x86_64whl.zip
- Gravity-Game
- LiveCue-开源
- shield-db::shield_selector:Shield DB,Dot Shield使用的广告和跟踪器的数据库
- swift-boilerplate:使用文件和项目模板节省创建Swift应用程序的时间
- espriturc:预订土耳其语课程的网站
- ANNOgesic-0.7.29-py3-none-any.whl.zip
- angular-remove-diacritics:角度服务可消除字符串中的重音符号
- 减去图像均值matlab代码-PCA-Image-Compression:PCA-图像压缩
- test-msw
- chipster-web
- smart-contract-tutorial:该存储库包含我们的文章https中使用的完整代码
- xderm-mini
- Inventory_management:Etsy小型企业的库存管理
- HFTuner:免提吉他调音器!
