RDDs: 分布式内存计算的容错抽象与Spark实践
需积分: 9 15 浏览量
更新于2024-07-19
1
收藏 1.41MB DOCX 举报
Spark的Resilient Distributed Datasets (RDDs) 是一种核心概念,它是Apache Spark中用于大规模分布式内存计算的抽象模型。它旨在解决传统分布式计算框架如MapReduce和Dryad在处理迭代式算法和交互式数据挖掘场景时性能低下的问题。RDDs的设计理念是提供一种容错的、基于粗粒度共享状态的内存计算方式,避免了细粒度更新带来的复杂性和效率损失。
RDDs的主要优势在于它能够在内存中保存数据,显著提升需要多次数据复用的应用性能。在迭代式任务中,如机器学习中的PageRank、K-means和线性回归,以及图计算,数据的重复使用至关重要。而在交互式数据挖掘中,用户可能对同一数据集进行多轮不同查询,这也需要高效的数据复用。然而,传统的框架通常将中间数据存储在磁盘或分布式文件系统,导致性能受限于复制、I/O和序列化操作。
为了克服这些问题,Spark引入了RDDs,它允许用户在分布式环境中进行内存中的计算,减少了数据传输和I/O开销。这种设计允许对中间结果进行高效共享,而不会引发大规模的数据复制。Spark系统内建了对RDDs的支持,使得开发者能够使用API进行高层次操作,无需担心底层的分布式细节,从而简化了大规模并行处理的编程。
尽管Spark的RDDs在设计上限制了某些精细操作,但其灵活性和抽象能力使得它可以支持多种计算类型,包括现有的迭代计算模型(如Pregel),甚至还能扩展到现有模型无法表示的计算。通过Spark实践中的用户应用和广泛的测试,我们可以验证其在实际场景中的效能和适用性。
理解Spark RDDs的关键在于掌握其内存计算的容错机制,粗粒度共享状态的概念,以及如何在实际编程中利用API进行高效的数据处理和复用。通过阅读论文和实践,开发者可以更好地运用Spark进行大数据处理,优化迭代和交互式计算任务。
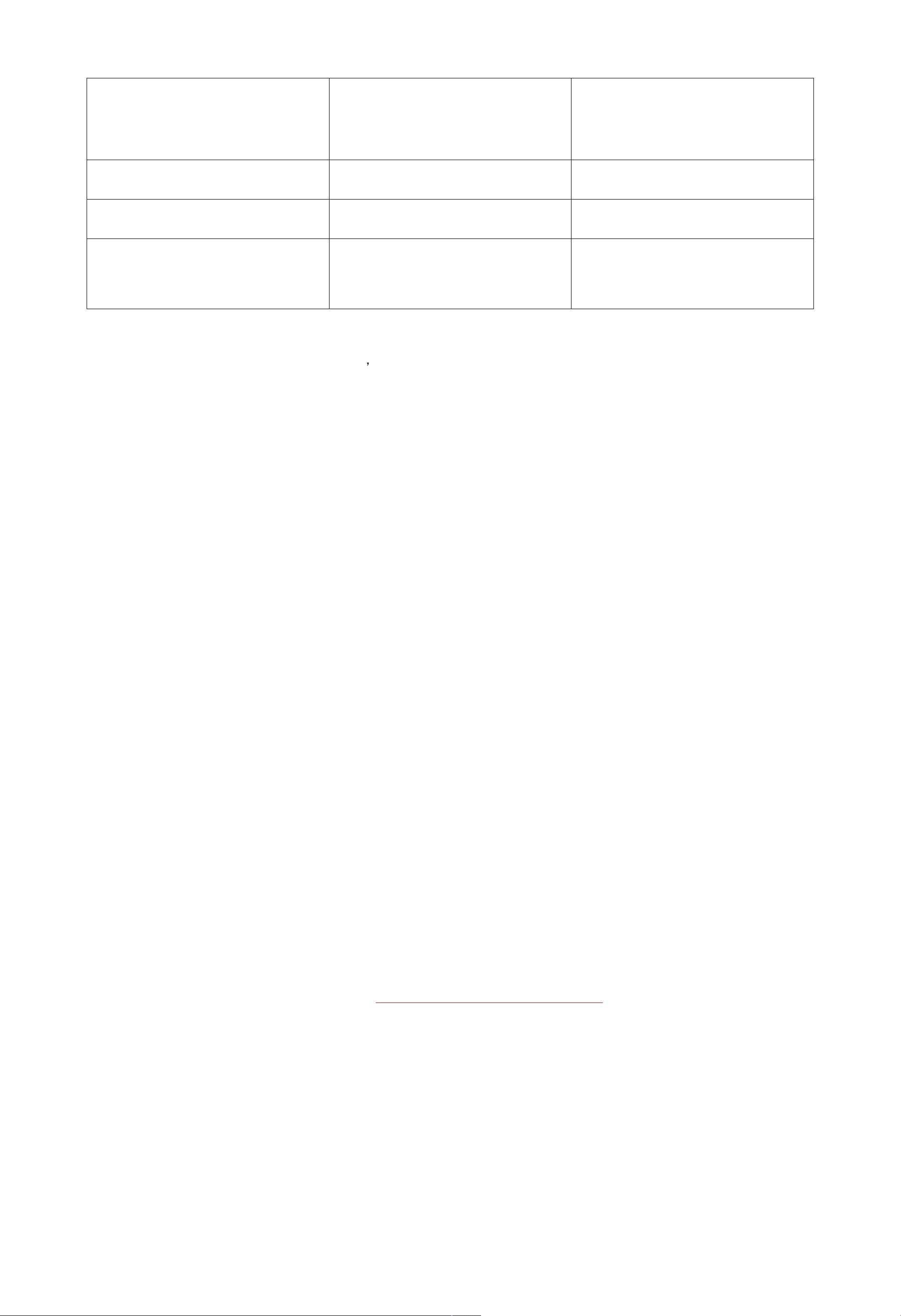
并且需要程序回滚
计算慢的任务 可以利用备份的任务来解决 很难做到
计算数据的位置 自动的机遇数据本地性 取决于 app (runtime 是以透明为目标的)
内存不足时的行为 和已经存在的数据流处理系统一样,写磁
盘
非常糟糕的性能(需要内存的交换?)
表一: RDDs 和 Distributed shred memory 对比
RDDs 只能通过粗粒度的转换被创建(或者被写),然而 DSM 允许对每一个内存位置进行读写,这个时 RDDs 和 DSM 最主要的区别。
这样使的 RDDs 在应用中大量写数据受到了限制,但是可以使的容错变的更加高效。特别是,RDDs 不需要发生非常耗时的
checkpoint 操作,因为它可以根据 lineage 进行恢复数据。而且,只有丢掉了数据的分区才会需要重新计算,并不需要回滚整个程序,
并且这些重新计算的任务是在多台机器上并行运算的
RDDs 的第二个好处是:它不变的特性使的它可以和 MapReduce 一样来运行执行很慢任务的备份任务来达到缓解计算很慢的节点
的问题。在 DSM 中,备份任务是很难实现的,因为原始任务和备份任务或同时更新访问同一个内存地址和接口
最后,RDDs 比 DSM 多提供了两个好处。第一,在对 RDDs 进行大量写操作的过程中,我们可以根据数据的本地性来调度 task 以
提高性能。第二,如果在 scan-base 的操作中,且这个时候内存不足以存储这个 RDDs,那么 RDDs 可以慢慢的从内存中清理掉。在内
存中存储不下的分区数据会被写到磁盘中,且提供了和现有并行数据处理系统相同的性能保证。
2.4 不适合用 RDDs 的应用
经过上面的讨论介绍,我们知道 RDDs 非常适合将相同操作应用在整个数据集的所有的元素上的批处理应用。在这些场景下,RDDs
可以利用血缘关系图来高效的记住每一个 transformations 的步骤,并且不需要记录大量的数据就可以恢复丢失的分区数据。RDDs 不
太适合用于需要异步且细粒度的更新共享状态的应用,比如一个 web 应用或者数据递增的 web 爬虫应用的存储系统。对于这些应用,
使用传统的纪录更新日志以及对数据进行 checkpoint 会更加高效。比如使用数据库、RAMCloud、Percolator 以及 Piccolo。我们的目标
是给批量分析提供一个高效的编程模型,对于这些异步的应用需要其他的特殊系统来实现
3 spark 编程接口
真正理解并熟练应用 spark 编程接口可以参考 : http://edu.51cto.com/course/11058.html
spark 使用 scala 语言实现了抽象的 RDD,scala 是建立在 java VM 上的静态类型函数式编程语言。我们选择 scala 是因为它结
合了简洁(很方便进行交互式使用)与高效(由于它的静态类型)。然而,并不是说 RDD 的抽象需要函数式语言来实现
开发员需要写连接集群中的 workers 的 driver 程序来使用 spark,就比如图 2 展示的。Driver 端程序定义了一系列的 RDDs
并且调用了 RDD 的 action 操作。Driver 的程序同时也会跟踪 RDDs 之间的的血缘关系。workers 是可以将 RDD 分区数据存储
在内存中的长期存活的进程
剩余21页未读,继续阅读
2018-05-07 上传
2022-09-21 上传
2016-09-09 上传
2018-11-14 上传
2017-12-08 上传
2021-10-01 上传
2023-06-12 上传
2022-09-22 上传
2022-09-23 上传

xiong_cc
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- SSM Java项目:StudentInfo 数据管理与可视化分析
- pyedgar:Python库简化EDGAR数据交互与文档下载
- Node.js环境下wfdb文件解码与实时数据处理
- phpcms v2.2企业级网站管理系统发布
- 美团饿了么优惠券推广工具-uniapp源码
- 基于红外传感器的会议室实时占用率测量系统
- DenseNet-201预训练模型:图像分类的深度学习工具箱
- Java实现和弦移调工具:Transposer-java
- phpMyFAQ 2.5.1 Beta多国语言版:技术项目源码共享平台
- Python自动化源码实现便捷自动下单功能
- Android天气预报应用:查看多城市详细天气信息
- PHPTML类:简化HTML页面创建的PHP开源工具
- Biovec在蛋白质分析中的应用:预测、结构和可视化
- EfficientNet-b0深度学习工具箱模型在MATLAB中的应用
- 2024年河北省技能大赛数字化设计开发样题解析
- 笔记本USB加湿器:便携式设计解决方案
