三大应用服务器调优指南:WebLogic、Tomcat与WebSphere
需积分: 9 169 浏览量
更新于2024-07-23
收藏 4.38MB DOC 举报
"该文档主要讨论了WebLogic、Tomcat和WebSphere这三大主流Java应用服务器的调优方法,特别是针对WebLogic的调优步骤和参数配置进行了详细阐述。"
在Java应用服务器的世界中,WebLogic、Tomcat和WebSphere是广泛使用的三大平台。调优这些服务器对于提高应用性能、稳定性和资源利用率至关重要。以下是针对这三大服务器的一些关键调优策略:
**WebLogic调优**
WebLogic Server是一款由Oracle公司提供的企业级Java应用服务器,调优主要是为了提高其处理能力、减少响应时间并优化内存使用。文档中提到了以下几点调优步骤和参数:
1. **线程池优化**:线程池管理着服务器处理请求的工作线程,合理的配置可以避免过多线程导致的内存浪费或线程不足导致的响应延迟。可以通过修改`<server>`元素下的`<thread-pool>`配置来调整线程池大小。
2. **Web应用部署描述符配置**:在`web.xml`文件中,可以调整如session超时、过滤器和监听器等设置,以优化应用的行为。
3. **连接缓冲池参数配置**:数据库连接池的大小和配置直接影响到数据库访问性能。可通过调整`JDBC`数据源的最小、最大连接数,以及连接超时等参数。
4. **JVM配置**:JVM参数对服务器性能有着直接影响。如`JAVA_OPTS`中设置的`-Xms`和`-Xmx`分别指定初始和最大堆内存,`-XX:PermSize`和`-XX:MaxPermSize`设定持久代大小。适当的设置可以防止频繁的垃圾回收,提高性能。
**调优步骤**
调优通常遵循以下流程:
1. **基准参数配置**:安装后根据官方推荐配置进行初步设置。
2. **基准测试**:运行负载测试,如LoadRunner,评估当前配置下的性能。
3. **问题分析**:根据测试结果识别性能瓶颈和错误,分析日志以定位问题原因。
4. **参数调整**:针对性地调整1-2个参数,逐步优化,每次调整后重新测试。
**Tomcat调优**
Tomcat是一款轻量级的Java应用服务器,主要关注点包括:
- **JVM内存设置**:与WebLogic类似,调整JVM内存参数对Tomcat性能有很大影响。
- **线程池设置**:在`server.xml`中的`Executor`元素中配置线程池。
- **连接器优化**:如`Connector`的`maxThreads`和`minSpareThreads`参数。
- **日志和错误处理**:优化日志输出,减少不必要的资源消耗。
**WebSphere调优**
IBM的WebSphere Application Server提供了丰富的调优选项:
- **服务器配置**:包括线程池、连接池、内存设置等。
- **模块和应用程序配置**:调整应用的部署描述符。
- **JVM和类加载器优化**:调整JVM参数和类加载策略。
- **资源调度**:如数据库连接池和网络I/O。
调优是一个持续的过程,需要根据实际情况和性能监控数据进行迭代优化。正确配置和调优这些服务器能显著提升Java应用的性能,确保系统的稳定性和可扩展性。
第四章 安装和配置应用服务器
3.修改 TB3.X 系统的 web.xml 文件
<servlet>
<servlet-name>action</servlet-name><servlet-
class>com.neusoft.talentbase.framework.core.strutsextension.ActionServlet</servlet-class>
<init-param>
<param-name>wl-dispatch-policy</param-name>
<param-value>MyExecute</param-value>
</init-param>
红色部分为添加部分,就是在 action 这个 servlet 里加入一个初始化参数。Prara-name 的值必须是 wl-
dispatch-policy,<param-value>的值为第二步新配置的线程队列的名称。这样所有 action 处理的请求就和
MyExecute 这个线程队列关联起来了。
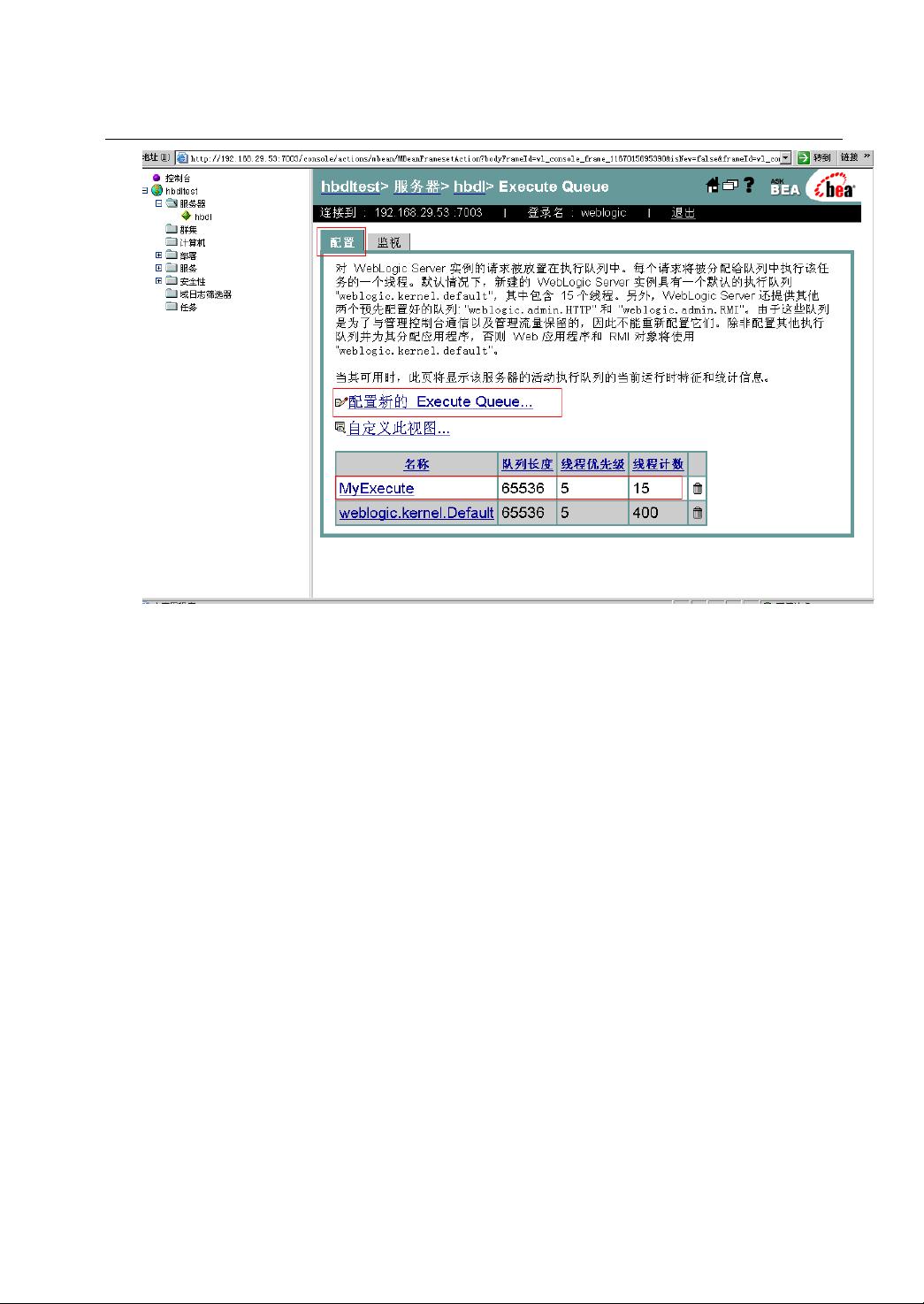
现 在 就 有 两 个 线 程 池 来 处 理 TB 系 统 的 请 求 了 : MyExecute 专 门 处 理 jsp\.do 请 求 ,
weblogic.kernel.Default 只处理 js\jpg\css 等资源文件的请求。
接下来需要配置这两个线程池最重要的一个参数了,那就是线程计数(thread count)。
MyExecute 的线程计数参数配置:由于 MyExecute 专门处理业务请求,所以它的线程计数的大小对系
统的性能影响最大,最容易使系统资源造成瓶颈。基准参数配置(见第一章)中,这个值建议和服务器
cpu 数保持一致,如服务器是 2 个 cpu 超线程的,那该值可以配置为 4。经过一定的性能测试该值可以适当
调大,当测试发现失败较多或 cpu 利用率非常高时可以减少该值。
weblogic.kernel.Default 的线程计数参数配置:由于 weblogic.kernel.Default 这个线程池处理的是资源请
求,通常处理速度会较快一些,所以基准参数配置中,这个值可以大于 MyExecute 的线程计数,建议为它
的 2 倍,如 8 个。经过测试可以发现,该值设置较大时(如 100、200)性能可以有所改进,具体情况可以
根据实际测试结果调整,当这个值超出一定值后性能不会有改善,相反会浪费系统资源,有时还会导致失
败率增加。
§3.2 Web 应用部书描述符配置
将 TB 应用的 Servlet 重新加载检查(秒)改成-1,JSP 页检查(秒)改成-1。
3
剩余18页未读,继续阅读
2024-11-07 上传
2024-11-07 上传
2024-11-07 上传
2024-11-07 上传

lbj_kk77
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- 探索数据转换实验平台在设备装置中的应用
- 使用git-log-to-tikz.py将Git日志转换为TIKZ图形
- 小栗子源码2.9.3版本发布
- 使用Tinder-Hack-Client实现Tinder API交互
- Android Studio新模板:个性化Material Design导航抽屉
- React API分页模块:数据获取与页面管理
- C语言实现顺序表的动态分配方法
- 光催化分解水产氢固溶体催化剂制备技术揭秘
- VS2013环境下tinyxml库的32位与64位编译指南
- 网易云歌词情感分析系统实现与架构
- React应用展示GitHub用户详细信息及项目分析
- LayUI2.1.6帮助文档API功能详解
- 全栈开发实现的chatgpt应用可打包小程序/H5/App
- C++实现顺序表的动态内存分配技术
- Java制作水果格斗游戏:策略与随机性的结合
- 基于若依框架的后台管理系统开发实例解析
