Kafka架构详解:生产者、代理与消费者的角色与高效策略
Kafka是一个分布式流处理平台,其架构主要由生产者(Producer)、代理(Broker)和消费者(Consumer)三个核心组件构成。这些组件共同实现了一个高效的消息传输系统。
生产者(Producer)是消息和数据的源头,负责将数据转换成可序列化的消息,并通过Kafka提供的注册接口发送到Broker。Kafka的设计允许生产者灵活配置消息的发送策略,包括消息的分区分布方式,可以选择随机或按照用户自定义的回调函数进行分配。
代理(Broker)是Kafka的核心功能部分,它扮演着消息缓存和分发的角色。Broker采用Linux文件系统的缓存技术,直接利用Sendfile进行零拷贝操作,显著减少了数据发送过程中的系统上下文切换,提高了约60%的性能。每个消息被发送到Broker后,会被均匀分布到Topic下的多个Partition中,每个Partition有自己的逻辑日志(Log)和多个Segment。消息的存储基于消息ID的逻辑位置,使得定位消息更加高效。
当Segment中的消息满载或达到特定时间阈值时,Broker会将这些消息flush到磁盘,确保数据持久化。同时,Broker通过创建新的Segment来控制内存使用,避免无限增长。在分布式部署中,Producer和Broker之间的负载均衡并非自动进行,而是依赖于ZooKeeper进行协调,通过ZooKeeper管理元数据并监控节点状态。
消费者(Consumer)则是消息的接收者,它们从Broker订阅消息。当Broker将消息写入磁盘后,只有已flush的消息才能被Consumer接收到。整个系统是分布式的,所有Producer、Broker和Consumer节点都支持多个实例,这增强了系统的容错性和扩展性。然而,Broker和Consumer之间的负载均衡是在ZooKeeper的协助下完成的,确保了系统的稳定运行。
Kafka的高效架构得益于其对文件系统缓存、零拷贝技术的运用,以及细致的消息管理策略和分布式设计。理解和掌握这些关键要素对于有效使用和优化Kafka至关重要。
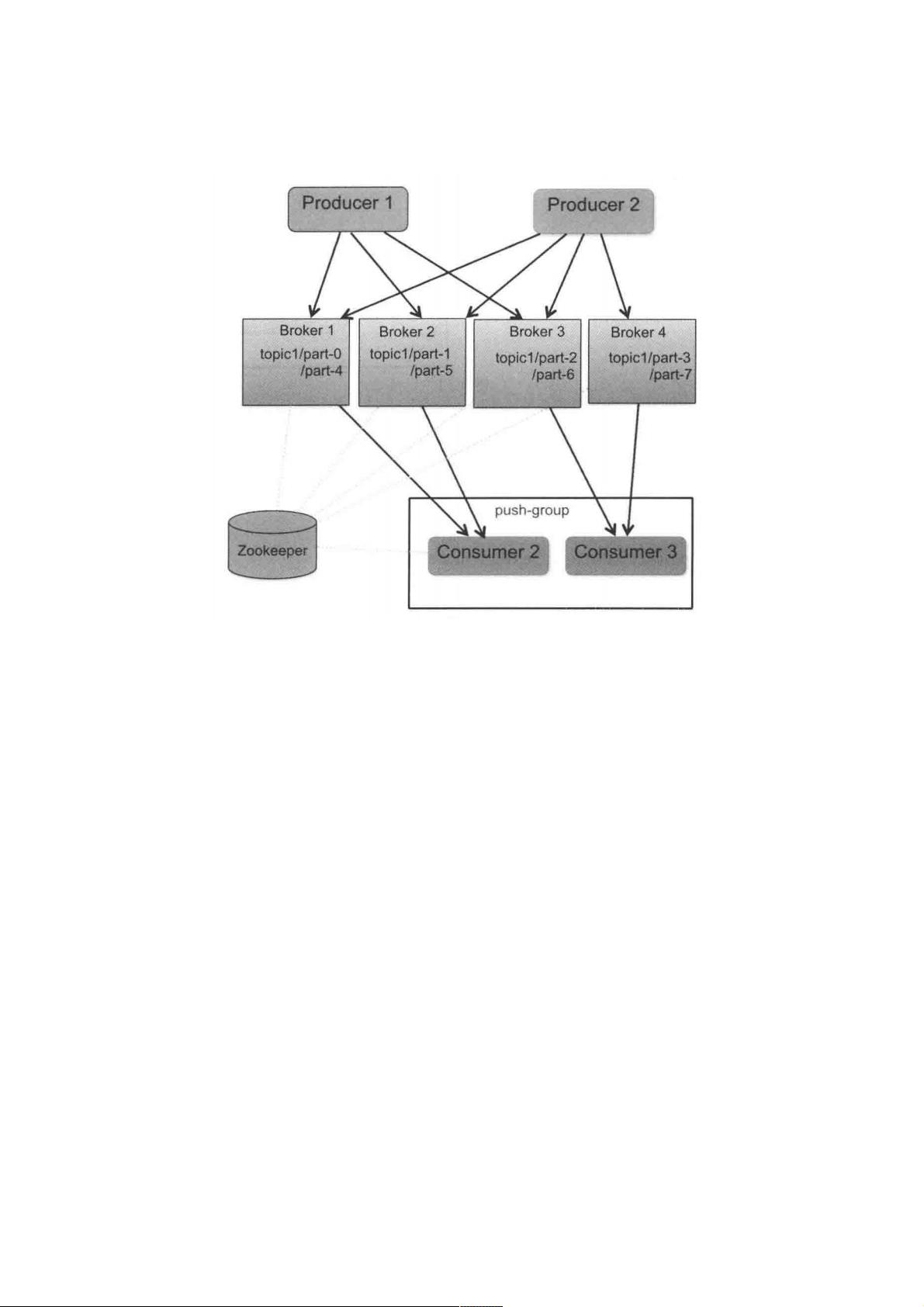
Kafka架构和原理架构和原理
Kafka架构如图:
整个架构中包括三个角色。
生产者(Producer):消息和数据生产者
代理(Broker):缓存代理,Kafka的核心功能
消费者(Consumer):消息和数据消费者
整体架构很简单,Kafka给Producer和Consumer提供注册的接口,数据从Producer发送到Broker,Broker承担一个中间缓存
和分发的作用,负责分发注册到系统中的Consumer。
设计要点
Kafka非常高效,下面介绍Kafka高效的原因,对理解Kafka非常用帮助。
直接使用Linux文件系统的Cache来高效缓存数据
采用Linux Zero-Copy提高发送性能。传统的数据发送需要发送4次上下切换,采用Sendfile系统调用之后,数据直接在内核态
交换,系统上下文切换减少为2次。可以提高60%的数据发送性能。
Kafka以Topic来进行消费管理,每个Topic包含多个Part(ition),每个Part对应一个逻辑Log,由多个Segment组成。每个
Segment中存储多条消息,消息ID由逻辑位置决定,即从消息ID可直接定位到消息的存储位置,避免ID到位置的额外映射。每
个Part在内存中对应一个Index,记录每个Segment中的第一个消息偏移。
下载后可阅读完整内容,剩余3页未读,立即下载
2022-06-09 上传
2023-07-27 上传
2023-06-26 上传
2024-04-09 上传
2024-01-10 上传
2023-06-28 上传
2024-04-11 上传
2023-06-07 上传

weixin_38528459
- 粉丝: 4
- 资源: 974
 我的内容管理
展开
我的内容管理
展开







最新资源
- C++多态实现机制详解:虚函数与早期绑定
- Java多线程与异常处理详解
- 校园导游系统:无向图实现最短路径探索
- SQL2005彻底删除指南:避免重装失败
- GTD时间管理法:提升效率与组织生活的关键
- Python进制转换全攻略:从10进制到16进制
- 商丘物流业区位优势探究:发展战略与机遇
- C语言实训:简单计算器程序设计
- Oracle SQL命令大全:用户管理、权限操作与查询
- Struts2配置详解与示例
- C#编程规范与最佳实践
- C语言面试常见问题解析
- 超声波测距技术详解:电路与程序设计
- 反激开关电源设计:UC3844与TL431优化稳压
- Cisco路由器配置全攻略
- SQLServer 2005 CTE递归教程:创建员工层级结构
