Storm编程基础:Spout组件详解
33 浏览量
更新于2024-08-27
收藏 183KB PDF 举报
"本文档介绍了Storm编程入门,主要聚焦于Spout组件的实现方式和关键方法,包括open、declareOutputFields、getComponentConfiguration以及nextTuple等。Spout是Storm拓扑中的基本组件,负责产生数据流。"
在Storm中,Spout作为数据源,是拓扑结构中的重要组成部分。它负责生成数据流并将其注入到处理管道中。实现Spout组件,开发者可以选择继承`BaseRichSpout`类或实现`IRichSpout`接口。接下来我们将详细讨论Spout的关键方法:
1. open方法:当一个Task启动时,`open`方法会被调用。在这个方法里,通常会进行初始化工作,比如初始化`SpoutOutputCollector`对象,它是用于发送Tuple的工具,以及初始化`TopologyContext`,它提供了关于拓扑结构的上下文信息。以下是一个简单的`open`方法示例:
```java
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
_collector = collector;
}
```
2. declareOutputFields方法:此方法用来声明Spout发出的Tuple所包含的字段名。通过`OutputFieldsDeclarer.declareStream`方法定义流的域名称。例如,声明一个包含字段"word"的流:
```java
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
```
这个声明对于下游bolt组件知道如何解析接收到的数据至关重要。
3. getComponentConfiguration方法:此方法位于`BaseComponent`类中,用于设置特定于当前组件的配置项。例如,可以在这里限制组件的最大并行度:
```java
public Map<String, Object> getComponentConfiguration() {
if (!_isDistributed) {
Map<String, Object> ret = new HashMap<String, Object>();
ret.put(Config.TOPOLOGY_MAX_TASK_PARALLELISM, 3);
return ret;
} else {
return null;
}
}
```
上述代码表示如果拓扑是非分布式运行,那么该组件的最大并行度设置为3。
4. nextTuple方法:这是Spout的核心方法,它负责生成并发射新的Tuple。Spout必须在适当的时间调用这个方法来产生数据。下面是一个简单的例子,模拟每100毫秒发射一个新的字符串数组:
```java
public void nextTuple() {
Utils.sleep(100);
final String[] words = new String[]{"two", "three"};
// 发射数据
_collector.emit(new Values(words));
}
```
在实际应用中,`nextTuple`方法可能与数据源(如队列、数据库或文件)交互,以拉取或接收新数据并生成相应的Tuples。
总结来说,Storm的Spout组件通过以上四个主要方法定义了其行为和数据流的结构。了解和正确实现这些方法是创建有效和高效的Storm拓扑的关键步骤。开发者可以根据具体需求,灵活选择Spout的实现方式,定制数据生成逻辑,以满足不同场景的数据处理需求。
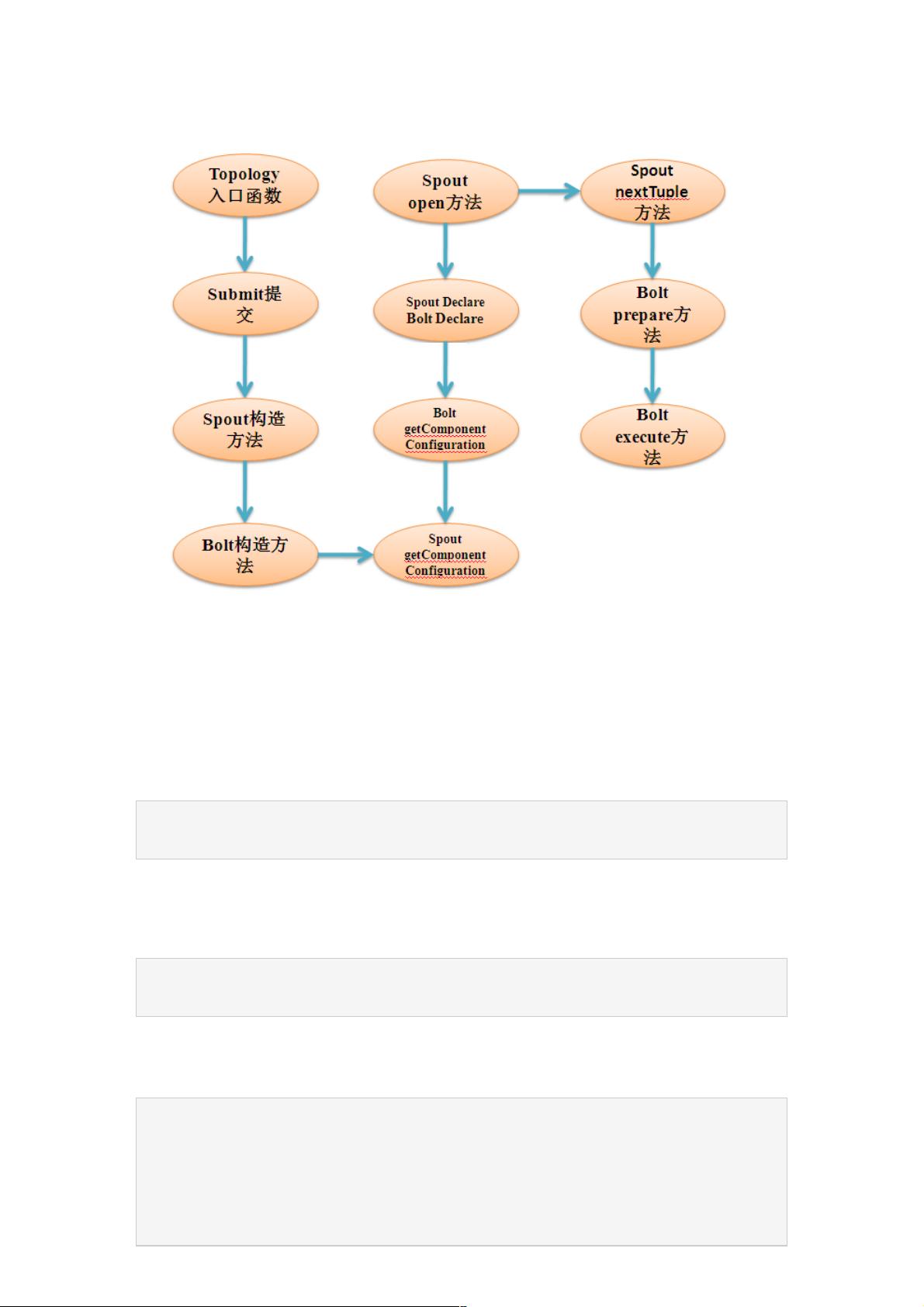
storm-编程入门编程入门
一 编程接口
Spout 接口
Spout组件的实现可以通过继承BaseRichSpout类或者其他*Spout类来完成,也可以通过实现IRichSpout接口来实现。需要根
据情况实方法有:
open方法
当一个Task被初始化的时候会调用此open方法。一般都会在此方法中对发送Tuple的对象SpoutOutputCollector和配置对象
TopologyContext初始化。示例如下:
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
_collector = collector;
}
declareOutputFields方法
此方法用于声明当前Spout的Tuple发送流的域名字。Stream流的定义是通过OutputFieldsDeclare.declareStream方法完成
的,其中参数为域名。示例如下:
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
getComponentConfiguration方法
此方法定义在BaseComponent类内,用于声明针对当前组件的特殊的Configuration配置。示例如下:
public Map<String, Object> getComponentConfiguration() {
if(!_isDistributed) {
Map<String, Object> ret = new HashMap<String, Object>();
ret.put(Config.TOPOLOGY_MAX_TASK_PARALLELISM, 3);
return ret;
} else {
return null;
}
}
下载后可阅读完整内容,剩余4页未读,立即下载
2014-12-11 上传
1046 浏览量
点击了解资源详情
2021-06-25 上传
2021-07-04 上传
2017-06-19 上传
2022-11-30 上传
点击了解资源详情
点击了解资源详情

weixin_38657835
- 粉丝: 3
- 资源: 931
 我的内容管理
展开
我的内容管理
展开







最新资源
- racebot
- 基于webpack基础构建的原生 .zip
- Excel模板大学年度課程規劃表.zip
- CVRPlus:非正式的ChilloutVR UI修改(也称为CVR +)
- CSS3鼠标悬停360度旋转效果.rar
- notes_computer_science
- crazyflie-ble:适用于 MacOSX 的 NodeJS 蓝牙 LE 客户端
- Excel模板大学年度财务收支简要表.zip
- suptv:sup suptvdotorg的正常运行时间监控器和状态页面,由@upptime提供支持
- nifi-pravega:适用于Apache NiFi的Pravega连接器
- java会议系统管理.rar
- 基于MVVM+kotlin+组件化 实现的电商实战项目.zip
- YUVplayer:从Sourceforge项目修改
- pyspqsigs:Python简单(基于哈希)的后量子签名
- visual c++vc监视目录_看哪个进程访问该目录了.zip
- ok-directory:个人和组织的开放知识目录
