HBase:大数据时代的随机访问解决方案
需积分: 5 79 浏览量
更新于2024-08-03
收藏 78KB PDF 举报
"HBase概述"
HBase是一种分布式、版本化、列族式的NoSQL数据库,设计用于在大规模数据集上提供高吞吐量和低延迟的数据访问。它运行在Hadoop分布式文件系统(HDFS)之上,充分利用了Hadoop的存储能力,并弥补了Hadoop在实时查询和随机访问上的不足。
自1970年代以来,关系型数据库管理系统(RDBMS)一直是解决数据存储和维护问题的主要工具。然而,随着大数据时代的到来,企业开始意识到处理大数据的价值,于是转向像Hadoop这样的解决方案。Hadoop通过分布式文件系统来存储大数据,并利用MapReduce进行处理。Hadoop擅长存储和处理各种格式的大量数据,包括任意的、半结构化的甚至非结构化的数据。
然而,Hadoop存在一些局限性。首先,它只能进行批量处理,这意味着数据只能按顺序访问,寻找数据时需要遍历整个数据集,即使是执行最简单的任务也是如此。其次,处理大型数据集会产生另一个大型数据集,这同样需要按顺序处理。这些情况使得在单个时间单位内对数据的随机访问成为必需。
为了解决这个问题,出现了支持Hadoop的随机访问数据库,如HBase。HBase是构建在Hadoop之上的开源数据库,它提供了一种高效、高度可扩展的方式来存储和检索大量数据。与传统的RDBMS不同,HBase不依赖于固定的表结构,而是以行键、列族、时间戳和值作为其核心数据模型。这种设计允许快速定位和读取数据,适合处理海量、稀疏的数据。
HBase的关键特性包括:
1. **分布式存储**:数据分布在多台服务器上,提供高可用性和容错性。
2. **列族存储**:数据按照列族进行组织,每个列族包含一组相关的列,可以独立地进行存储和压缩。
3. **版本化**:每个数据项都有一个时间戳,可以存储多个版本的数据,便于追踪历史变化。
4. **实时读写**:相比Hadoop的批处理,HBase支持实时的读写操作,适合在线服务和分析。
5. **水平扩展**:可以通过添加更多服务器来扩展存储和处理能力。
HBase通常用于需要实时查询和随机访问的场景,如日志分析、实时监控、物联网(IoT)数据存储等。其他类似的NoSQL数据库,如Cassandra、CouchDB、Dynamo和MongoDB,也提供了类似的功能,但每种数据库在设计和应用场景上都有其独特之处。
在选择使用HBase时,需要考虑其与传统RDBMS的权衡。例如,虽然HBase在处理大数据时性能出色,但在事务处理和复杂的SQL查询方面可能不如RDBMS。因此,根据具体业务需求和数据模式来选择合适的数据库系统至关重要。
http://www.tutorialspoint.com/hbase/hbase_overview.htm
Copyright © tutorialspoint.com
HBASE - OVERVIEW
HBASE - OVERVIEW
Since 1970, RDBMS is the solution for data storage and maintenance related problems. After the
advent of big data, companies realized the benefit of processing big data and started opting for
solutions like Hadoop.
Hadoop uses distributed file system for storing big data, and MapReduce to process it. Hadoop
excels in storing and processing of huge data of various formats such as arbitrary, semi-, or even
unstructured.
Limitations of Hadoop
Hadoop can perform only batch processing, and data will be accessed only in a sequential
manner. That means one has to search the entire dataset even for the simplest of jobs.
A huge dataset when processed results in another huge data set, which should also be processed
sequentially. At this point, a new solution is needed to access any point of data in a single unit of
time randomaccess.
Hadoop Random Access Databases
Applications such as HBase, Cassandra, couchDB, Dynamo, and MongoDB are some of the
databases that store huge amounts of data and access the data in a random manner.
What is HBase?
HBase is a distributed column-oriented database built on top of the Hadoop file system. It is an
open-source project and is horizontally scalable.
HBase is a data model that is similar to Google’s big table designed to provide quick random
access to huge amounts of structured data. It leverages the fault tolerance provided by the
Hadoop File System HDFS.
It is a part of the Hadoop ecosystem that provides random real-time read/write access to data in
the Hadoop File System.
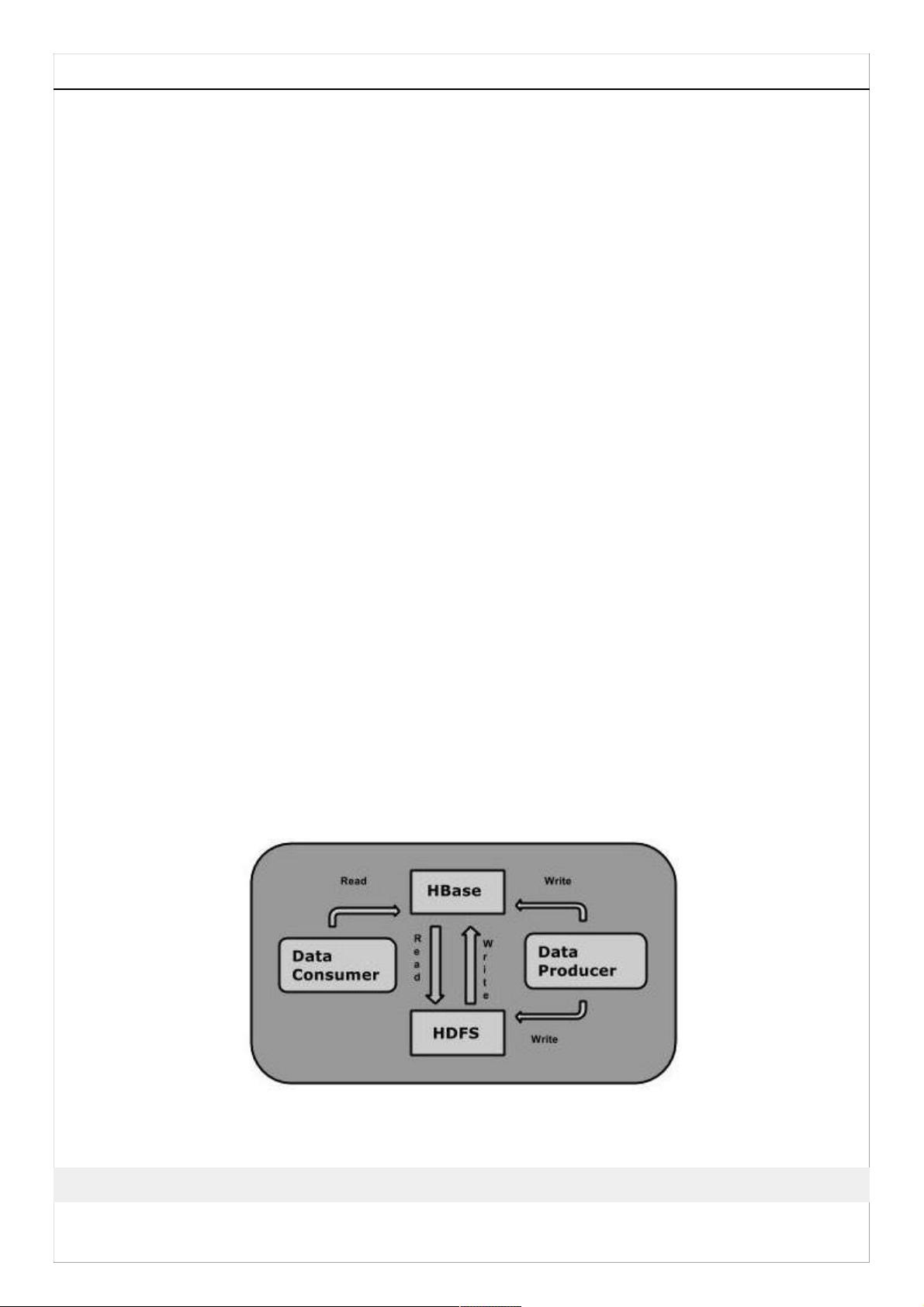
One can store the data in HDFS either directly or through HBase. Data consumer reads/accesses
the data in HDFS randomly using HBase. HBase sits on top of the Hadoop File System and provides
read and write access.
HBase and HDFS
HDFS HBase
HDFS is a distributed file system
suitable for storing large files.
HBase is a database built on top of the HDFS.
下载后可阅读完整内容,剩余3页未读,立即下载
2024-06-01 上传
2023-05-27 上传
2023-06-08 上传
2023-05-23 上传
2023-07-14 上传
2023-05-15 上传
2023-07-16 上传


大数据张老师
- 粉丝: 451
- 资源: 33
 我的内容管理
展开
我的内容管理
展开







最新资源
- WPF渲染层字符绘制原理探究及源代码解析
- 海康精简版监控软件:iVMS4200Lite版发布
- 自动化脚本在lspci-TV的应用介绍
- Chrome 81版本稳定版及匹配的chromedriver下载
- 深入解析Python推荐引擎与自然语言处理
- MATLAB数学建模算法程序包及案例数据
- Springboot人力资源管理系统:设计与功能
- STM32F4系列微控制器开发全面参考指南
- Python实现人脸识别的机器学习流程
- 基于STM32F103C8T6的HLW8032电量采集与解析方案
- Node.js高效MySQL驱动程序:mysqljs/mysql特性和配置
- 基于Python和大数据技术的电影推荐系统设计与实现
- 为ripro主题添加Live2D看板娘的后端资源教程
- 2022版PowerToys Everything插件升级,稳定运行无报错
- Map简易斗地主游戏实现方法介绍
- SJTU ICS Lab6 实验报告解析
