Python PDFMiner解析PDF文本实战指南
103 浏览量
更新于2024-09-01
收藏 90KB PDF 举报
本文将深入探讨如何在Python中利用PDFMiner库解析PDF代码,尤其是在遇到网站提供的PDF内容而非HTML时的处理策略。PDFMiner是一个专门用于处理PDF文档的Python库,它针对文本解析任务设计,相较于其他选项如pyPDF,PDFMiner被认为更为适合。
文章首先提到了PDF解析的挑战,特别是在面对格式不规范的PDF时,PDFMiner的表现可能不尽人意。然而,尽管存在这些问题,它仍然是一个强大的工具,官方文档地址是<http://www.unixuser.org/~euske/python/pdfminer/index.html>。
安装PDFMiner分为两个步骤:
1. 从PyPI下载源代码包,解压后通过命令行运行`python setup.py install`进行安装。安装成功后,可以通过运行`pdf2txt.py samples/simple1.pdf`来验证,如果输出为连续的"HelloWorld"则说明安装正确。
2. 对于包含中日韩字符的PDF,安装前需执行额外的编译步骤,包括`make cmap`和再次运行`python setup.py install`。
在实际使用中,PDFMiner的效率优化体现在其采用lazyparsing策略,即在需要时才解析PDF内容,以减少内存占用和提升性能。核心的使用涉及三个类:PDFParser、PDFDocument和PDFPageInterpreter。PDFParser负责从PDF文件中抽取数据,PDFDocument用于存储数据,而PDFPageInterpreter则用于解释页面内容,这通常涉及到逐页处理,并可能涉及到文本提取、布局分析等操作。
在编写代码时,开发者需要导入必要的模块,例如`from pdfminer.converter import TextConverter`,`from pdfminer.layout import LAParams`,然后创建PDF文档对象和解析器对象,接着对每个页面进行解析,最后可能还需要处理转换得到的文本数据,比如去除无关空白或进行特定格式的清洗。
Python使用PDFMiner解析PDF代码是一个复杂但实用的过程,需要熟悉库的特性和工作原理,同时应对各种PDF格式的差异性。通过本文提供的实例和步骤,读者可以更好地理解和应用PDFMiner进行PDF内容的自动化处理。
Python使用使用PDFMiner解析解析PDF代码实例代码实例
本篇文章主要介绍了Python使用PDFMiner解析PDF代码实例,小编觉得挺不错的,现在分享给大家,也给大家做个参考。一起跟随小编过来看
看吧
近期在做爬虫时有时会遇到网站只提供pdf的情况,这样就不能使用scrapy直接抓取页面内容了,只能通过解析PDF的方式处理,目前的解决方案大致只有pyPDF
和PDFMiner。因为据说PDFMiner更适合文本的解析,而我需要解析的正是文本,因此最后选择使用PDFMiner(这也就意味着我对pyPDF一无所知了)。
首先说明的是解析PDF是非常蛋疼的事,即使是PDFMiner对于格式不工整的PDF解析效果也不怎么样,所以连PDFMiner的开发者都吐槽PDF is evil. 不过这些并
不重要。官方文档在此:http://www.unixuser.org/~euske/python/pdfminer/index.html
一一.安装:安装:
1.首先下载源文件包 http://pypi.python.org/pypi/pdfminer/,解压,然后命令行安装即可:python setup.py install
2.安装完成后使用该命令行测试:pdf2txt.py samples/simple1.pdf,如果显示以下内容则表示安装成功:
Hello World Hello World H e l l o W o r l d H e l l o W o r l d
3.如果要使用中日韩文字则需要先编译再安装:
# make cmap
python tools/conv_cmap.py pdfminer/cmap Adobe-CNS1 cmaprsrc/cid2code_Adobe_CNS1.txtreading 'cmaprsrc/cid2code_Adobe_CNS1.txt'...writing 'CNS1_H.py'......(this may take several minutes)
# python setup.py install
二.使用二.使用
由于解析PDF是一件非常耗时和内存的工作,因此PDFMiner使用了一种称作lazy parsing的策略,只在需要的时候才去解析,以减少时间和内存的使用。要解析
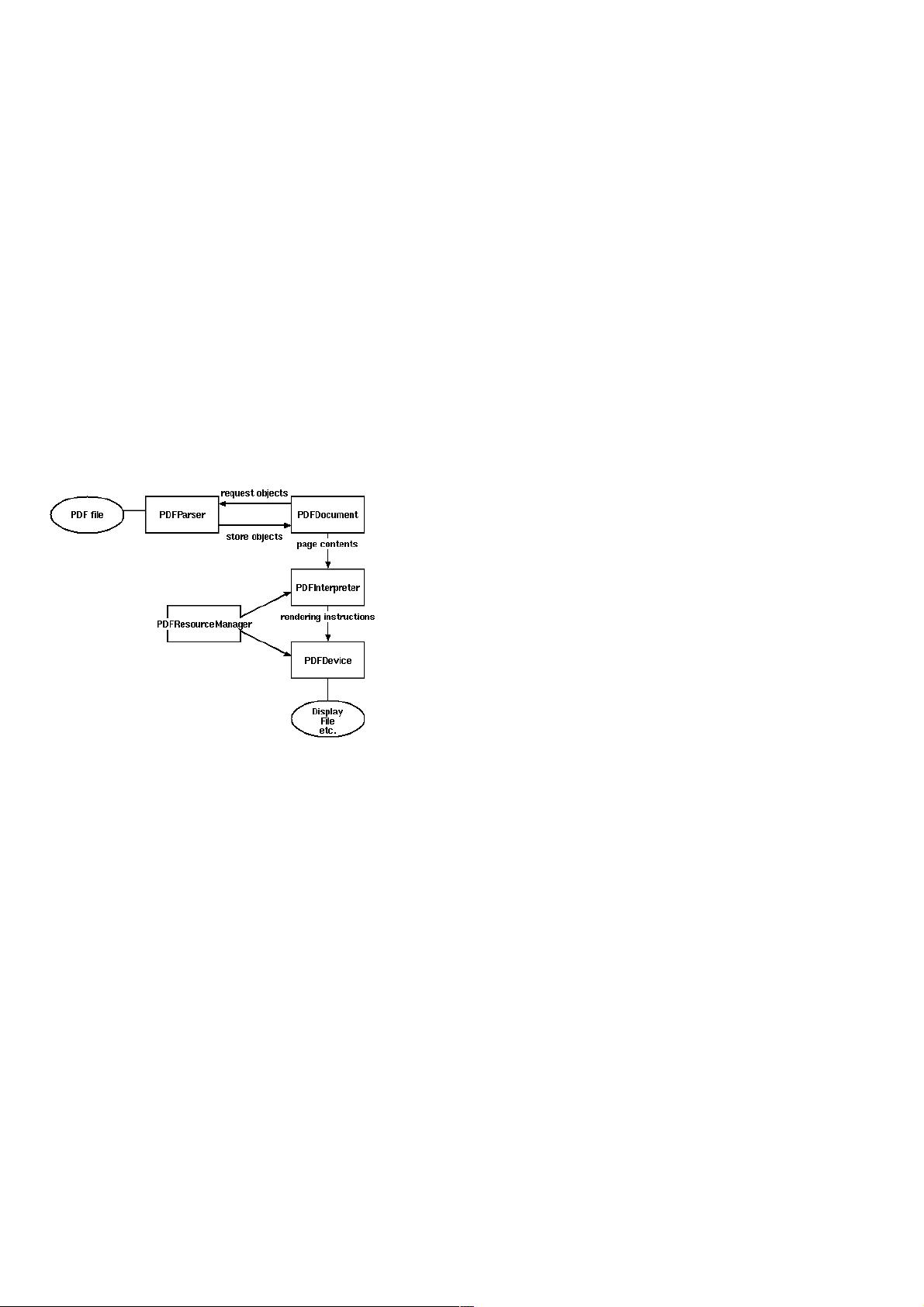
PDF至少需要两个类:PDFParser 和 PDFDocument,PDFParser 从文件中提取数据,PDFDocument保存数据。另外还需要PDFPageInterpreter去处理页面内
容,PDFDevice将其转换为我们所需要的。PDFResourceManager用于保存共享内容例如字体或图片。
Figure 1. Relationships between PDFMiner classes
比较重要的是Layout,主要包括以下这些组件:
LTPage
Represents an entire page. May contain child objects like LTTextBox, LTFigure, LTImage, LTRect, LTCurve and LTLine.
LTTextBox
Represents a group of text chunks that can be contained in a rectangular area. Note that this box is created by geometric analysis and does not necessarily
represents a logical boundary of the text. It contains a list of LTTextLine objects. get_text() method returns the text content.
LTTextLine
Contains a list of LTChar objects that represent a single text line. The characters are aligned either horizontaly or vertically, depending on the text's writing
mode. get_text() method returns the text content.
LTChar
LTAnno
Represent an actual letter in the text as a Unicode string. Note that, while a LTChar object has actual boundaries, LTAnno objects does not, as these are
"virtual" characters, inserted by a layout analyzer according to the relationship between two characters (e.g. a space).
LTFigure
Represents an area used by PDF Form objects. PDF Forms can be used to present figures or pictures by embedding yet another PDF document within a page.
Note that LTFigure objects can appear recursively.
LTImage
Represents an image object. Embedded images can be in JPEG or other formats, but currently PDFMiner does not pay much attention to graphical objects.
LTLine
Represents a single straight line. Could be used for separating text or figures.
LTRect
下载后可阅读完整内容,剩余3页未读,立即下载
2020-09-19 上传
2017-08-21 上传
2023-05-27 上传
2023-05-28 上传
2023-05-20 上传
2023-05-27 上传
2023-08-06 上传
2023-09-02 上传
2023-06-06 上传

weixin_38723691
- 粉丝: 3
- 资源: 940
 我的内容管理
展开
我的内容管理
展开







最新资源
- C++多态实现机制详解:虚函数与早期绑定
- Java多线程与异常处理详解
- 校园导游系统:无向图实现最短路径探索
- SQL2005彻底删除指南:避免重装失败
- GTD时间管理法:提升效率与组织生活的关键
- Python进制转换全攻略:从10进制到16进制
- 商丘物流业区位优势探究:发展战略与机遇
- C语言实训:简单计算器程序设计
- Oracle SQL命令大全:用户管理、权限操作与查询
- Struts2配置详解与示例
- C#编程规范与最佳实践
- C语言面试常见问题解析
- 超声波测距技术详解:电路与程序设计
- 反激开关电源设计:UC3844与TL431优化稳压
- Cisco路由器配置全攻略
- SQLServer 2005 CTE递归教程:创建员工层级结构
