PyCharm中调试Scrapy爬虫的详细步骤
145 浏览量
更新于2024-08-29
收藏 772KB PDF 举报
本文档详细介绍了如何在PyCharm环境下操作Scrapy爬虫项目的创建、配置以及调试过程。首先,你需要创建一个新的Scrapy项目,比如名为"test1",并在桌面上进行。在项目目录下,使用命令行工具scrapy startproject创建项目。
步骤1-3:打开PyCharm,选择"Open"选项,然后选择项目文件夹,确认后你会看到项目面板(alt+1)。
步骤4-5:在spiders文件夹下创建一个新的爬虫文件spider.py,确保其包含一个名为"name='dmoz'"的定义,这将用于后续的引用。
步骤6:在项目根目录与scrapy.cfg同一级位置创建一个名为begin.py(或main.py)的启动脚本,此脚本导入scrapy并调用crawldmoz命令,确保此处的名字与spider.py中的一致。
步骤7:配置PyCharm以运行爬虫。在Run菜单中选择"Edit Configurations",新建一个Python模块运行配置,名称设为"spider",脚本选择begin.py,并指定工作目录。
步骤8:完成配置后,可以直接点击运行按钮执行爬虫。如果你想要进行调试,可以在代码中设置断点,然后通过点击右上角的运行按钮进行debug运行。
问题与解决:
- 如果遇到"Unknown command: crawl"错误,这可能是由于Scrapy命令未被正确识别。检查你的脚本是否正确引用了scrapy模块,并确保Scrapy环境变量设置正确。
- 调试时,如果断点没有触发,查看控制台输出,如"pydevdebugger:process4740 is connecting",表明连接到调试器。确保你的PyCharm配置的调试参数与实际执行的Python版本一致。
总结,本文提供了从创建Scrapy项目到在PyCharm中设置并调试爬虫的完整流程,包括项目结构管理、脚本编写以及调试工具的使用,有助于提高Scrapy爬虫开发的效率和问题排查能力。
pycharm下打开、执行并调试下打开、执行并调试scrapy爬虫程序的方法爬虫程序的方法
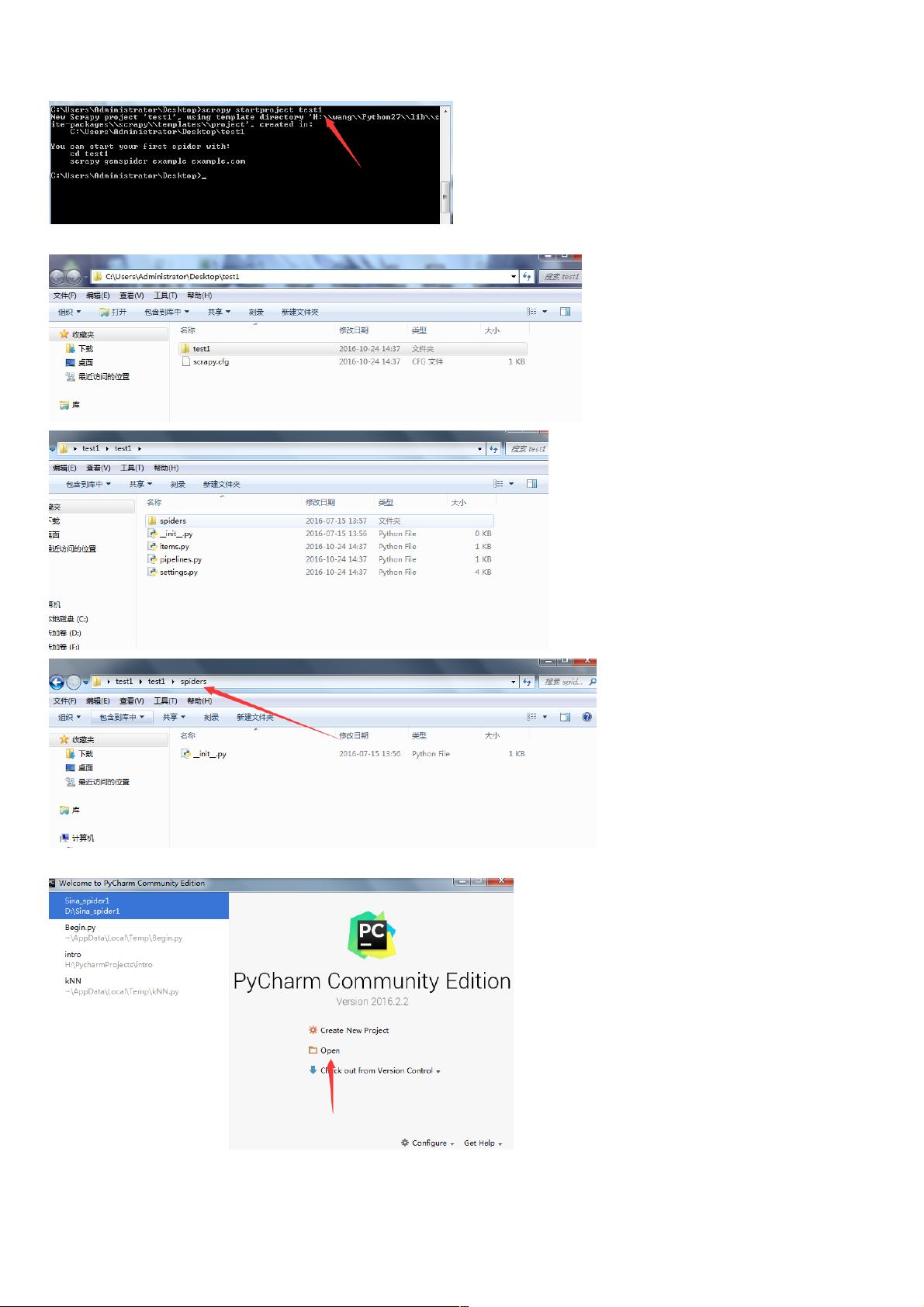
首先得有一个Scrapy项目,我在Desktop上新建一个Scrapy的项目叫test,在Desktop目录打开命令行,键入命令:scrapy startproject test1
目录结构如下:
打开Pycharm,选择open
选择项目,ok
下载后可阅读完整内容,剩余4页未读,立即下载
543 浏览量
455 浏览量
440 浏览量
532 浏览量
503 浏览量
291 浏览量
2025-01-18 上传
2024-09-27 上传
503 浏览量

weixin_38556985
- 粉丝: 3
 我的内容管理
展开
我的内容管理
展开







最新资源
- 安装Oracle必备:unixODBC-2.2.11-7.1.x86_64.rpm
- Spring Boot与Camel XML聚合快速入门教程
- React开发新工具:可拖动、可调整大小的窗口组件
- vlfeat-0.9.14 图像处理库深度解析
- Selenium自动化测试工具深度解析
- ASP.NET房产中介系统:房源信息发布与查询平台
- SuperScan4.1扫描工具深度解析
- 深入解析dede 3.5 Delphi反编译技术
- 深入理解ARM体系结构及编程技巧
- TcpEngine_0_8_0:网络协议模拟与单元测试工具
- Java EE实践项目:在线商城系统演示
- 打造苹果风格的Android ListView实现与下拉刷新
- 黑色质感个人徒步旅行HTML5项目源代码包
- Nuxt.js集成Vuetify模块教程
- ASP.NET+SQL多媒体教室管理系统设计实现
- 西北工业大学嵌入式系统课程PPT汇总
