Apache Kylin在马蜂窝数据分析中的实践与价值
102 浏览量
更新于2024-08-28
收藏 1.48MB PDF 举报
"Apache Kylin在马蜂窝数据分析团队的应用实战"
Apache Kylin是Apache软件基金会的一个开源项目,它是一款高性能的、分布式的在线分析处理(OLAP)系统,专为大规模数据集设计,旨在提供亚秒级的查询响应时间。在马蜂窝的数据分析团队中,Kylin扮演了关键角色,使数据分析师能够更加高效地处理和分析大量业务数据。
传统的数据团队架构通常将数据分析团队定位为数据平台的使用者,依赖于数据工程师提取和准备数据。然而,这种模式在面对快速变化且复杂的业务需求时,可能会造成沟通障碍、项目周期延长以及理解不一致等问题。马蜂窝的业务涵盖了旅游行业的多个方面,从社区、攻略到酒店和电商平台,这种多元化和快速发展的业务模式需要更加敏捷和灵活的数据处理解决方案。
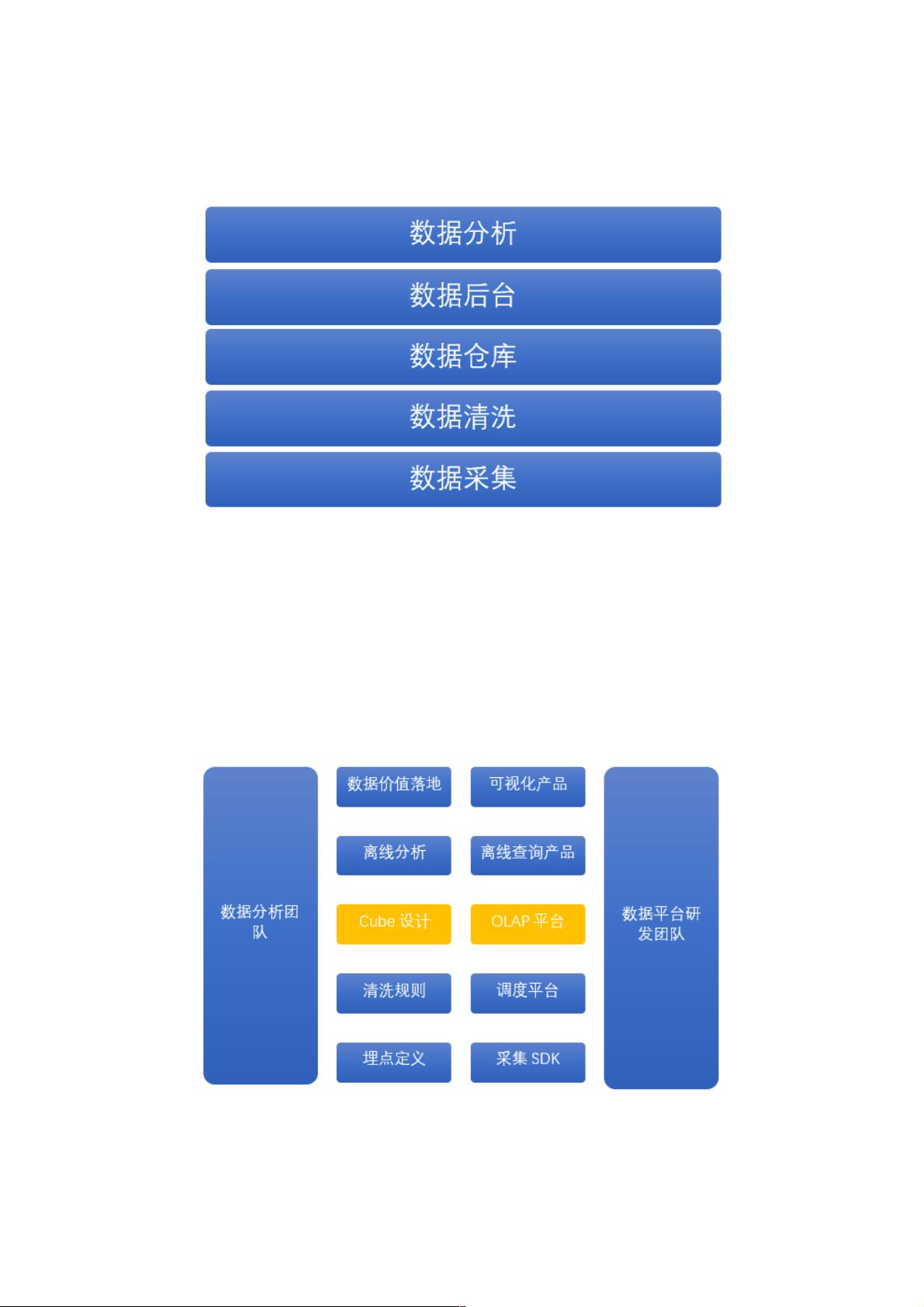
Kylin的引入改变了这一局面。它不仅提供了高效的数据预处理和存储能力,还通过其易于使用的接口,让数据分析师可以直接参与到数据仓库的设计和实现过程中,成为数据全生命周期的管理者。这样,数据分析师可以更好地理解和控制数据,从数据的源头(如数据埋点定义和清洗规则设定)到最终的分析和应用(如离线分析、看板配置和API输出)都能进行端到端的管理。
Kylin作为一款成熟的大数据技术,其优势在于能够处理PB级别的数据,并支持多维分析和复杂查询,同时保持低延迟。通过在数据平台上进行产品化集成,Kylin使得非数据开发人员也能轻松使用,提升了团队协作效率,降低了数据项目的实施难度。这种转变让数据平台团队从单纯的开发者角色转变为平台设计者和实现者,而数据分析师则从被动的使用者转变为积极的参与者和建设者。
Apache Kylin在马蜂窝的应用实战展示了大数据技术如何在实际业务环境中提升数据分析的效率和质量,以及如何通过技术赋能,改变数据团队的工作模式,适应快速变化的业务需求。通过数据平台的开放共建,马蜂窝实现了数据价值的最大化,同时也优化了数据分析流程,确保了数据的准确性和时效性。
Kylin在马蜂窝数据分析团队的应用实战在马蜂窝数据分析团队的应用实战
为什么 Apache Kylin 是分析师的标配技能
说到 Apache Kylin(以下简称 Kylin),对于做大数据开发,尤其是数据仓库开发的同学,即使没用过,至少一定或多或少听
过,但对于数据分析师而言,可能不一定十分熟悉,在马蜂窝,利用 Kylin,自己动手搭建所负责业务的数据仓库,已经成为
数据分析师日常工作的一部分,是分析师的标配技能。
传统的根据数据流进行分层的数据团队组织架构中,数据分析团队大多是作为数据平台的使用者,通过各种数据后台,提取数
据进行分析工作,这更多是沿用了大数据技术兴起前的组织架构。
从业务角度看:随着业务复杂性及业务发展速度越来越快,尤其是马蜂窝的业务从最初的社区、到攻略、再到近两年逐渐发力
的酒店和电商平台等商业化业务线,涉及用户旅行的行前、行中、行后的所有环节,做整个旅游行业的闭环。马蜂窝内部更像
是一个集团公司,各个团队间的业务情况、数据需求及发展阶段有很大不同,结合自身业务的复杂性,传统的按部就班,层层
堆叠的组织结构和做事方式,已经不足以适应当下的业务发展要求。
从数据分析角度来看,由于组织结构的分层,也往往容易出现踢皮球,数据项目周期拉长,甚至因层层传递导致的理解偏差,
所带来的潜在问题等。
从技术角度看:随着 Kylin 等相关大数据技术的日趋成熟,各公司数据架构大同小异,重心已从从基本架构和功能实现,逐渐
变为如何充分吸收各种大数据相关技术,如何充分发挥技术与数据的价值。
通过数据平台产品化,赋能给数据分析师为代表的非数据开发小伙伴,共同进行数据平台建设。
作为研发为主的数据平台团队,由封闭的数据流的开发者,转为开放的数据平台产品的设计与实现者,充分将数据流各环节产
品化,将环节中的的数据与技术能力通过数据产品开放出来,允许分析师等数据使用者加入进来,开放共建平台。
作为对接数据与业务的主力军,数据分析师从一个最上层的数据使用者,转变为数据全生命周期的管理者和建设者,能够对数
据做到端到端的把控,一头控制数据源头,一头控制数据需求,中间通过数据平台各个产品自助完成数据流,职责覆盖数据埋
点定义、清洗规则设立,数据仓库设计与实现,离线分析、看板配置,API 输出、推动数据项目落地等。
下载后可阅读完整内容,剩余6页未读,立即下载
2019-07-18 上传
2018-10-11 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
2023-03-16 上传
2023-08-17 上传
2023-08-15 上传

weixin_38633083
- 粉丝: 0
- 资源: 896
 我的内容管理
展开
我的内容管理
展开







最新资源
- C++标准程序库:权威指南
- Java解惑:奇数判断误区与改进方法
- C++编程必读:20种设计模式详解与实战
- LM3S8962微控制器数据手册
- 51单片机C语言实战教程:从入门到精通
- Spring3.0权威指南:JavaEE6实战
- Win32多线程程序设计详解
- Lucene2.9.1开发全攻略:从环境配置到索引创建
- 内存虚拟硬盘技术:提升电脑速度的秘密武器
- Java操作数据库:保存与显示图片到数据库及页面
- ISO14001:2004环境管理体系要求详解
- ShopExV4.8二次开发详解
- 企业形象与产品推广一站式网站建设技术方案揭秘
- Shopex二次开发:触发器与控制器重定向技术详解
- FPGA开发实战指南:创新设计与进阶技巧
- ShopExV4.8二次开发入门:解决升级问题与功能扩展
