百度Palo分析型数据库:应用实践与技术解析
需积分: 10 36 浏览量
更新于2024-07-21
1
收藏 11.51MB PDF 举报
"Palo分析型数据库在百度内的应用实践——马如悦2015.11"
在SDCC2015大会上,百度的马如悦分享了Palo分析型数据库在百度内部的应用实践。Palo数据库是百度自主研发的第三代在线分析处理(OLAP)系统,其名称来源于OLAP的缩写,主要用于处理大规模结构化数据的快速分析。
背景介绍:
在大数据背景下,数据处理通常遵循Lambda Architecture,包括批处理层(如Hadoop、Spark)、实时处理层(如Dstream、TM)以及服务层。Palo则主要服务于在线数据服务(Online Data Serving)部分,提供实时和预计算视图,以满足对所有数据的实时和批量查询需求。
Palo的特点与优势:
1. **简单查询引擎与存储引擎**:Palo设计了针对不同查询需求的引擎,包括键值存储引擎(KVStorageEngine)用于简单查询,表存储引擎(TableStorageEngine)用于分析/OLAP查询,以及文档存储引擎(DocumentStorageEngine)用于搜索查询。
2. **面向大规模数据分析**:Palo专注于处理百TB到PB级别的结构化数据,提供毫秒至秒级的分析速度。
3. **自研三代产品**:从Doris、OlapEngine发展到Palo,它在百度内部有超过120条产品线在使用,涉及500多台服务器,单个业务最大可达百TB数据。
4. **OLAP与OLTP的对比**:OLAP系统与传统的在线事务处理(OLTP)系统不同,OLTP关注日常交易处理和简单的明细查询,而OLAP则面向复杂的聚合查询和大量数据分析。OLAP系统处理的是历史数据,数据规模大,且数据更新方式为批量更新,数据组织采用反范式和星型模型,以优化分析性能。
Palo的定位与特性:
1. **低成本**:Palo设计的目标是实现低成本的高性能分析,通过线性扩展来降低成本。
2. **支持云化部署**:能够适应云环境,提供灵活的部署方案。
3. **高可用**:保证99.9999%的高可用性,可处理10WQPS(每秒查询数)和100GB/s的数据吞吐量。
4. **高扩展性**:支持100~200节点的集群,可管理1000TB的数据。
5. **高加载性能**:具备每小时处理10TB数据的高效加载能力。
在实际应用中,Palo广泛应用于在线报表、多维分析以及商业产品的数据支持,帮助百度各个业务线进行实时和深度的数据洞察,提升决策效率。
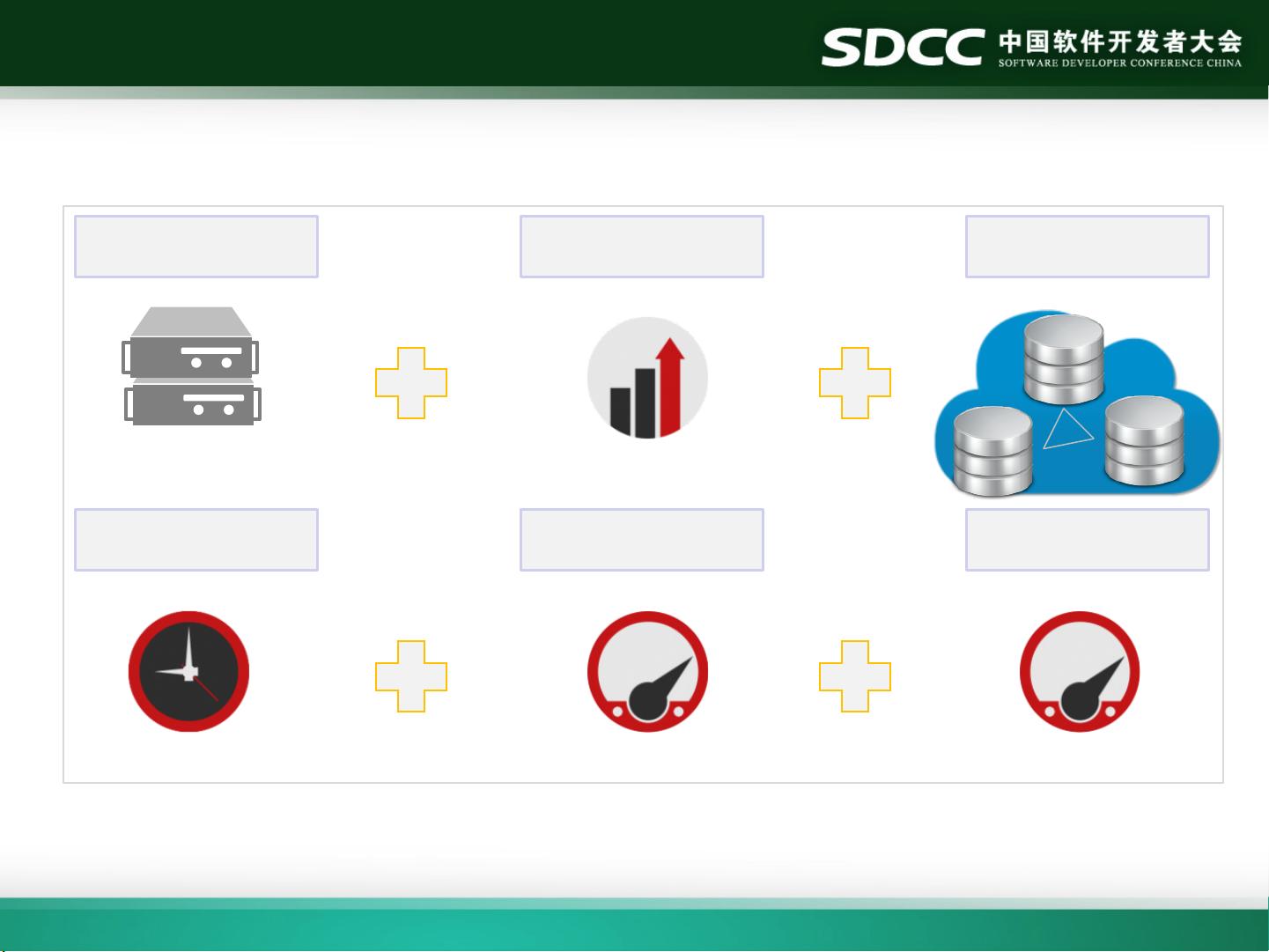
Palo定位
低成本 线性扩展 支持云化部署
高可用 高查询性能
99.9999 % Uptime 10W QPS/ 100GB/s
100~200节点 / 1000 TB 1/10 ~1/100 Cost
高加载性能
10 TB / Hour
剩余40页未读,继续阅读
2016-07-27 上传
2022-03-18 上传
2022-03-04 上传
2024-03-07 上传
2018-03-23 上传
2018-06-07 上传
2018-05-09 上传

瞠目结舌2
- 粉丝: 62
- 资源: 8
 我的内容管理
展开
我的内容管理
展开







最新资源
- Fisher Iris Setosa数据的主成分分析及可视化- Matlab实现
- 深入理解JavaScript类与面向对象编程
- Argspect-0.0.1版本Python包发布与使用说明
- OpenNetAdmin v09.07.15 PHP项目源码下载
- 掌握Node.js: 构建高性能Web服务器与应用程序
- Matlab矢量绘图工具:polarG函数使用详解
- 实现Vue.js中PDF文件的签名显示功能
- 开源项目PSPSolver:资源约束调度问题求解器库
- 探索vwru系统:大众的虚拟现实招聘平台
- 深入理解cJSON:案例与源文件解析
- 多边形扩展算法在MATLAB中的应用与实现
- 用React类组件创建迷你待办事项列表指南
- Python库setuptools-58.5.3助力高效开发
- fmfiles工具:在MATLAB中查找丢失文件并列出错误
- 老枪二级域名系统PHP源码简易版发布
- 探索DOSGUI开源库:C/C++图形界面开发新篇章
