大规模生产系统中硬件故障的深度分析与改进建议
35 浏览量
更新于2024-06-19
收藏 883KB PDF 举报
大规模故障缓慢:大型生产系统中硬件性能故障的研究与建议
这篇论文发表于ACM Transactions on Storage第143卷的第二十三篇文章,发表于2018年10月。它深入探讨了在大型生产系统中广泛存在的一个鲜为人知的问题——硬件性能故障的“慢故障”现象。作者哈雅迪·古纳维河、Rizao·苏明托、Rusell Sears、Casey Golliher等人来自多个知名机构,如芝加哥大学、PureStorage、华为、Nutanix、IBM等,以及美国洛斯阿拉莫斯和阿贡国家实验室的研究人员,共同对114个大规模集群中的故障案例进行了详尽分析。
研究发现,各种硬件组件,包括硬盘、固态硬盘(SSD)、CPU、内存和网络设备,都可能出现性能故障的缓慢显现。这一现象被称为“故障缓慢”,不同于常见的突发故障。研究者注意到故障形式会随着时间而转变,导致故障的影响可能持续很长时间,且故障表现可能多种多样,如抖动和limpware(软弱的软件)现象。
值得注意的是,故障的级联效应往往有其深层次的根源,这对系统设计和运维提出了新的挑战。作者强调,对于供应商、数据中心运营商和系统设计师来说,理解并应对这种故障模式至关重要。他们提出的建议旨在帮助改进硬件设计、故障预测和预防策略,以及优化系统的容错能力和实时性。
论文还提到了研究的资金支持,包括来自美国国家科学基金会(NSF)的多项目资助(CCF-1336580、CNS-1350499、CNS-1526304和CNS-1563956)以及美国能源部科学办公室的用户设施支持(合同编号DE-AC02-06CH11357)。
这篇论文通过对大规模硬件性能故障的深入剖析,揭示了一个重要的技术问题,为IT行业的发展提供了有价值的洞见和实践指导。对于那些关注系统稳定性和性能优化的专业人士而言,这是一篇不可忽视的重要参考资料。
大规模故障缓慢:大型生产系统中硬件性能故障的证据23:
5
ACM Transactions on Storage,Vol.号143、第二十三条。出版日期:2018年10月
表
3.
不同硬件类型
硬件类型
根
SSD
磁盘
Mem
净
CPU
总
ERR
FW
11
7
10
3
11
0
10
9
3
2
45
21
TEMP
PWR
ENVC
ONF
1
1
3
1
3
0
5
1
0
1
2
0
2
0
5
5
6
6
5
3
12
8
20
10
UNK
0
4
1
2
2
9
总
24
26
15
33
27
125
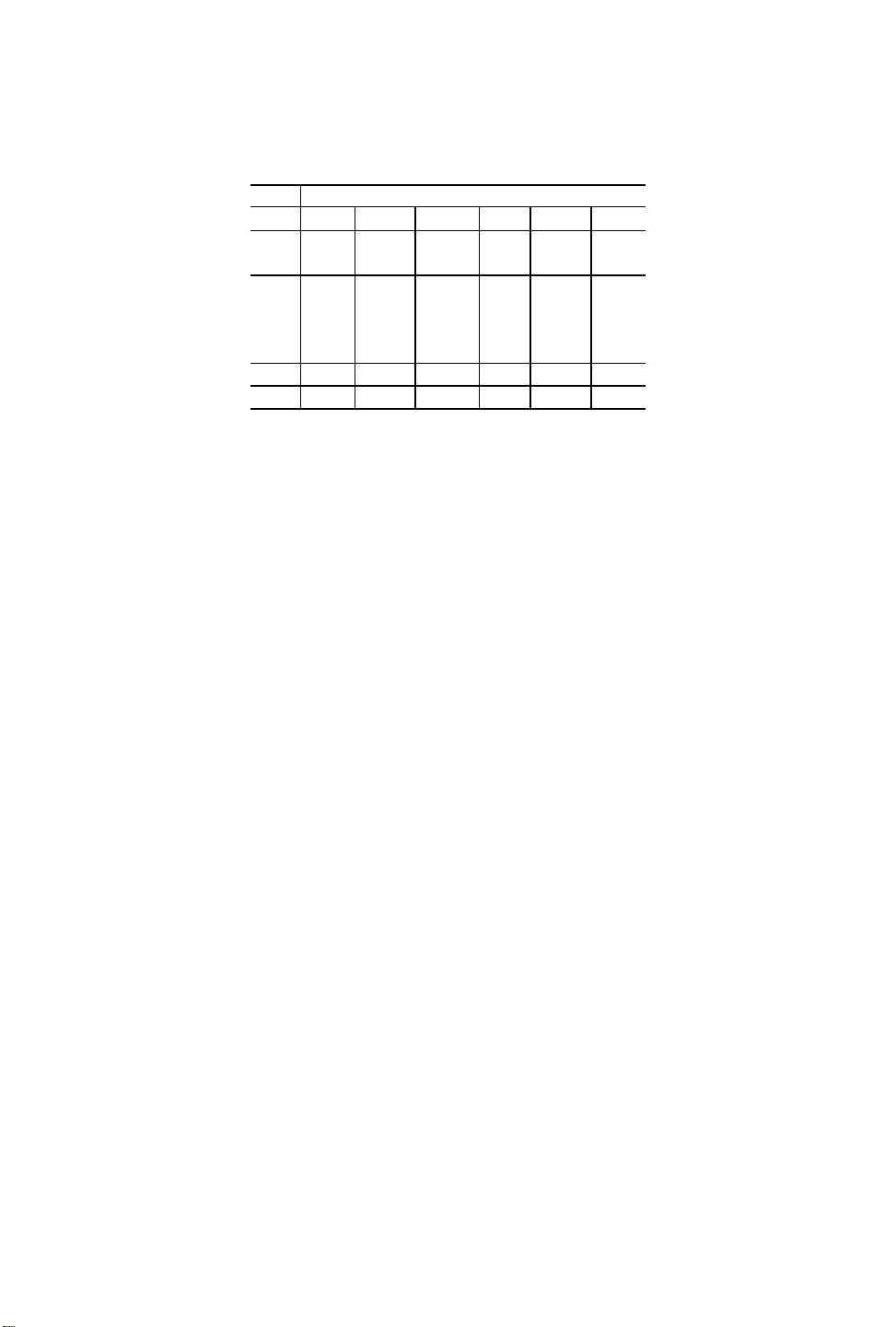
该表显示了不同硬件类型的根本原因的发生率。例如,
在第一 行 和 第一列 中 ,有11个由于 内 部设备错 误或
Wwearouts(ERR)而导致的故障慢SSD。该表参见第3.1
节。 硬 件
类 型 是 SSD 、 磁盘 、 存 储 器(
“Mem”)、网络
(“Net”)和处理器(“CPU”)
。
内部根本原因是设备错误
( ERR )
和 固 件 问 题 ( FW ) , 外 部 根 本 原 因 是 温 度
( TEMP ) 、 电 源 ( PWR ) 、 环 境 ( ENV ) 和 配 置
(CONF)。标记为未知(UNK)的问题意味着操作人员
无法查明根本原因,而只是更换了硬件。请注意,一份
报告可能有多个根本原因(环境和电源/温度问题),因
此总数(125)大于114份报告。
系统此外,一个强大的故障停止容错系统应确保故障停止故障不会转换为故障
慢。
故障
-
瞬时到故障
-
慢:
除了故障-停止,许多种类的硬件可以表现出故障-瞬时错误;例
如,磁盘偶尔返回IO错误,处理器有时产生错误的
结果
,并且不时地
存储器
位被损
坏。
由于
其
瞬态
和
“随机“性质,固件/软件通常对用户屏蔽这些错误
。一种简单的机制是
重试
操作或
修复
错误(例如,ECC或奇偶校验)。然而,当瞬时故障更频繁地发生
时
,错误请求
可能
成为
“
双端工作
”
。
也
就是说,
由于错误掩蔽不是自由操作(例如,重
试延迟、修复成本),当错误并不罕见时,掩码开销成为影响常见情况性能的最大开
销。
我们观察到许多情况下,故障瞬态到故障慢转换。例如,磁盘固件触发了严重
风险中的“写后重新加载”检查;由于许多DRAM位翻转
的
ECC校正量
很
大,机器被
认为无法工作;我们收到了许多DRAM的现场报告,显示出高错误率,因此ECC修
复延迟成为常见情况;松散的PCIe连接使驱动程序多次重试IO;以及许多丢失/损坏网
络数据包的情况(在我们的报告中,比率在1%到50%之间)触发了大量重试,导
致网络吞吐量下降了几个
从上面的故事中,很明显,必须区分罕见和频繁的故障-瞬时故障。虽然屏蔽前
者是可以接受的,但后者应该暴露于而不是隐藏于高级软件堆栈和监控工具。
部分故障到慢故障:
某些硬件也可能出现部分故障,其中只有设备的某个部分不
可用(即,部分故障停止)。这种故障通常由固件/软件层(例如,重新映射)。
然而,当部分失效的规模增大时,

剩余25页未读,继续阅读
2021-06-05 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

cpongm
- 粉丝: 5
- 资源: 2万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- 构建基于Django和Stripe的SaaS应用教程
- Symfony2框架打造的RESTful问答系统icare-server
- 蓝桥杯Python试题解析与答案题库
- Go语言实现NWA到WAV文件格式转换工具
- 基于Django的医患管理系统应用
- Jenkins工作流插件开发指南:支持Workflow Python模块
- Java红酒网站项目源码解析与系统开源介绍
- Underworld Exporter资产定义文件详解
- Java版Crash Bandicoot资源库:逆向工程与源码分享
- Spring Boot Starter 自动IP计数功能实现指南
- 我的世界牛顿物理学模组深入解析
- STM32单片机工程创建详解与模板应用
- GDG堪萨斯城代码实验室:离子与火力基地示例应用
- Android Capstone项目:实现Potlatch服务器与OAuth2.0认证
- Cbit类:简化计算封装与异步任务处理
- Java8兼容的FullContact API Java客户端库介绍
