HDFS数据完整性保卫战:专家级故障排查与性能优化实战手册
发布时间: 2024-10-29 19:13:27 阅读量: 5 订阅数: 10 

# 1. HDFS数据完整性的基础知识
## HDFS数据完整性的概念
Hadoop分布式文件系统(HDFS)作为大数据存储的核心组件,其数据完整性对于保证数据的准确性和可靠性至关重要。HDFS提供了多层数据完整性保护机制,从数据写入、存储到读取的各个阶段,都进行了严格的数据校验。
## HDFS数据完整性的重要性
数据完整性意味着数据在传输和存储过程中未被篡改、损坏或丢失。在大数据处理中,数据完整性保障了数据分析和挖掘的有效性和正确性。HDFS通过校验和(Checksum)机制来维护数据块(Block)的完整性,确保数据的准确性。
## HDFS数据完整性的校验方法
HDFS支持以下几种校验方法来检测数据块的完整性:
- **块校验和**:HDFS为每个数据块计算校验和,并存储在NameNode的元数据中。客户端读取数据时会重新计算校验和,并与元数据中的值进行比对。
- **数据节点心跳**:DataNode会定期向NameNode发送心跳包,报告自身状态和数据块的校验和信息。
- **副本一致性**:HDFS通过副本机制保障数据冗余,定期检查副本之间的一致性。
数据完整性不仅是HDFS数据存储的基本要求,也是大数据分析准确性的先决条件。在下一章中,我们将深入探讨HDFS数据完整性检查的实践技巧。
# 2. HDFS数据完整性检查的实践技巧
## 2.1 HDFS数据完整性检查的理论基础
### 2.1.1 HDFS数据完整性检查的原理
HDFS(Hadoop Distributed File System)是Hadoop项目的核心组件,它为大规模数据集提供存储。HDFS设计成能够可靠地存储巨量数据,并支持快速数据访问,这对于分布式计算环境至关重要。数据完整性是指数据在传输和存储过程中保持正确、未被篡改和未损坏的特性。HDFS通过以下几个机制确保数据的完整性:
1. **数据块校验和(Checksum)**:HDFS将文件分割成固定大小的数据块(默认为128MB),并为每个数据块计算校验和。校验和存储在与数据块相同的DataNode上,但不与数据块本身保存在一起,以便于快速校验。当客户端读取数据块时,它会重新计算校验和,并与存储的校验和进行比对,以验证数据块的完整性。
2. **冗余存储**:HDFS通过在多个DataNode上复制数据块来保证数据的可靠性。默认情况下,每个数据块被复制三个副本(一个主副本和两个备份副本)。这种冗余策略确保了即使某些DataNode发生故障,数据仍然可以通过其他副本获取,保证了数据的持久性。
3. **心跳和重新复制**:DataNode定时向NameNode发送心跳信号,汇报自己的状态和存储的数据块信息。如果NameNode发现某个数据块的副本数量少于设定的副本数,它会启动重新复制过程,以保证数据块的冗余度符合要求。
### 2.1.2 HDFS数据完整性检查的常用命令
在HDFS中,进行数据完整性检查的常用命令包括`hdfs fsck`和`hadoop fs -checksum`,它们用于不同场景的数据验证:
1. **`hdfs fsck`**:这个命令用于检查HDFS文件系统的健康状况和完整性。它能报告丢失的块、损坏的块、文件权限问题、路径问题等。它提供了多个选项来定制检查的细节,例如检查单个文件或目录,排除已经检查过的文件等。
示例命令:
```sh
hdfs fsck / -files -blocks -locations
```
上述命令会检查HDFS根目录下的所有文件和目录,输出丢失和损坏的块,并显示块的位置信息。
2. **`hadoop fs -checksum`**:此命令用于计算HDFS上文件的校验和,并与存储的校验和进行比较,确认数据块是否损坏。
示例命令:
```sh
hadoop fs -checksum /path/to/file
```
执行此命令后,系统会输出文件的路径、校验和以及相应的块信息。
## 2.2 HDFS数据完整性检查的实践操作
### 2.2.1 HDFS数据完整性检查的步骤
为了进行HDFS数据完整性检查,可以按照以下步骤操作:
1. **启动Hadoop集群**:确保NameNode和DataNode正常启动,并且集群处于健康状态。
2. **运行`hdfs fsck`命令**:这是进行HDFS文件系统完整性检查的最直接方法。它可以识别文件系统中的不一致性,比如丢失的数据块、文件元数据问题等。
3. **使用`hadoop fs -checksum`命令**:对特定文件进行校验和检查,确保其数据块没有损坏。
4. **分析输出结果**:检查命令的输出,寻找错误或警告信息,并据此判断文件系统的完整性状态。
### 2.2.2 HDFS数据完整性检查的实例解析
假设我们有一个Hadoop集群,需要检查位于`/user/hadoop/testfile.txt`文件的完整性。以下是操作步骤:
1. **执行`hdfs fsck`检查文件系统**:
```sh
hdfs fsck /user/hadoop/testfile.txt -files -blocks -locations
```
此命令将检查`testfile.txt`文件的健康状况。如果发现文件不完整,比如某个数据块丢失或损坏,输出结果中会显示相关警告或错误。
2. **对文件执行校验和检查**:
```sh
hadoop fs -checksum /user/hadoop/testfile.txt
```
这个命令将验证文件的每个数据块的校验和是否正确。如果数据块损坏,校验和将与存储在DataNode上的校验和不匹配。
通过这些步骤,我们可以确保HDFS中的数据是完整无误的。若发现问题,则需要进一步的故障排查和恢复操作。
## 2.3 HDFS数据完整性检查的问题解决
### 2.3.1 常见问题及解决方式
在执行HDFS数据完整性检查时,可能会遇到一些常见问题,下面列举几个问题及其解决方式:
1. **数据块丢失**:
- **问题描述**:HDFS报告丢失某个数据块。
- **解决方法**:可以通过手动复制其他副本或从备份中恢复丢失的数据块。
2. **数据块损坏**:
- **问题描述**:计算出来的校验和与存储的校验和不一致。
- **解决方法**:删除损坏的数据块,并让HDFS自动重新复制一个正确的副本。
### 2.3.2 HDFS数据完整性检查的优化建议
为了提高HDFS数据完整性检查的效率和可靠性,可以采取以下优化建议:
1. **定期自动化检查**:设置定时任务定期执行`hdfs fsck`和`hadoop fs -checksum`,确保及时发现和处理问题。
2. **增加副本数量**:在数据重要性较高的情况下,可以增加数据块的副本数以提高数据的冗余度和可靠性。
3. **监控和报警机制**:建立有效的监控系统,当出现数据完整性问题时能够及时发出报警,以便快速响应。
通过这些实践技巧和问题解决策略,可以有效地维护HDFS的数据完整性,保障数据在分布式环境下的可靠性。
# 3. HDFS故障排查的专家级策略
## 3.1 HDFS故障排查的理论基础
### 3.1.1 HDFS故障类型及其原因
Hadoop分布式文件系统(HDFS)是大数据存储的基石,但并非没有故障的可能。HDFS故障可大致分为两类:硬件故障和软件故障。硬件故障包括但不限于硬盘故障、网络设备故障和节点故障。而软件故障主要涉及到配置错误、系统bug以及人为错误等。
理解故障的类型对于定位问题的根源至关重要。例如,硬盘故障可能导致数据丢失,而网络问题则可能导致数据访问延迟。在进行故障排查之前,我们必须对可能的故障类型有一个全面的理解。
### 3.1.2 HDF

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏“HDFS-安全校验”深入剖析了HDFS数据完整性保护机制,为读者提供了全面的指南。从基础原理到高级配置,再到自动化运维和跨版本解决方案,专栏涵盖了HDFS数据校验的方方面面。通过深入浅出的讲解和丰富的案例,读者可以全面了解数据校验的原理、实现方式和最佳实践。专栏旨在帮助读者构建一个无懈可击的数据存储系统,保障数据安全和完整性,并提高运维效率,为企业提供可靠的数据管理解决方案。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【大数据精细化管理】:掌握ReduceTask与分区数量的精准调优技巧

# 1. 大数据精细化管理概述
在当今的信息时代,企业与组织面临着数据量激增的挑战,这要求我们对大数据进行精细化管理。大数据精细化管理不仅关系到数据的存储、处理和分析的效率,还直接关联到数据价值的最大化。本章节将概述大数据精细化管理的概念、重要性及其在业务中的应用。
大数据精细化管理涵盖从数据
【数据仓库Join优化】:构建高效数据处理流程的策略

# 1. 数据仓库Join操作的基础理解
## 数据库中的Join操作简介
在数据仓库中,Join操作是连接不同表之间数据的核心机制。它允许我们根据特定的字段,合并两个或多个表中的数据,为数据分析和决策支持提供整合后的视图。Join的类型决定了数据如何组合,常用的SQL Join类型包括INNER JOIN、LEFT JOIN、RIGHT JOIN、FULL JOIN等。
## SQL Joi
MapReduce自定义分区:规避陷阱与错误的终极指导

# 1. MapReduce自定义分区的理论基础
MapReduce作为一种广泛应用于大数据处理的编程模型,其核心思想在于将计算任务拆分为Map(映射)和Reduce(归约)两个阶段。在MapReduce中,数据通过键值对(Key-Value Pair)的方式被处理,分区器(Partitioner)的角色是决定哪些键值对应该发送到哪一个Reducer。这种机制至关
MapReduce与大数据:挑战PB级别数据的处理策略
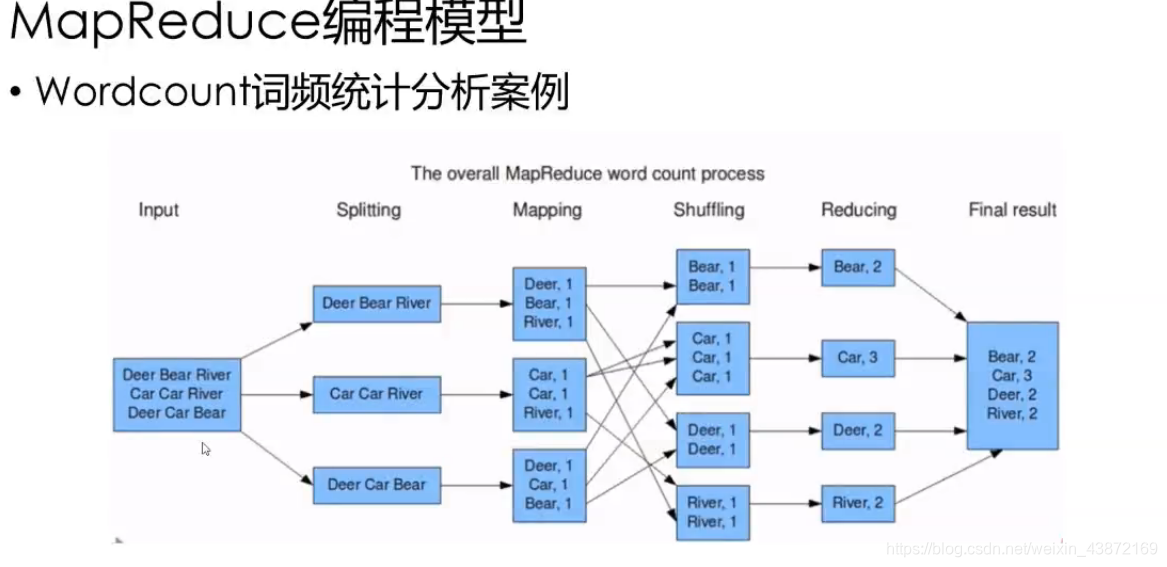
# 1. MapReduce简介与大数据背景
## 1.1 大数据的定义与特性
大数据(Big Data)是指传统数据处理应用软件难以处
【分片大小的艺术】:算法、公式及计算详解

# 1. 分片大小概念概述
在大数据处理和存储领域,分片(Sharding)是将数据分散存储在多个物理节点上的一种技术。分片大小是分片策略中一个关键参数,它决定了每个分片的数据量大小,直接影响系统性能、可扩展性及数据管理的复杂度。合理设置分片大小能够提高查询效率,优化存储使用,并且对于维护高性能和可伸缩性至关重要。接下来章节将对分片算法的理论基
跨集群数据Shuffle:MapReduce Shuffle实现高效数据流动

# 1. MapReduce Shuffle基础概念解析
## 1.1 Shuffle的定义与目的
MapReduce Shuffle是Hadoop框架中的关键过程,用于在Map和Reduce任务之间传递数据。它确保每个Reduce任务可以收到其处理所需的正确数据片段。Shuffle过程主要涉及数据的排序、分组和转移,目的是保证数据的有序性和局部性,以便于后续处理。
MapReduce小文件处理:数据预处理与批处理的最佳实践

# 1. MapReduce小文件处理概述
## 1.1 MapReduce小文件问题的普遍性
在大规模数据处理领域,MapReduce小文件问题普遍存在,严重影响
项目中的Map Join策略选择
# 1. Map Join策略概述
Map Join策略是现代大数据处理和数据仓库设计中经常使用的一种技术,用于提高Join操作的效率。它主要依赖于MapReduce模型,特别是当一个较小的数据集需要与一个较大的数据集进行Join时。本章将介绍Map Join策略的基本概念,以及它在数据处理中的重要性。
Map Join背后的核心思想是预先将小数据集加载到每个Map任
MapReduce中的Combiner与Reducer选择策略:如何判断何时使用Combiner

# 1. MapReduce框架基础
MapReduce 是一种编程模型,用于处理大规模数据集
【MapReduce数据处理】:掌握Reduce阶段的缓存机制与内存管理技巧

# 1. MapReduce数据处理概述
MapReduce是一种编程模型,旨在简化大规模数据集的并行运算。其核心思想是将复杂的数据处理过程分解为两个阶段:Map(映射)阶段和Reduce(归约)阶段。Map阶段负责处理输入数据,生成键值对集合;Reduce阶段则对这些键值对进行合并处理。这一模型在处理大量数据时,通过分布式计算,极大地提
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )