Actor-Critic原理与PPO算法推导,李宏毅课程PPT讲解
需积分: 31 33 浏览量
更新于2023-12-31
1
收藏 1.05MB PPTX 举报
Actor-Critic原理和PPO算法是强化学习中常用的算法之一。在这篇文章中,我们将详细介绍Actor-Critic原理和PPO算法的推导及其核心思想。
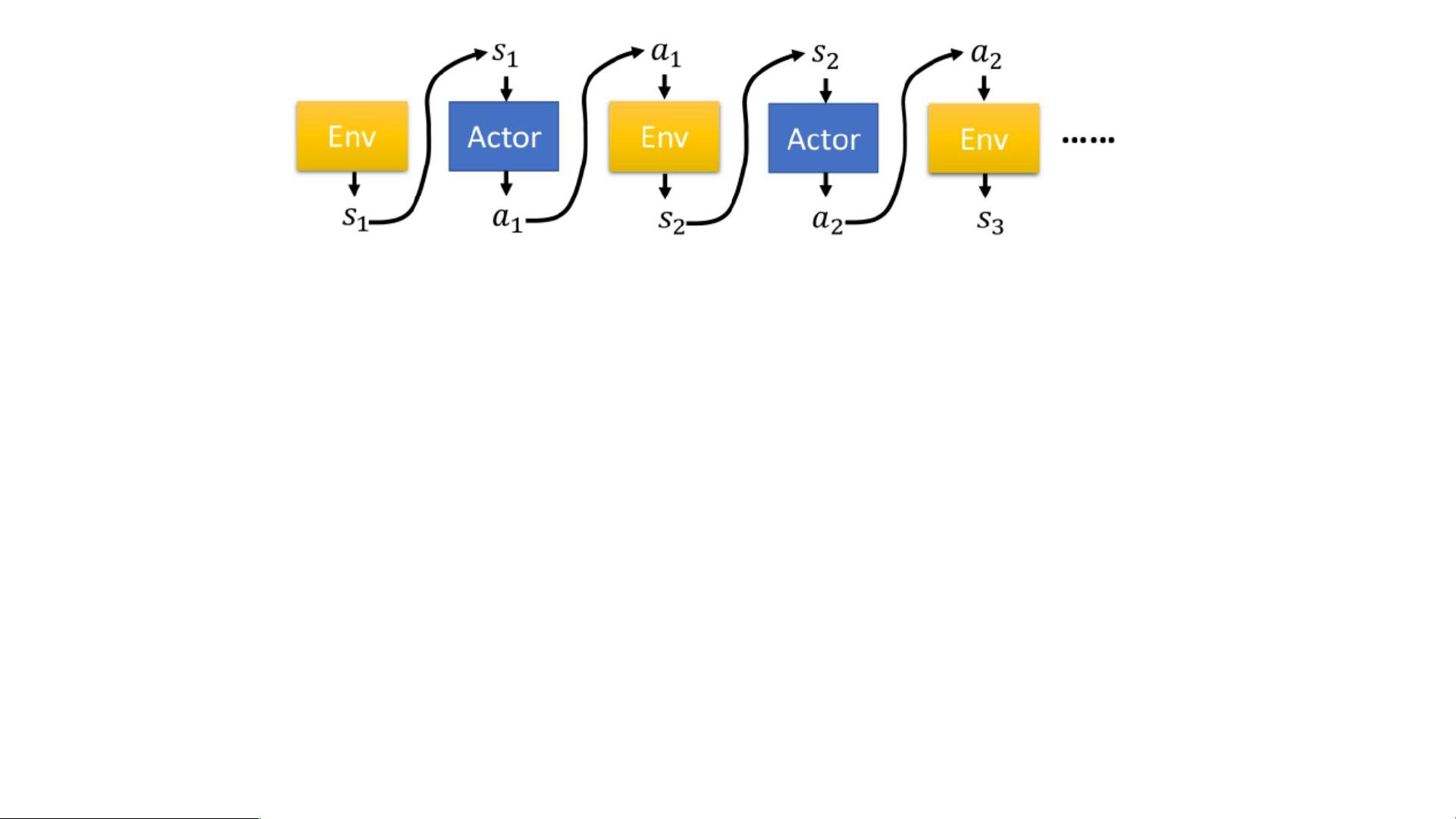
首先,让我们来了解一下Actor-Critic框架的工作原理。Actor-Critic算法中包含了两个部分,分别是Actor和Critic。Actor负责生成动作,而Critic则评估Actor生成的动作的好坏。
在这个框架中,环境(Env)会提供当前的状态,并根据Actor生成的动作给出奖励(Reward)。一个episode就是一场游戏的过程,我们的目标就是最大化获得的总奖励。
接下来,我们将介绍PPO算法的推导过程。在PPO算法中,当Actor的参数为θ时,某个动作a发生的概率为π(a|θ)。我们希望最大化这个期望值,即最大化E[π(a|θ)]。
然而,由于概率π(a|θ)是无法直接计算的,我们只能通过采样得到。假设在采样中,动作a出现的次数为N(a),总的奖励为R(a)。我们可以将N(a)视为(状态,动作)对的权重。
为了解决reward可能总是正的问题,我们需要引入一个baseline。如果某个action未被采样到,那么它出现的概率会下降。通过引入baseline可以解决这个问题。
除了引入baseline之外,我们还需要分配适当的credit,即给每个动作分配合适的权重。这是因为所有的动作可能对最终的总奖励有不同程度的贡献。
总结一下,Actor-Critic原理和PPO算法通过将强化学习问题分成Actor和Critic两个部分来解决。在PPO算法中,我们希望最大化Actor生成动作的期望值,但由于无法直接计算,需要通过采样得到。除此之外,我们还需要引入baseline来解决reward总是正的问题,并且需要分配适当的credit来给每个动作分配权重。
综上所述,Actor-Critic原理和PPO算法是强化学习中非常重要的算法,通过理解和应用这些算法,我们可以提高强化学习的效果。
文献阅读
9
PPO 算法:
Actor 参数为时,某一个发生的概率为:
的期望值:
交给 Actor 网络要做的事情就是最大化,我们需要知道
剩余14页未读,继续阅读
点击了解资源详情
2022-07-14 上传
2020-08-09 上传
2022-04-13 上传
2022-07-14 上传
2024-01-13 上传

AllesGute666
- 粉丝: 1
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- 西门子PLC工程实例源码第645期:连接S7-300到S7-200通过PROFIBUS程序.rar
- 数独递归:实现了递归回溯数独求解算法
- disaster-response
- psi3862015:PSI3862015专题制作
- 没得比 实时推送-crx插件
- MMM-MP3Player:一个MagicMirror模块,用于在插入USB随身碟后立即播放音乐
- carGamePerceptron:涉及JavaScript游戏的神经网络实验
- 时尚城购物比价助手-crx插件
- simple-resto-app
- Paw-JSONSchemaFakerDynamicValue:在Paw中为JSON模式生成伪造的值
- 西门子PLC工程实例源码第644期:连接S7-200(主站)到多个S7-200(从站)通过GSM MODEM程序.rar
- FFMPEG_RTMP协议_收流_推流
- onejava01:第一次提交到远程仓库
- osadmin开源管理后台 v2.1.0
- MyEasy86-crx插件
- 课程-cristianmoreno
