自底向上:非纠缠关键点回归提升人体姿态估计精度
137 浏览量
更新于2024-06-17
收藏 1.14MB PDF 举报
本文主要探讨了在计算机视觉领域的人体姿态估计问题,特别是在自底向上(top-down)方法中,如何通过改进关键点回归的准确性来提升整体性能。传统的关键点检测和分组框架在处理这一任务时可能存在局限,因为它们往往依赖于整体特征提取,可能忽视了对关键点区域的关注。
作者耿子刚等人提出了名为“非纠缠关键点回归”(DEKR)的方法,这是一种创新的解决方案。DEKR的核心在于利用自适应卷积技术和逐像素空间Transformer,这些技术能够在像素级别激活并学习关键点区域的表示。这种方法的特点在于每个分支独立学习特定关键点的表示,这样可以实现解纠缠表示,使得网络能够更专注于关键点区域,从而提高关键点位置的预测精度。
相比于传统的自上而下方法,如先检测后估计,自下而上的策略通常更高效,但可能精度稍逊。DEKR通过直接回归关键点,跳过了中间的人体检测步骤,减少了计算复杂性和错误传播的可能性。在实验部分,DEKR在COCO和Crowd-Pose这两个常用的人体姿态估计算法评估基准上表现出色,证明了其在自底向上人体姿态估计中的优势。
值得注意的是,这项工作是在耿子刚和孙科在北京微软研究院实习期间完成的,这表明该研究得到了实际应用背景的支持。文章的代码和模型可供公众访问,对于那些对图像关键点定位、人机交互以及智能应用感兴趣的开发者来说,DEKR提供了有价值的技术参考。
DEKR通过优化关键点区域的表示学习和回归机制,为自底向上人体姿态估计提供了一个新的、有效的途径,有望在未来的人体姿态估计和相关应用中发挥重要作用。
14678
S
si
si
Paf [31],关联嵌入[40],PersonLab [47]中使用hough投
票的贪婪解码,以及HGG[27]中的图形聚类。
最近的几项工作[78,44,42,67]密集地回归了一
组姿势候选者,其中每个候选者由可能来自同一个人
的关键点位置组成不幸的是,回归质量不高,局部化
质量较弱。通常采用后处理方案,将回归的关键点位
置与从关键点热图检测到的最近的关键点(其在空间
上更准确)匹配,以改善回归结果。
我们的方法旨在改善直接回归结果,
通过聚焦
思想
探索我们的回归。我们学习K
个
解纠缠表示,每个表
示都是针对一个关键点的,并从自适应激活的像素中
学习,因此每个表示都专注于相应的关键点区域。因
此,根据对应的解纠缠表示的一个关键点的位置预测
在空间上是准确的。我们的方法优于[63 ],与[ 63 ]不
同,[ 63]使用混合密度网络来处理不确定性,以改善
直接回归结果。
分解表征学习。解纠缠表示[3]已在计算机视觉[38,
15,76,64,79]中得到广泛研究,例如,将表象分解
为内容和姿态[15],将运动从内容中分离[64],将姿态
和外观分离[76]。
我们提出的解纠缠回归在某种意义上可以被视为解
纠缠表示学习:从对应的关键点区域中分别学习每个
关键点的表示自上而下的方法,基于部分的分支网络
(PBN)[59],也探索了姿态估计的表示解纠缠的想
法,该方法通过将表示解纠缠到每个部分组中来学习
高质量的热图它们是明显不同的:我们的方法学习表
示集中在每个关键点区域的位置回归,和PBN去相关
的外观表示在不同的部分群体。
3.
方法
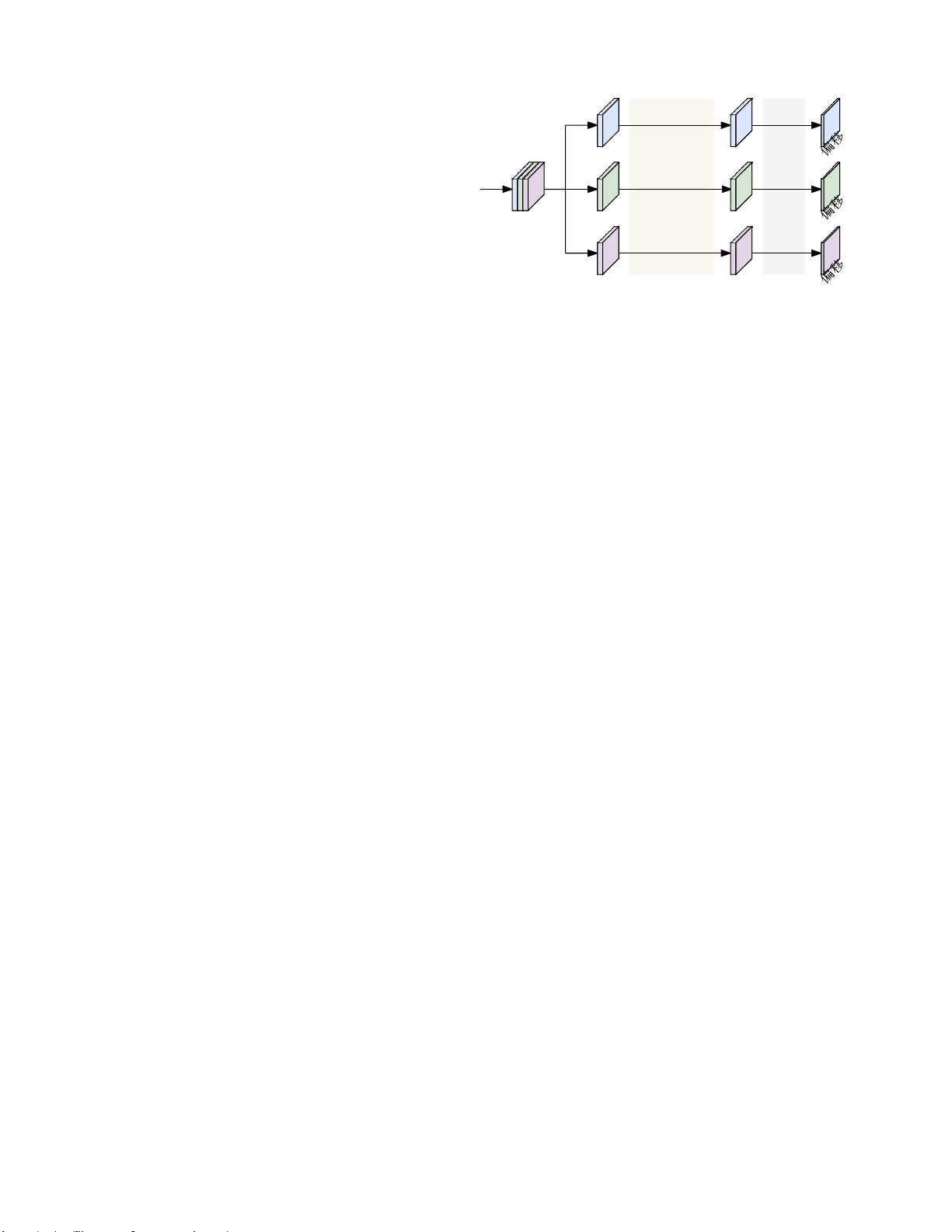
图3.分解关键点回归。每个分支通过两个自适应卷积从主干
输出的特征图的分区学习一个关键点的表示,并分别使用
1×1卷积回归每个关键点的2D偏移这是三个关键点的示意
图,特征图被分成三个部分,每个部分被送入一个分支。在
COCO姿态估计的实验中,特征图被分成17个分区,有17个
分支用于回归17个关键点。
关键点回归头,
O
=
F
(X)
,
(
1
)
其中X是从主干(本文中为HRNet)计算的特征,并且
F
()是预测偏移映射O的关键点位置回归头。
所提出的解开的关键点回归(DEKR)头的结构如
图3所示。DEKR采用多分支并行自适应卷积来学习K
个
关键点回归的解纠缠表示,使得每个表示聚焦于对
应的关键点区域。
适应性激活。一个正常卷积(例如,
3×3
卷积)只看
到中心像素
q
附近的像素。几个正常卷积的序列可以看
到pix-
可能位于关键点区域中的远离中心像素的像素,但是
可能不聚焦于这些像素并且高度激活这些像素。
我们采用自适应卷积,学习表示集中在关键点区
域。 自适应卷 积是正 常卷 积的修 改(例 如,
3×3
卷
积):
对于图像I,多人姿态估计的目的是使多个
人
的姿态
达到
最
小。
预测人体姿势,其中每个姿势由K
y
(q
)=
i=1
W
i
x
(
g
si
+ q
)
。
关键点,如肩膀、肘部等。图2说明了多人姿势估计问
题。
3.1.
非纠缠关键点回归
这里,
q
是中心(
2D
)位置,并且
g
q
是偏移,
g
q
+
q
对
应于第
i
个激活的像素。
{
W1
,
W2
,
. . .
,
W
9
}
是核权重。
偏移{g
q
,
g
q
,
. . .
,
g
q
}
(表示为2 × 9
ma-
第
一
季第
二
季第
九
集
逐像素关键点回归框架通过从K个关键点的中心像
素q预测2K维偏移向量
oq
来估计每个像素q(称为中心
像素)处的候选姿态包含所有像素处的偏移向量的偏
移图O通过
可以通过非参数方式的额外正常3×3卷积(如可变形
卷积)
解[14],或者以参数方式将空间Transformer网络[26]从
全局方式扩展到逐像素方式。我们采用后者,并估计
仿射
适配器。
conv.
conv.
适配器。
conv.
conv.
适配器。
conv.
conv.
剩余14页未读,继续阅读
829 浏览量
191 浏览量
241 浏览量
190 浏览量
190 浏览量
140 浏览量
123 浏览量
226 浏览量
2024-12-26 上传

cpongm
- 粉丝: 5
- 资源: 2万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- fabricator, 构建网站用户界面工具包和样式指南的工具.zip
- 编程器XTW100高速24 25编程器.zip
- Backward-Facing-Step-----OpenFOAM:tfjh
- RCGames:允许AI相互玩游戏的服务器
- ng-cells, AngularJS表指令,用于绘制具有不同功能的数据表.zip
- vray材质与标准材质互转
- uroboros:CDCI工具
- info3180-project1:这是课程INFO3180的第一个项目
- WirelessPrinting:从Cura,PrusaSlicer或Slic3r无线打印到与ESP8266(以后也称为ESP32)模块连接的3D打印机
- Magento-OpCache, Magento后端的OpCache ( Zend优化器) 控制面板 ( GUI ).zip
- iOS13.5 的最新的支持包,添加之后可以解决xcode无法真机调试的问题
- TimotheeThiry_2_100221:OpenClassrooms的Web开发人员路径。 第二项目
- 欧美风城市旅行相册PPT模板
- rhel配置新的yum源
- 前端TB
- ramme:非官方的Instagram桌面应用程序
