Java语言实现八大经典排序算法
需积分: 9 187 浏览量
更新于2024-09-12
1
收藏 99KB DOC 举报
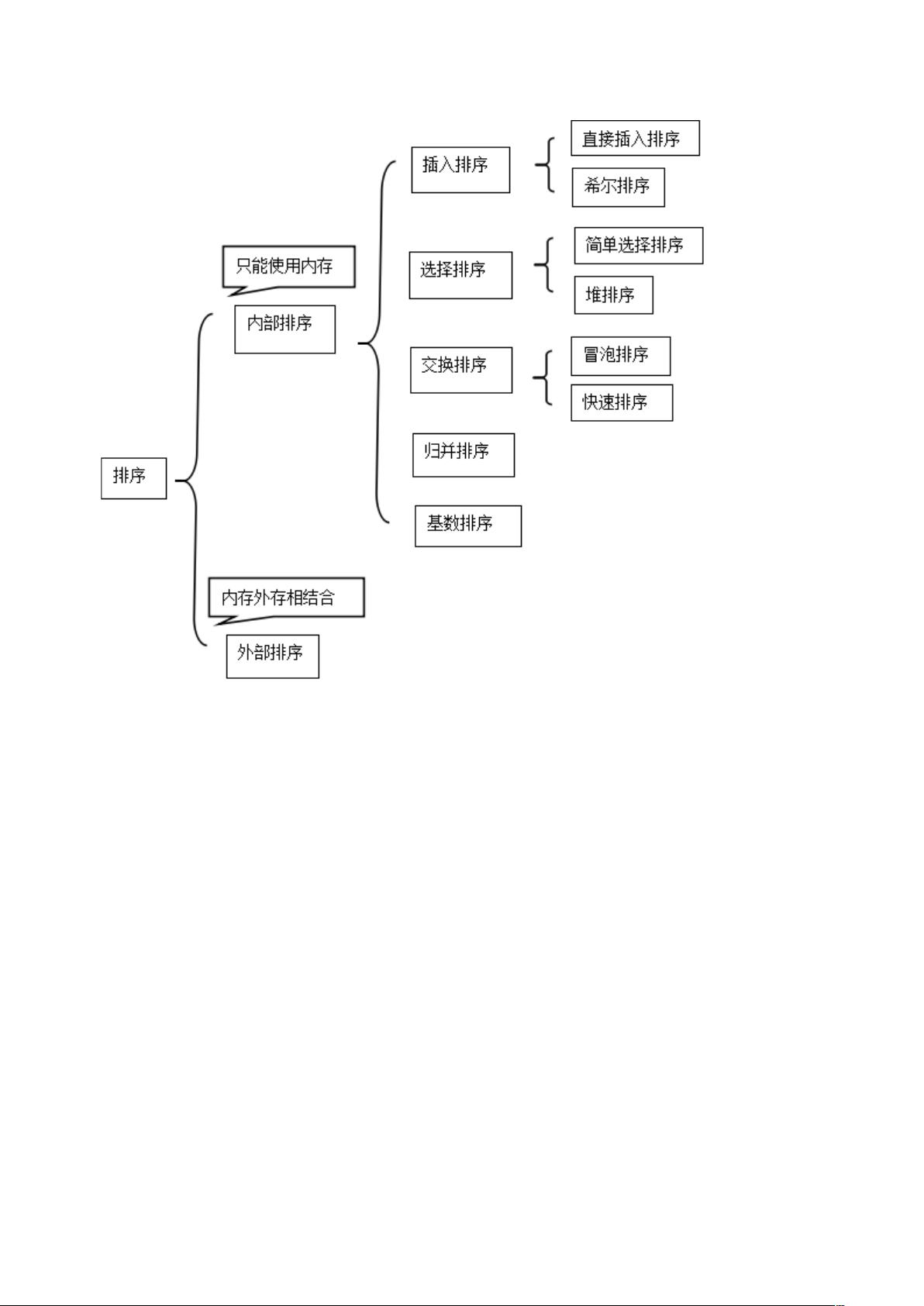
八大排序算法
在计算机科学中,排序算法是将一组数据按照一定的顺序排列的算法。常见的排序算法有八种,即冒泡排序、选择排序、插入排序、希尔排序、归并排序、快速排序、堆排序、基数排序。下面将详细介绍这八大排序算法,并提供Java语言的实现代码。
一、冒泡排序(Bubble Sort)
冒泡排序是一种简单的排序算法,它的工作原理是通过重复地遍历要排序的数据,比较相邻元素,并交换它们以达到排序的目的。冒泡排序的时间复杂度为O(n^2),因此它不适合大规模数据的排序。
在上面的代码中,我们可以看到冒泡排序的实现:
```java
public void BubbleSort(int[] a) {
for (int i = 0; i < a.length - 1; i++) { // 最多做n-1趟排序
for (int j = 0; j < a.length - i - 1; j++) {
if (a[j] < a[j + 1]) { // 把小的值交换到后面
int temp = a[j];
a[j] = a[j + 1];
a[j + 1] = temp;
}
}
System.out.print("第" + (i + 1) + "次排序结果:");
for (int j = 0; j < a.length; j++) {
System.out.print(a[j] + "\t");
}
System.out.println("");
}
System.out.print("最终排序结果:");
for (int j = 0; j < a.length; j++) {
System.out.print(a[j] + "\t");
}
}
```
二、选择排序(Selection Sort)
选择排序是一种简单的排序算法,它的工作原理是通过选择最小的元素,并将其交换到数组的开头,然后从剩余元素中选择最小的元素,依次类推。选择排序的时间复杂度为O(n^2),因此它不适合大规模数据的排序。
三、插入排序(Insertion Sort)
插入排序是一种简单的排序算法,它的工作原理是通过将每个元素插入到已经排序的数组中,以达到排序的目的。插入排序的时间复杂度为O(n^2),因此它不适合大规模数据的排序。
在上面的代码中,我们可以看到插入排序的实现:
```java
public void InsertSort(int[] a) {
int start = 0, end = 0;
int root = start;
// child孩子节点,swap要交换的节点
int child, swap;
// while root has at least one child
while (root * 2 + 1 <= end) {
child = root * 2 + 1;
swap = root;
// 检查根节点是否小于左子树
if (a[swap] < a[child]) {
swap = child;
}
if (a[swap] < a[child + 1]) {
swap = child + 1;
}
if (swap != root) {
int tmp = a[root];
a[root] = a[swap];
a[swap] = tmp;
} else { // swap==root说明已经是一个小堆
return;
}
}
}
```
四、希尔排序(Shell Sort)
希尔排序是一种改进的插入排序算法,它的工作原理是通过将数组分成多个子数组,然后对每个子数组进行插入排序。希尔排序的时间复杂度为O(n log n),因此它适合大规模数据的排序。
五、归并排序(Merge Sort)
归并排序是一种 Divide-and-Conquer 算法,它的工作原理是通过将数组分成两个子数组,然后对每个子数组进行排序,最后将两个子数组合并成一个排序的数组。归并排序的时间复杂度为O(n log n),因此它适合大规模数据的排序。
六、快速排序(Quick Sort)
快速排序是一种 Divide-and-Conquer 算法,它的工作原理是通过选择一个.pivot 元素,然后将数组分成两个子数组,左子数组中的元素小于.pivot,右子数组中的元素大于.pivot,然后对每个子数组进行快速排序。快速排序的时间复杂度为O(n log n),因此它适合大规模数据的排序。
七、堆排序(Heap Sort)
堆排序是一种选择排序算法,它的工作原理是通过将数组视为一个堆,然后将堆的根节点与最后一个元素交换,最后将堆的大小减少1,重复上述步骤直到堆的大小为1。堆排序的时间复杂度为O(n log n),因此它适合大规模数据的排序。
在上面的代码中,我们可以看到堆排序的实现:
```java
private void heapify(int[] a, int count) {
// 从最后一个父节点开始
int start = (count - 2) / 2;
while (start >= 0) {
HeapSort(a, start, count - 1);
start -= 1;
}
}
public void HeapSort(int[] a, int start, int i) {
// ...
}
```
八、基数排序(Radix Sort)
基数排序是一种非比较排序算法,它的工作原理是通过将数组中的元素视为字符串,然后对每个字符串进行排序。基数排序的时间复杂度为O(nk),其中k是数组中的最大数字的位数。
八大排序算法各有其优缺,选择合适的排序算法取决于具体的应用场景和数据规模。
import java.util.Arrays;
public class sort {
//冒泡排序
public void BubbleSort(int a[]){
for (int i = 0; i < a.length -1; i++){ //最多做n-1趟排序
for(int j = 0 ;j < a.length - i - 1; j++){
if(a[j] < a[j + 1]){ //把小的值交换到后面
int temp = a[j];
a[j] = a[j + 1];
a[j + 1] = temp;
}
}
System.out.print("第" + (i + 1) + "次排序结果:");
for(int j = 0; j < a.length; j++){
System.out.print(a[j] + " ");
}
System.out.println("");
}
System.out.print("最终排序结果:");
下载后可阅读完整内容,剩余6页未读,立即下载
2013-04-19 上传
2013-01-07 上传
2012-11-26 上传
2012-11-15 上传
2012-12-10 上传
2017-09-06 上传
2020-07-14 上传
2019-01-24 上传

白川汐奈
- 粉丝: 0
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- 探索数据转换实验平台在设备装置中的应用
- 使用git-log-to-tikz.py将Git日志转换为TIKZ图形
- 小栗子源码2.9.3版本发布
- 使用Tinder-Hack-Client实现Tinder API交互
- Android Studio新模板:个性化Material Design导航抽屉
- React API分页模块:数据获取与页面管理
- C语言实现顺序表的动态分配方法
- 光催化分解水产氢固溶体催化剂制备技术揭秘
- VS2013环境下tinyxml库的32位与64位编译指南
- 网易云歌词情感分析系统实现与架构
- React应用展示GitHub用户详细信息及项目分析
- LayUI2.1.6帮助文档API功能详解
- 全栈开发实现的chatgpt应用可打包小程序/H5/App
- C++实现顺序表的动态内存分配技术
- Java制作水果格斗游戏:策略与随机性的结合
- 基于若依框架的后台管理系统开发实例解析
