HBase数据读取深度解析:复杂流程与优化
172 浏览量
更新于2024-08-31
收藏 219KB PDF 举报
"HBase原理-数据读取流程解析"
在HBase中,数据读取的过程比写入更为复杂,这是由于其独特的存储引擎设计和数据处理机制。HBase基于LSM-Like(Log-Structured Merge Tree)树结构,使得一次查询可能涉及到多个Region(分片)、多块MemStore(内存缓冲区)以及多个HFile(数据存储文件)。这种设计对于写入优化,但增加了读取的复杂性。
首先,HBase的更新操作并不直接覆盖原有数据,而是采用时间戳属性来实现多版本并发控制(MVCC)。这意味着每次更新都会生成一个新的数据版本,旧版本仍然保留,直到被Major Compaction清理。Major Compaction是HBase的一个后台进程,它合并多个HFile并删除过期或被标记为删除的数据。
删除操作在HBase中也不是即时的,它实际上是插入一条带有“deleted”标记的新记录,而非物理删除。真正的删除在Major Compaction时才会执行,这样做的好处是提高了写入效率,但读取时需要检查和过滤这些标记为删除的记录。
理解HBase的读取流程分为两个层次:一是从宏观角度理解Scan操作的整体流程,二是深入到实现细节和优化措施。Scan操作的流程大致包括以下步骤:
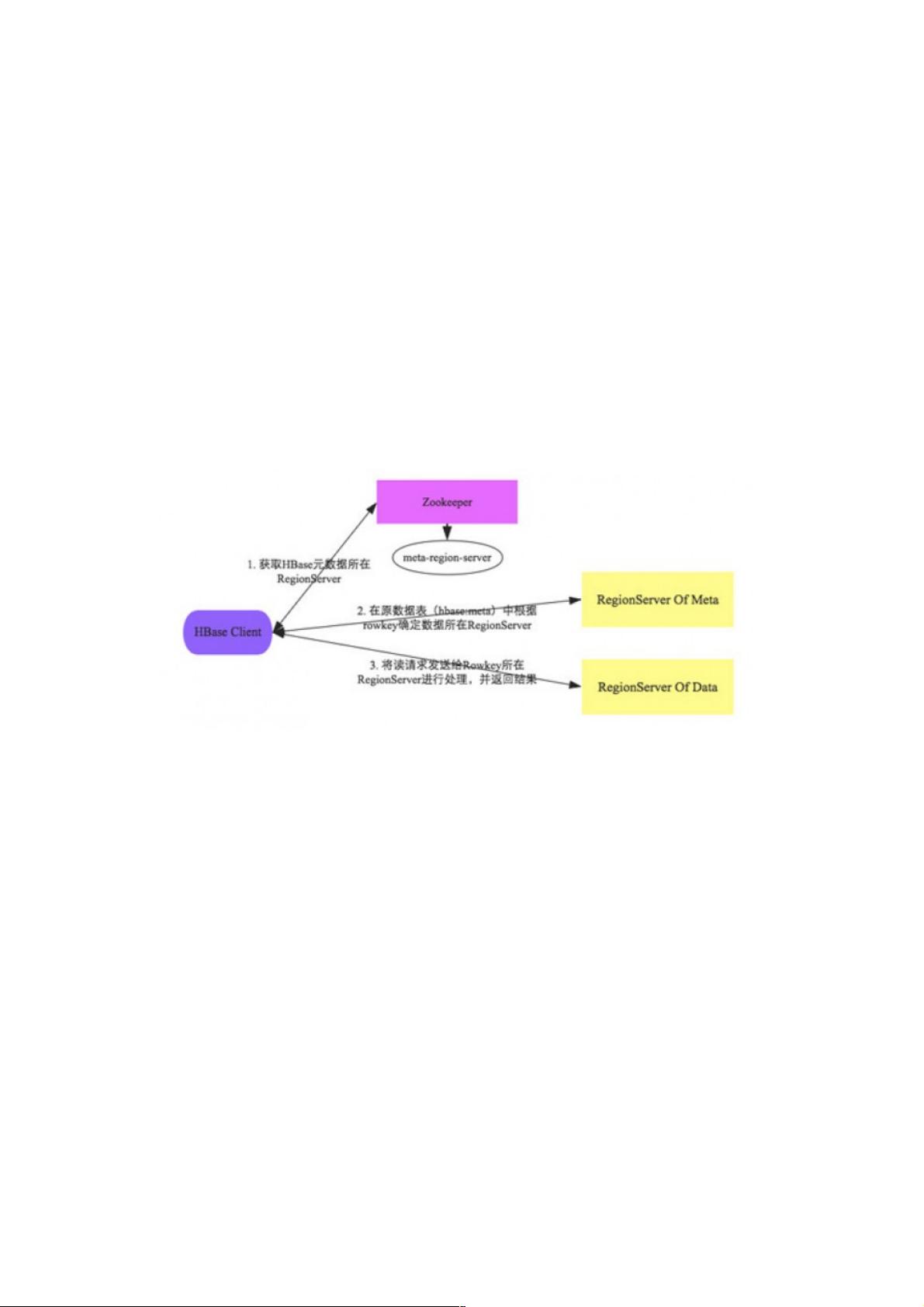
1. 客户端首先通过Zookeeper找到元数据表hbase:meta的RegionServer信息。Zookeeper是HBase的协调和发现服务,存储着关键的集群配置和位置信息。
2. 客户端将hbase:meta表加载到本地缓存,以便快速定位到目标数据所在的RegionServer。
3. 利用元数据信息,客户端确定待查询RowKey所在的Region,并向相应的RegionServer发送请求。
4. RegionServer接收到请求后,会在内存中的MemStore和磁盘上的HFile中查找数据。MemStore包含最新的未持久化的数据,而HFile存储已持久化的旧数据。
5. 在查找过程中,RegionServer需要处理多版本的数据,根据时间戳和删除标记过滤出有效版本,并返回给客户端。
6. 客户端收到数据后,可能还需要进一步处理,如聚合、排序等,然后展示给用户。
这个过程中,HBase还做了许多优化,比如预读取( speculative fetch)和行级缓存,以提高响应速度和整体性能。深入理解这些细节有助于优化HBase应用的性能和设计更高效的查询策略。
总结来说,HBase的数据读取流程虽然复杂,但得益于其独特的数据模型和设计,能够在高并发写入场景下保持高性能。然而,这也要求开发者在处理读取时,充分理解其背后的机制,以便有效地利用这些特性。
HBase原理-数据读取流程解析原理-数据读取流程解析
和写流程相比,HBase读数据是一个更加复杂的操作流程,这主要基于两个方面的原因:
其一是因为整个HBase存储引擎基于LSM-Like树实现,因此一次范围查询可能会涉及多个分片、多块缓存甚至多个数据存储
文件;
其二是因为HBase中更新操作以及删除操作实现都很简单,更新操作并没有更新原有数据,而是使用时间戳属性实现了多版
本。
删除操作也并没有真正删除原有数据,只是插入了一条打上”deleted”标签的数据,而真正的数据删除发生在系统异步执行
Major_Compact的时候。很显然,这种实现套路大大简化了数据更新、删除流程,但是对于数据读取来说却意味着套上了层
层枷锁,读取过程需要根据版本进行过滤,同时对已经标记删除的数据也要进行过滤。
总之,把这么复杂的事情讲明白并不是一件简单的事情,为了更加条理化地分析整个查询过程,接下来笔者会用两篇文章来讲
解整个过程,首篇文章主要会从框架的角度粗粒度地分析scan的整体流程,并不会涉及太多的细节实现。大多数看客通过首
篇文章基本就可以初步了解scan的工作思路;为了能够从细节理清楚整个scan流程,接着第二篇文章将会在第一篇的基础上引
入更多的实现细节以及HBase对于scan所做的基础优化。因为理解问题可能会有纰漏,希望可以一起探讨交流,欢迎拍砖~
Client-Server交互逻辑
运维开发了很长一段时间HBase,经常有业务同学咨询为什么客户端配置文件中没有配置RegionServer的地址信息,这里针
对这种疑问简单的做下解释,客户端与HBase系统的交互阶段主要有如下几个步骤:
客户端首先会根据配置文件中zookeeper地址连接zookeeper,并读取//meta-region-server节点信息,该节点信息存储HBase
元数据(hbase:meta)表所在的RegionServer地址以及访问端口等信息。用户可以通过zookeeper命令(get //meta-region-
server)查看该节点信息。
根据hbase:meta所在RegionServer的访问信息,客户端会将该元数据表加载到本地并进行缓存。然后在表中确定待检索
rowkey所在的RegionServer信息。
根据数据所在RegionServer的访问信息,客户端会向该RegionServer发送真正的数据读取请求。服务器端接收到该请求之后
需要进行复杂的处理,具体的处理流程将会是这个专题的重点。
通过上述对客户端以及HBase系统的交互分析,可以基本明确两点:
客户端只需要配置zookeeper的访问地址以及根目录,就可以进行正常的读写请求。不需要配置集群的RegionServer地址列
表。
客户端会将hbase:meta元数据表缓存在本地,因此上述步骤中前两步只会在客户端第一次请求的时候发生,之后所有请求都
直接从缓存中加载元数据。如果集群发生某些变化导致hbase:meta元数据更改,客户端再根据本地元数据表请求的时候就会
发生异常,此时客户端需要重新加载一份最新的元数据表到本地。
RegionServer接收到客户端的get/scan请求之后,先后做了两件事情:构建scanner体系(实际上就是做一些scan前的准备工
作),在此体系基础上一行一行检索。举个不太合适但易于理解的例子,scan数据就和开发商盖房一样,也是分成两步:组建
施工队体系,明确每个工人的职责;一层一层盖楼。
构建scanner体系-组建施工队
scanner体系的核心在于三层scanner:RegionScanner、StoreScanner以及StoreFileScanner。三者是层级的关系,一个
RegionScanner由多个StoreScanner构成,一张表由多个列族组成,就有多少个StoreScanner负责该列族的数据扫描。一个
StoreScanner又是由多个StoreFileScanner组成。每个Store的数据由内存中的MemStore和磁盘上的StoreFile文件组成,相对
应的,StoreScanner对象会雇佣一个MemStoreScanner和N个StoreFileScanner来进行实际的数据读取,每个StoreFile文件对
应一个StoreFileScanner,注意:StoreFileScanner和MemstoreScanner是整个scan的最终执行者。
下载后可阅读完整内容,剩余3页未读,立即下载
2022-07-11 上传
2022-04-22 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
2019-09-26 上传
2018-05-10 上传
2021-03-23 上传

weixin_38592455
- 粉丝: 7
- 资源: 896
 我的内容管理
展开
我的内容管理
展开







