Kafka:分布式消息队列在日志处理中的应用
"Kafka是一个由LinkedIn开发的分布式消息系统,主要设计用于处理大规模日志数据。它后来成为了Apache软件基金会的顶级项目,并广泛应用于实时数据流处理和大数据领域。Kafka以其高性能、高吞吐量和可扩展性而著称,能够同时支持离线和在线日志处理。在Kafka中,消息的发布者(producer)和生产者、订阅者(subscriber)和消费者是同义的。"
Kafka的核心特性包括以下几个方面:
1. **主题与分区**:
- **主题(Topic)**:Kafka中的消息被组织成主题,每个主题可以被分为多个**分区(Partition)**,这样可以实现水平扩展,增加系统的并行处理能力。每个分区都有一个唯一的标识,即分区ID。
2. **分区策略**:
- **分区分配**:发布者发送的消息会被按照预设的策略分布到各个分区上,这可以是随机分配,也可以根据特定的键(key)进行一致性哈希,确保相同键的消息被分配到相同的分区,从而保持消息顺序。
3. **消息存储**:
- **日志结构**:每个分区内部以日志的形式存储消息,日志由一系列**段(Segment)**组成。每个段包含一系列消息,每个消息都有一个唯一的**消息ID(Offset)**,可以根据Offset快速定位到消息。
- **内存索引**:每个分区维护一个内存中的索引,记录每个段的第一条消息的Offset,以便快速查找。
- **持久化**:消息在内存中累积到一定数量或达到预设的时间间隔后,会被刷新到磁盘。只有写入磁盘的消息才可供消费者消费。
4. **发布与订阅**:
- **发布者接口**:发布者创建消息并将其添加到消息集,然后指定消息所属的主题,Kafka客户端会负责将这些消息发送到对应的服务器。
- **订阅者接口**:消费者需要指定订阅的主题和分区数,订阅后,可以从最近的Offset开始读取消息。消费者可以设置消费模式,例如从头开始消费或是只消费新产生的消息。
5. **Zookeeper集成**:
- Kafka利用Zookeeper进行集群协调,包括管理主题、分区分配、领导者选举等,确保高可用性和一致性。
6. **高可用与容错**:
- **副本机制**:每个分区通常会有多个副本,分布在不同的服务器上,以提供容错能力。如果主分区的服务器出现故障,副本可以接管成为新的主分区。
- **ISR(In-Sync Replicas)**:处于同步状态的副本集合,确保数据的最新副本总是可以被选举为主副本。
7. **Hadoop集成**:
- Kafka可以方便地与Hadoop生态系统集成,例如通过Kafka Connect或Kafka-Hadoop Connector,将消息流数据导入Hadoop进行离线分析。
8. **性能优化**:
- **批量发送**:Kafka支持批量发送消息,减少网络交互次数,提高整体性能。
- **零拷贝**:Kafka通过零拷贝技术,减少了操作系统在处理数据传输时的内存拷贝操作,进一步提升性能。
Kafka是一个设计精良的分布式消息中间件,它通过高效的数据存储和检索机制,以及灵活的发布订阅模型,满足了大规模日志处理和实时数据流处理的需求。在现代大数据架构中,Kafka扮演着至关重要的角色。
Kafka 分布式消息系统
是 用于日志处理的分布式消息队列, 的日志数据容量大,但对
可靠性要求不高,其日志数据主要包括用户行为(登录、浏览、点击、分享、喜欢)以及
系统运行日志(、内存、磁盘、网络、系统及进程状态)。
当前很多的消息队列服务提供可靠交付保证,并默认是即时消费(不适合离线)。高
可靠交付对 的日志不是必须的,故可通过降低可靠性来提高性能,同时通过构建
分布式的集群,允许消息在系统中累积,使得 同时支持离线和在线日志处理。
注 : 本 文 中 发 布 者 ( ) 与 生 产 者 ( ) 可 以 互 换 , 订 阅 者
()与消费者()可以互换。
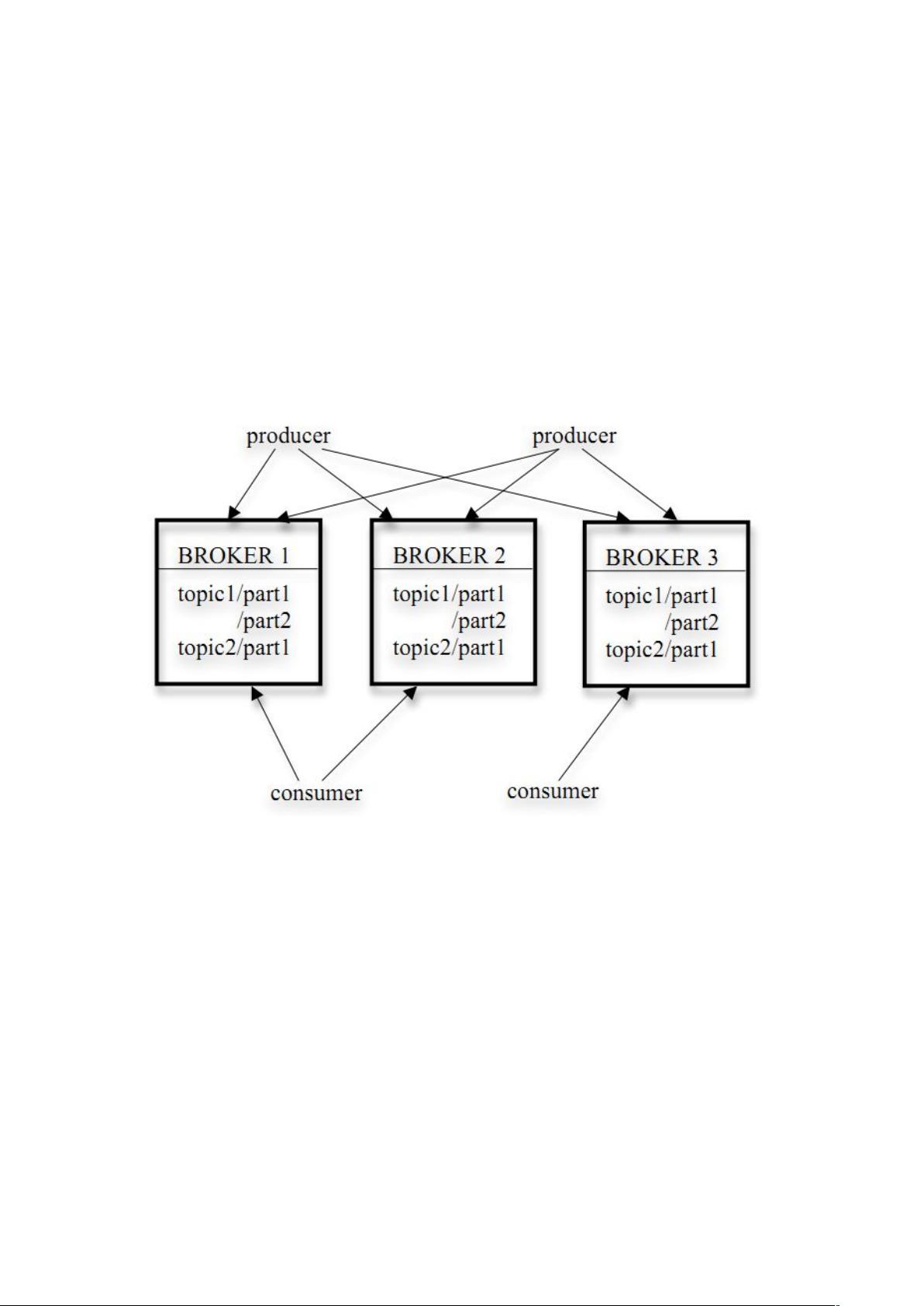
的架构如下图所示:
Kaa 存储策略
以 来进行消息管理,每个 包含多个 (),每个 对应一个逻
辑 ,有多个 组成。
每个 中存储多条消息(见下图),消息 由其逻辑位置决定,即从消息 可直
接定位到消息的存储位置,避免 到位置的额外映射。
每个 在内存中对应一个 ,记录每个 中的第一条消息偏移。
发布者发到某个 的消息会被均匀的分布到多个 上(随机或根据用户指定的回
调函数进行分布), 收到发布消息往对应 的最后一个 上添加该消息,
当某个 上的消息条数达到配置值或消息发布时间超过阈值时, 上的消息
会被 到磁盘,只有 到磁盘上的消息订阅者才能订阅到, 达到一定的大小
后将不会再往该 写数据, 会创建新的 。
下载后可阅读完整内容,剩余5页未读,立即下载
2018-02-02 上传
2016-12-17 上传
2021-05-31 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

默默的走着
- 粉丝: 4
- 资源: 10
 我的内容管理
展开
我的内容管理
展开







最新资源
- lock-system:锁定系统
- 毕业设计&课设--毕业设计-智慧课堂辅助App.zip
- 凯莱花园
- Excel模板00记账凭证.zip
- Network-Intrusion-Detection-System:使用神经网络设计和开发了基于异常和滥用的入侵检测系统。 使用的技术
- neo4j-foodmart-dataset:Neo4j Food Mart数据集
- React-Redux-Toolkit
- first-project-JS
- 毕业设计&课设--毕业设计最终源码.zip
- test-react-reflux:回流
- beyondskins.lostkatana
- Excel模板收据电子表格模板收据模板.zip
- faccat-ia-caixeiro-viajante
- CarEncryptProjectV2
- OSTM机器语言房屋价格
- 毕业设计&课设--毕业设计之人脸考勤机的实现,使用了QT+opencv.zip
