深度解析:Flink核心执行流程详解
需积分: 0 27 浏览量
更新于2024-07-01
收藏 4.88MB PDF 举报
"通过源码深度解析Flink核心框架的执行流程,从Hello,World的WordCount实例出发,探讨Flink的图结构、JobGraph、ExecutionGraph的生成以及任务的调度与执行机制,涵盖算子、数据源、数据处理、容错机制等方面。"
在Flink的执行流程中,首先是从简单的WordCount程序开始。这个程序涉及到Flink的执行环境,包括本地模式和远程模式。在本地模式下,`execute`方法会直接启动一个执行线程来运行任务;而在远程模式中,`RemoteEnvironment`的`execute`方法会将任务提交给JobManager。任务的启动过程包括构建StreamGraph,它是Flink程序的第一层图表示,由一系列StreamTransformation组成。
StreamGraph的生成过程中,每个流操作(如map、filter等)被表示为StreamTransformation,这些操作连接起来形成了流处理的逻辑。StreamGraph的生成函数会根据用户定义的函数和算子进行构造。WordCount的例子中,它的StreamGraph包含了Source、Map和Sink三个主要部分。
进一步,StreamGraph会被转化为JobGraph,这是第二层图结构,它考虑了operator chain的概念,优化了物理执行的布局。JobGraph的生成涉及到operator的并行度设置,并最终提交给JobManager。
在任务调度与执行阶段,JobManager作为Flink的协调者,管理任务的生命周期。它包含JobManager的主要组件,如作业存储、心跳机制等,并负责启动Task。TaskManager则是实际执行任务的工作节点,它接收并执行JobManager分配的任务,包含Task对象的创建、运行以及StreamTask的执行逻辑。StreamTask是任务的执行单元,它内部封装了具体的StreamOperator来处理数据。
StreamOperator是Flink处理逻辑的核心,包括数据源(如StreamSource)、数据处理(如OneInputStreamOperator和AbstractUdfStreamOperator)和数据输出(如StreamSink)。数据源负责读取输入数据,而数据处理算子执行用户定义的函数进行数据转换。StreamSink则将处理后的结果写入目标存储。
在保证系统高可用性和数据一致性方面,Flink采用了 FaultTolerant策略,确保Exactly-Once语义。它借鉴了不同系统的最佳实践,如Storm的记录确认模式、SparkStreaming的微批次处理、以及Google Cloud Dataflow的事务性模型,结合自身的特性实现了高效且可靠的容错机制。
这篇文章通过深入源码,详细解析了Flink从程序编排到执行的全过程,涵盖了从任务提交、图结构转换到任务调度与执行,以及容错机制等多个关键环节,为理解Flink的内部工作原理提供了宝贵的参考。
以MapFunction为例:
首先,用户代码里定义的UDF会被当作其基类对待,然后交给StreamMap这个operator
做进一步包装。事实上,每一个Transformation都对应了一个StreamOperator。
由于map这个操作只接受一个输入,所以再被进一步包装为OneInputTransformation。
最后,将该transformation注册到执行环境中,当执行上文提到的generate方法时,生成
StreamGraph图结构。
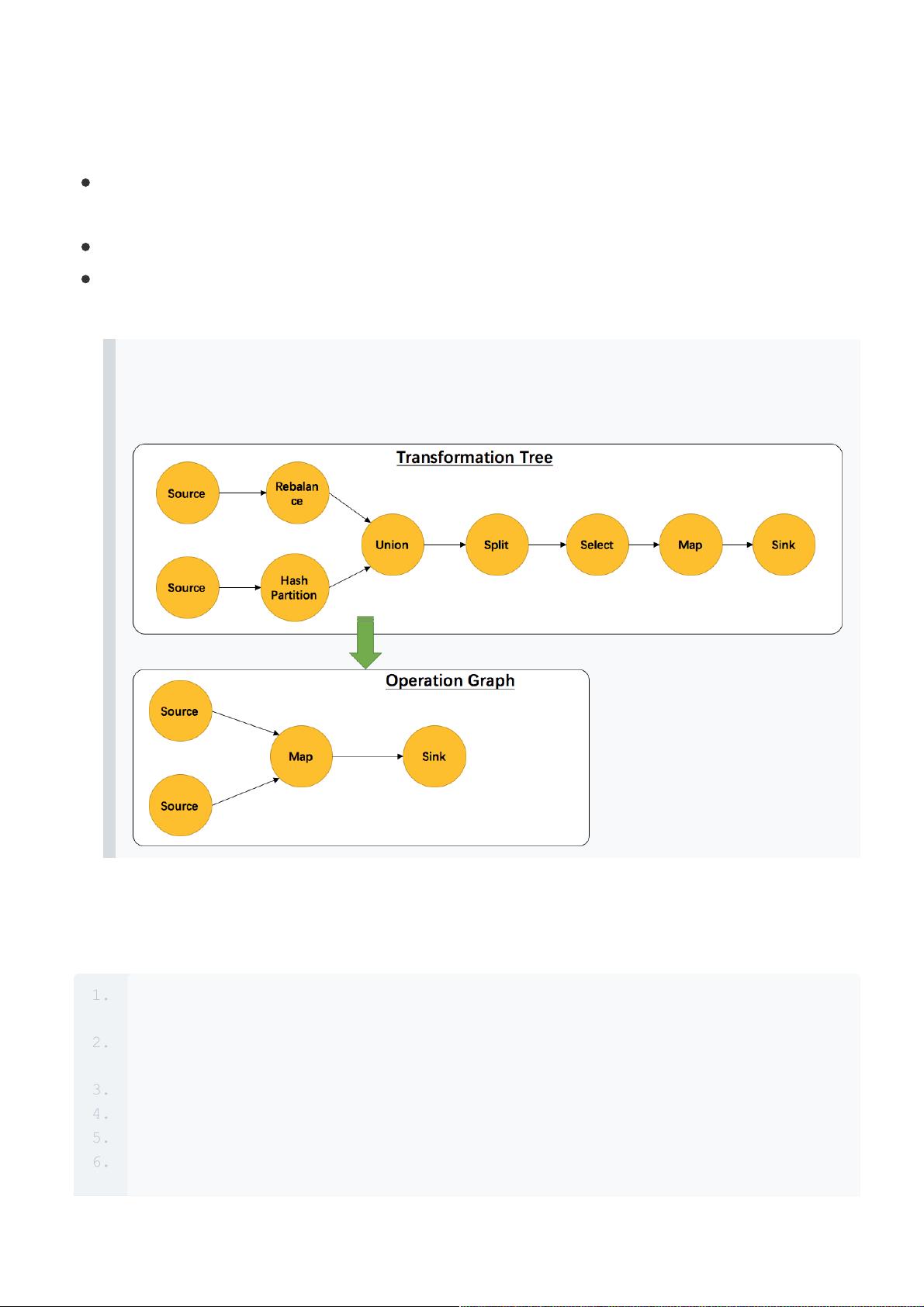
另外,并不是每一个 StreamTransformation 都会转换成runtime层中的物理操作。
有一些只是逻辑概念,比如union、split/select、partition等。如下图所示的转换
树,在运行时会优化成下方的操作图。
2.2.2 StreamGraph生成函数分析
我们从StreamGraphGenerator.generate()方法往下看:
1. public static StreamGraph generate(StreamExecutionEnvironment env,
List<StreamTransformation<?>> transformations) {
2. return new StreamGraphGenerator(env).generateInternal(transform
ations);
3. }
4.
5. //注意,StreamGraph的生成是从sink开始的
6. private StreamGraph generateInternal(List<StreamTransformation<?>>




剩余108页未读,继续阅读
2023-07-24 上传
2021-06-06 上传
2021-05-02 上传
2023-08-15 上传
2020-12-25 上传
2019-06-04 上传

透明流动虚无
- 粉丝: 41
- 资源: 306
 我的内容管理
展开
我的内容管理
展开







