SOA视频数据集:多任务、多标签的场景-对象-动作研究与深度分析
167 浏览量
更新于2024-06-20
收藏 1.07MB PDF 举报
本文主要探讨的是一个名为"场景-对象-动作"(SOA)的大规模、多任务、多标签视频数据集,其在视频理解和分析领域具有重要意义。当前,许多视频数据集依赖于预定义的分类体系,这种收集方式往往侧重于提高分类精度,但可能导致数据集缺乏多样性,特别是对于现实世界的复杂视觉概念的覆盖不足。
SOA数据集的独特之处在于它的收集方法。研究人员通过均匀采样从互联网获取视频,并让经过训练的注释员提供自由形式的文本标签,涵盖三个维度:场景、对象和动作。这个过程涉及标签的合并、拆分和重命名,以形成一个全面的分类框架,涵盖了49个场景类别、356个对象类别和148个动作类别。这种设计使得数据集自然地反映了现实生活中视觉概念的长尾分布,即罕见但重要的概念也被充分考虑。
SOA数据集的挑战性在于,它能对视频中的三个关键元素——场景、对象和动作之间的关系进行深入研究,这对于评估现有的视频模型具有很高的价值。文章中进行了对多种模型在SOA数据集上的性能分析,揭示了新方向的可能性,并讨论了迁移学习在该数据集上的表现以及影响因素。
此外,研究者还展示了如何利用从一个任务中学到的信息来改进其他任务,展示了SOA在模型间信息共享和特征学习方面的潜力。通过扩展SOA,他们进一步探索了学习视频数据更深层次特性的可能性。
SOA数据集不仅推动了单标签分类向更全面视频理解的转变,而且也为视频分析领域的未来发展提供了丰富的资源和机遇。因此,SOA是一个重要的资源,对于视频理解技术的创新和提升具有深远的影响。关键词包括:视频数据集、多任务、场景、对象、动作等,这表明了其在计算机视觉和人工智能研究中的核心地位。
4
J. 雷,H.Wang,中国山杨D.特兰湾,澳-地Wang,M.费斯利湖
Torresani和M.Paluri
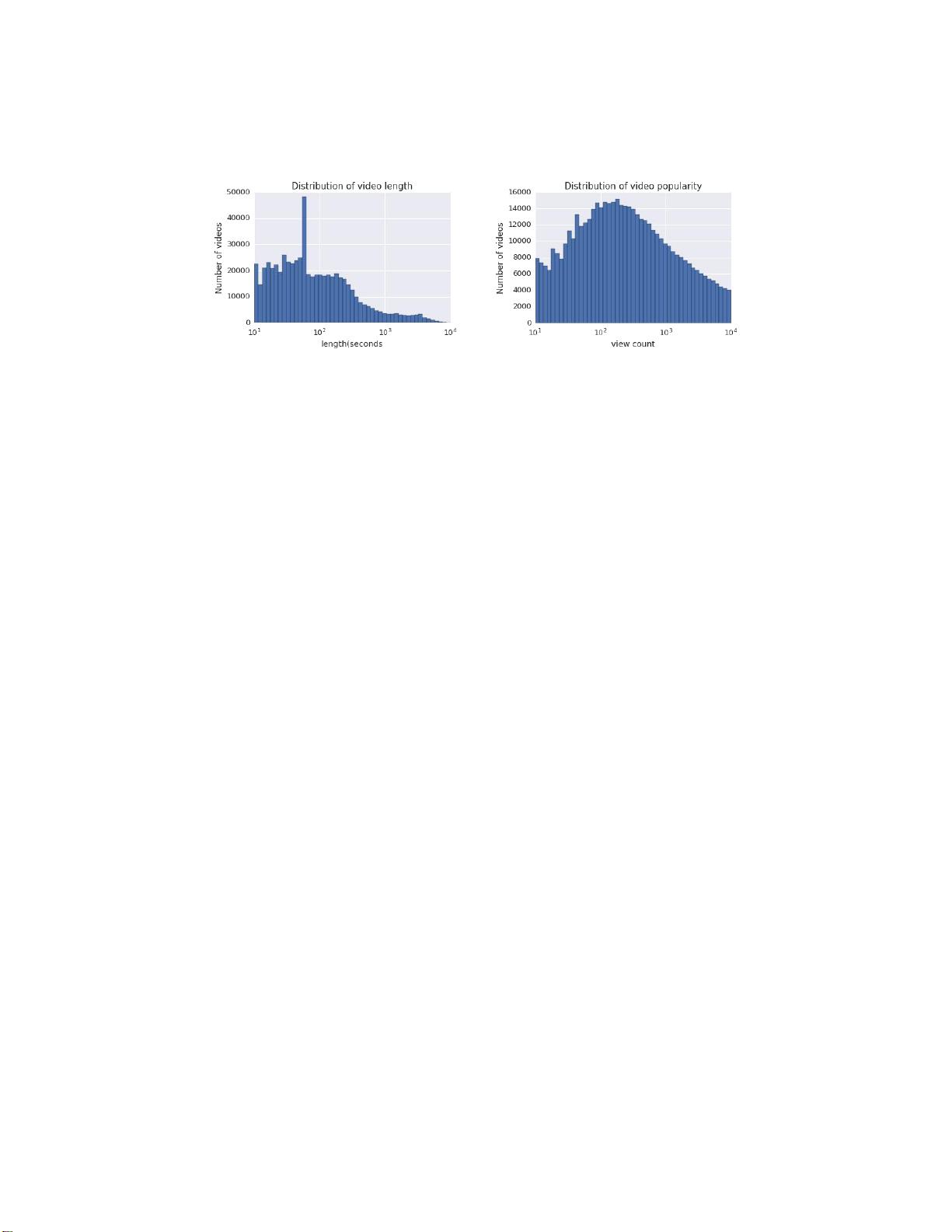
图2:采样视频的长度和视图计数的直方图这些distribu- tions包含重
尾,将丢失偏置采样。
可以回避这个问题,因为它们大多包含单标签假设合理的原型示
例。由于更接近真实分布及其包含的所有硬阳性,给定视频的内
容不再由给定标签主导。在SOA中,我们要求注释者提供尽可能
多的标签来描述识别的三个独立方面(场景,对象和动作),我
们相应地采用mAP(平均精度)作为度量标准。
2
场景-对象-动作
本节描述了SOA的创建,分为四个步骤:采样视频、开放世界注释、
生成分类法和封闭世界验证。
2.1
采样视频
我们对Facebook上共享的公开视频进行了采样。采样不受长度或视图
计数的影响。由此产生的视频是多样的,近似于互联网视频的真实分
布,如图2所示。从每个视频中,我们只采样一个大约10秒的片段,
开始时间在整个视频中均匀选择。重要的是要注意,无偏采样产生不
平衡的长尾类分布,与现有动作识别数据集中流行的动作种类相比,
更多的视频包含像“对相机说话”这样的普通标签
在收集视频之后,我们遵循用于Kinetics [19]的协议来消除SOA数
据集中的重复视频。我们唯一的修改是使用ResNet-50 [11]图像模型作
为特征提取器。我们使用相同的协议来删除与以下动作识别数据集的
测 试 和 验 证 集 相 匹 配 的 SOA 视 频 : Kinetics [19] , UCF101 [33] 和
HMDB51 [21]。
剩余16页未读,继续阅读
2023-05-25 上传
2023-07-22 上传
2023-05-13 上传
2024-01-07 上传
2023-06-10 上传
2023-06-01 上传
2023-07-14 上传
2023-06-08 上传
2023-06-02 上传

cpongm
- 粉丝: 5
- 资源: 2万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- zlib-1.2.12压缩包解析与技术要点
- 微信小程序滑动选项卡源码模版发布
- Unity虚拟人物唇同步插件Oculus Lipsync介绍
- Nginx 1.18.0版本WinSW自动安装与管理指南
- Java Swing和JDBC实现的ATM系统源码解析
- 掌握Spark Streaming与Maven集成的分布式大数据处理
- 深入学习推荐系统:教程、案例与项目实践
- Web开发者必备的取色工具软件介绍
- C语言实现李春葆数据结构实验程序
- 超市管理系统开发:asp+SQL Server 2005实战
- Redis伪集群搭建教程与实践
- 掌握网络活动细节:Wireshark v3.6.3网络嗅探工具详解
- 全面掌握美赛:建模、分析与编程实现教程
- Java图书馆系统完整项目源码及SQL文件解析
- PCtoLCD2002软件:高效图片和字符取模转换
- Java开发的体育赛事在线购票系统源码分析
