MapReduce中RepartitionJoin: 分布式环境下数据表连接详解
50 浏览量
更新于2024-08-27
收藏 393KB PDF 举报
MapReduce之Join操作在大数据处理中起着至关重要的作用,尤其是在分布式存储系统如Hadoop中。传统的关系型数据库join操作经过优化,但在海量数据场景下,MapReduce提供了新的解决方案。Join操作的核心是基于键值对的关联,这与数据库中的内连接类似,但处理方式更为分布式。
在Hadoop MapReduce框架中,join操作分为以下几个步骤:
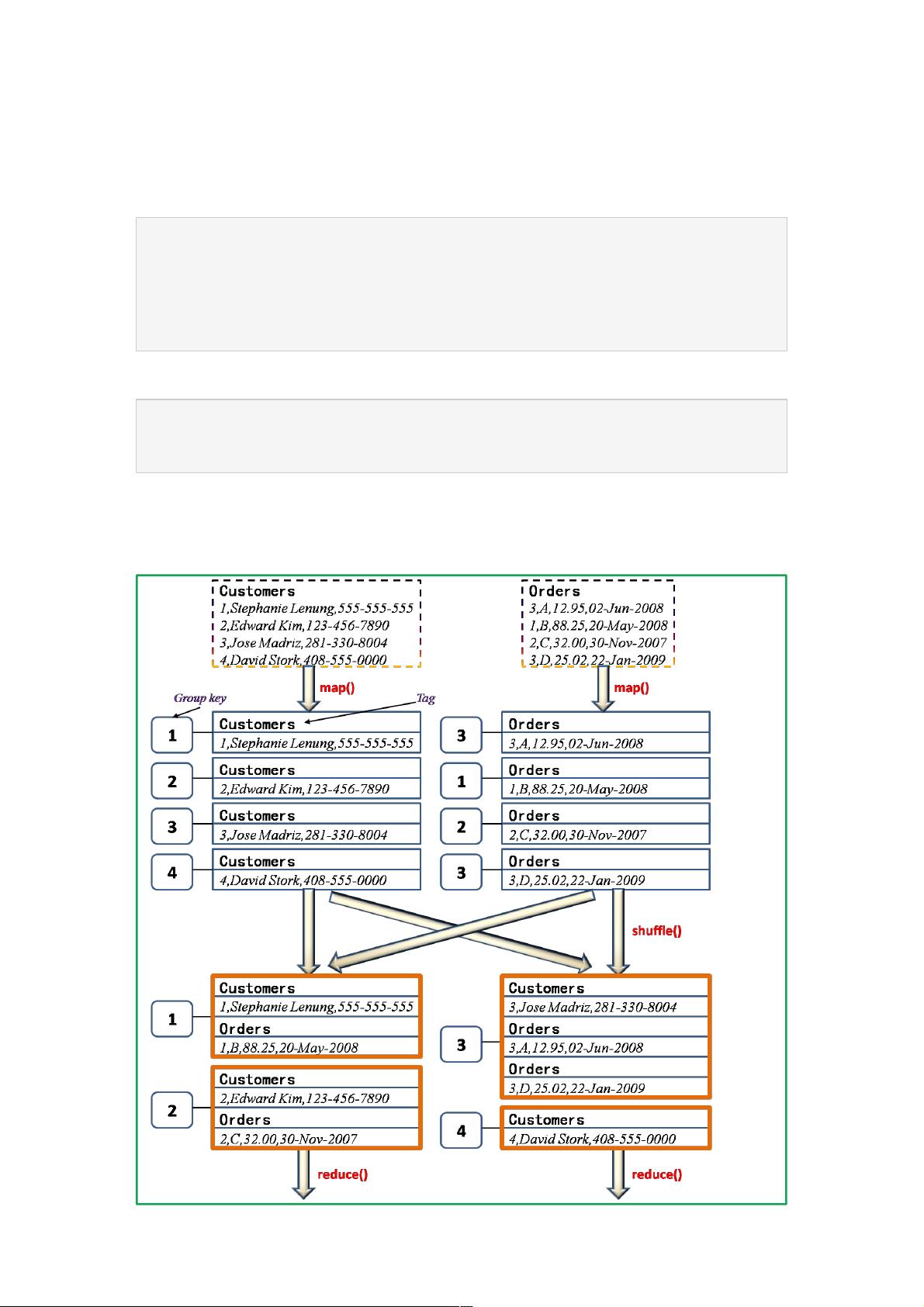
1. **数据读取与切分**:首先,Hadoop读取包含 Customers 和 Orders 数据的CSV文件,并将其分割成多个数据块,每个块独立处理。
2. **Map阶段**:在map阶段,每个mapper处理一个数据块。对于Customers表,mapper读取每一行,提取CustomerID作为键(key);对于Orders表,同样提取CustomerID作为键。这样,具有相同CustomerID的记录被映射到同一键值上。
3. **Shuffle阶段**:在这个阶段,Hadoop的Partitioner根据键(CustomerID)将map任务的输出分区,确保所有具有相同键的输出都发往同一个reduce任务。这就是所谓的repartitioning,将数据重新分配到适合执行join操作的reduce节点。
4. **Reduce阶段**:reduce函数接收来自多个mapper的所有相同键值对,并将它们合并在一起。在这个阶段,两个表中CustomerID匹配的记录被联接起来,形成新的键值对,其中包含客户信息和订单信息。
5. **输出结果**:最后,reduce任务生成并输出连接后的结果,即包含所有相关联的字段,如上述示例中的CustomerName、OrderID、OrderAmount和OrderDate。
这种方法称为Repartition Join或Hash Join,因为它利用了哈希函数将数据分布到特定的reduce任务。虽然这种方法简单直观,但它在性能上可能会受到网络通信和数据倾斜(某些reduce任务负载过重)的影响。为优化性能,可能需要考虑使用其他策略,如Broadcast Join(其中一个表的数据广播给所有reduce节点)、Sort-Merge Join(先排序后归并)或Caching Join(预先缓存小表到内存中)。这些高级技巧可以减少网络I/O和提高join效率。
《Hadoop in Action》一书中的5.2节深入探讨了这些细节,帮助读者理解如何在实际项目中选择和应用最合适的join方法。理解MapReduce的join操作对于在大数据处理中设计高效数据处理流程至关重要,特别是当面临大规模数据集时。
MapReduce之之Join操作操作
在关系型数据库中 join 是非常常见的操作,各种优化手段已经到了极致。在海量数据的环境下,不可避免的也会碰到这种类
型的需求,例如在数据分析时需要连接从不同的数据源中获取到的数据。不同于传统的单机模式,在分布式存储的下采用
MapReduce 编程模型,也有相应的处理措施和优化方法。
本文对 Hadoop 中最基本的 join 方法进行简单介绍,这也是其它许多方法和优化措施的基础。文中所采用的例子来自于《
Hadoop in Action 》一书中的 5.2 节 。假设两个表所在的文件分别为Customers和Orders,以CSV格式存储在HDFS中。
1,Stephanie Leung,555-555-5555
2,Edward Kim,123-456-7890
3,Jose Madriz,281-330-8004
4,David Stork,408-555-0000
3,A,12.95,02-Jun-2008
1,B,88.25,20-May-2008
2,C,32.00,30-Nov-2007
3,D,25.02,22-Jan-2009
这里的Customer ID是连接的键,那么连接的结果:
1,Stephanie Leung,555-555-5555,B,88.25,20-May-2008
2,Edward Kim,123-456-7890,C,32.00,30-Nov-2007
3,Jose Madriz,281-330-8004,A,12.95,02-Jun-2008
3,Jose Madriz,281-330-8004,D,25.02,22-Jan-2009
回忆一下Hadoop中MapReduce中的主要几个过程:依次是读取数据分块,map操作,shuffle操作,reduce操作,然后输出结
果。简单来说,其本质在于大而化小,分拆处理。显然我们想到的是将两个数据表中键值相同的元组放到同一个reduce结点
进行,关键问题在于如何做到?具体处理方法是将map操作输出的key值设为两表的 连接键(如例子中的Customer ID) ,那么
在shuffle阶段,Hadoop中默认的partitioner会将相同key值得map输出发送到同一个reduce结点。所以整个过程如下图所示:
下载后可阅读完整内容,剩余5页未读,立即下载
2022-08-04 上传
2023-06-02 上传
2023-06-10 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_38544781
- 粉丝: 9
- 资源: 940
 我的内容管理
展开
我的内容管理
展开







最新资源
- 正整数数组验证库:确保值符合正整数规则
- 系统移植工具集:镜像、工具链及其他必备软件包
- 掌握JavaScript加密技术:客户端加密核心要点
- AWS环境下Java应用的构建与优化指南
- Grav插件动态调整上传图像大小提高性能
- InversifyJS示例应用:演示OOP与依赖注入
- Laravel与Workerman构建PHP WebSocket即时通讯解决方案
- 前端开发利器:SPRjs快速粘合JavaScript文件脚本
- Windows平台RNNoise演示及编译方法说明
- GitHub Action实现站点自动化部署到网格环境
- Delphi实现磁盘容量检测与柱状图展示
- 亲测可用的简易微信抽奖小程序源码分享
- 如何利用JD抢单助手提升秒杀成功率
- 快速部署WordPress:使用Docker和generator-docker-wordpress
- 探索多功能计算器:日志记录与数据转换能力
- WearableSensing: 使用Java连接Zephyr Bioharness数据到服务器
