Hadoop MapReduce Join操作详解
17 浏览量
更新于2024-08-30
收藏 393KB PDF 举报
"MapReduce之Join操作"
在大数据处理领域,Hadoop MapReduce 是一种广泛使用的分布式计算框架。尽管关系型数据库中的Join操作已经被高度优化,但在处理海量数据时,使用MapReduce实现Join同样至关重要。本篇文章将探讨如何在Hadoop环境中进行基本的Join操作,并以《Hadoop in Action》一书中的例子为背景,阐述这一过程。
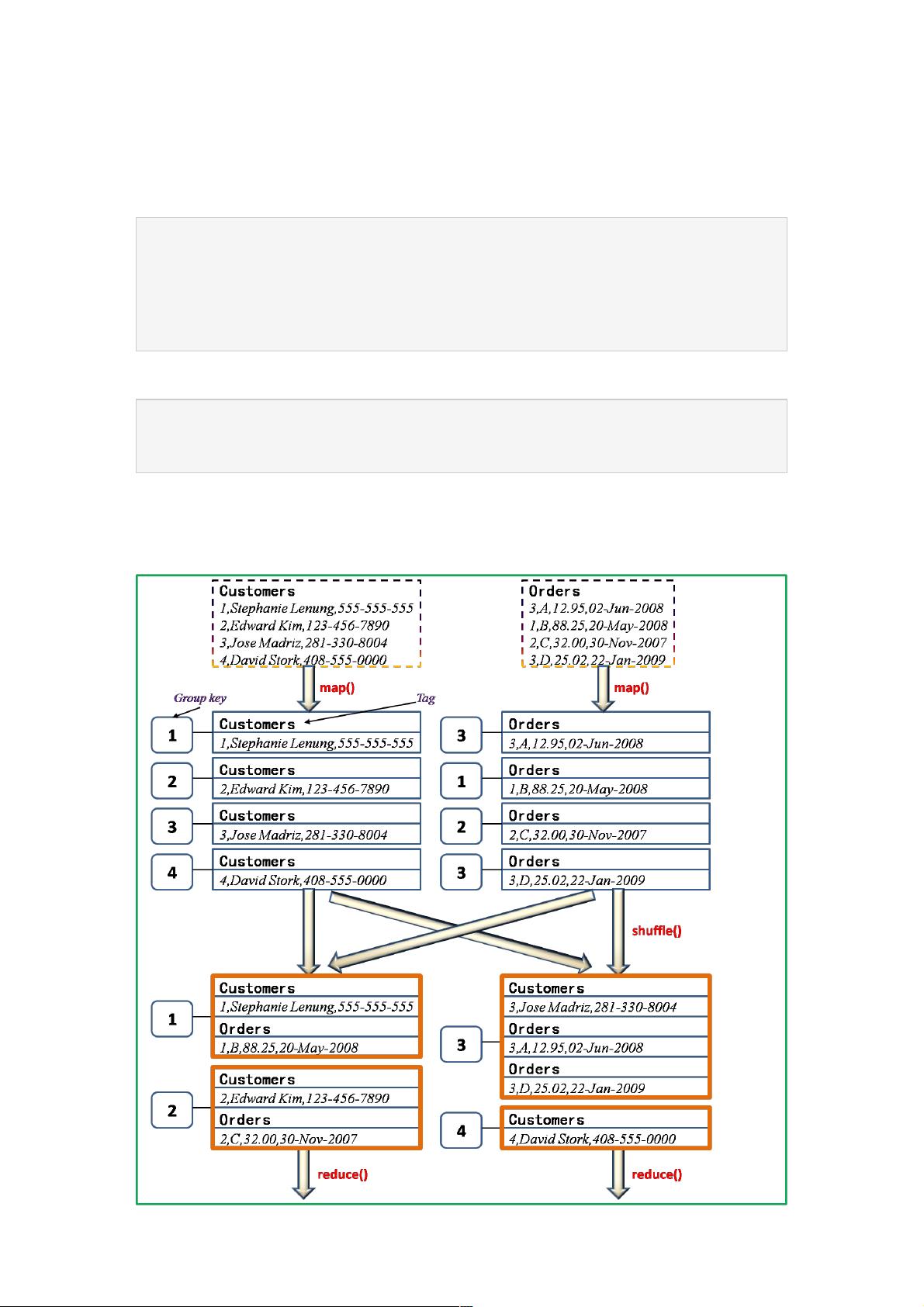
首先,我们需要理解MapReduce的基本流程,包括数据读取、映射(map)、shuffle、规约(reduce)以及最终结果的输出。在进行Join操作时,目标是将来自不同数据源的相关记录配对。在这个例子中,我们有两个表——Customers和Orders,它们都以CSV格式存储在HDFS上,且共享一个共同的键——CustomerID,用于进行连接。
在Map阶段,每个mapper读取一个数据块并处理其中的记录。对于Customers和Orders表,mapper的输出应该包含连接键(CustomerID)和对应的值。由于MapReduce的默认行为,相同key的记录会在shuffle阶段被发送到同一个reducer。因此,我们需要确保在mapper的输出中,两个表的CustomerID作为key。
在Reduce阶段,reducer接收到所有具有相同CustomerID的记录对。对于每个唯一的CustomerID,reducer可以将Customers表中的记录与Orders表中的记录匹配,生成连接后的结果。例如,CustomerID为1的记录将与OrderID为B的记录匹配,生成:
1, StephanieLeung, 555-555-5555, B, 88.25, 20-May-2008
这种方法被称为RepartitionJoin,因为它依赖于重新分区的过程来确保相同key的记录在同一个reduce任务中处理。然而,这种基础的Join策略只适用于数据量较小的情况,因为所有的数据都需要通过网络传输,可能会导致性能瓶颈。
为了优化大规模数据集的Join,Hadoop提供了一些其他策略,如BucketJoin、BlockJoin和Multi-Query Join。BucketJoin通过将数据分成固定大小的桶并在本地进行Join,减少了网络传输。BlockJoin则利用了数据的局部性,将相关数据存储在同一数据块中,减少跨节点通信。Multi-Query Join则通过一次性处理多个查询来提高效率。
在实际应用中,选择哪种Join策略取决于数据的大小、分布和计算资源。通常,需要权衡计算复杂性、内存需求和网络带宽消耗。理解这些基本概念和优化技术对于在Hadoop环境中高效处理大规模数据的Join操作至关重要。
MapReduce之之Join操作操作
在关系型数据库中 join 是非常常见的操作,各种优化手段已经到了极致。在海量数据的环境下,不可避免的也会碰到这种类
型的需求,例如在数据分析时需要连接从不同的数据源中获取到的数据。不同于传统的单机模式,在分布式存储的下采用
MapReduce 编程模型,也有相应的处理措施和优化方法。
本文对 Hadoop 中最基本的 join 方法进行简单介绍,这也是其它许多方法和优化措施的基础。文中所采用的例子来自于《
Hadoop in Action 》一书中的 5.2 节 。假设两个表所在的文件分别为Customers和Orders,以CSV格式存储在HDFS中。
1,Stephanie Leung,555-555-5555
2,Edward Kim,123-456-7890
3,Jose Madriz,281-330-8004
4,David Stork,408-555-0000
3,A,12.95,02-Jun-2008
1,B,88.25,20-May-2008
2,C,32.00,30-Nov-2007
3,D,25.02,22-Jan-2009
这里的Customer ID是连接的键,那么连接的结果:
1,Stephanie Leung,555-555-5555,B,88.25,20-May-2008
2,Edward Kim,123-456-7890,C,32.00,30-Nov-2007
3,Jose Madriz,281-330-8004,A,12.95,02-Jun-2008
3,Jose Madriz,281-330-8004,D,25.02,22-Jan-2009
回忆一下Hadoop中MapReduce中的主要几个过程:依次是读取数据分块,map操作,shuffle操作,reduce操作,然后输出结
果。简单来说,其本质在于大而化小,分拆处理。显然我们想到的是将两个数据表中键值相同的元组放到同一个reduce结点
进行,关键问题在于如何做到?具体处理方法是将map操作输出的key值设为两表的 连接键(如例子中的Customer ID) ,那么
在shuffle阶段,Hadoop中默认的partitioner会将相同key值得map输出发送到同一个reduce结点。所以整个过程如下图所示:
下载后可阅读完整内容,剩余5页未读,立即下载
2012-08-30 上传
2022-08-04 上传
2023-06-02 上传
2023-06-10 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

紫藤花叶子
- 粉丝: 286
- 资源: 888
 我的内容管理
展开
我的内容管理
展开







最新资源
- 火炬连体网络在MNIST的2D嵌入实现示例
- Angular插件增强Application Insights JavaScript SDK功能
- 实时三维重建:InfiniTAM的ros驱动应用
- Spring与Mybatis整合的配置与实践
- Vozy前端技术测试深入体验与模板参考
- React应用实现语音转文字功能介绍
- PHPMailer-6.6.4: PHP邮件收发类库的详细介绍
- Felineboard:为猫主人设计的交互式仪表板
- PGRFileManager:功能强大的开源Ajax文件管理器
- Pytest-Html定制测试报告与源代码封装教程
- Angular开发与部署指南:从创建到测试
- BASIC-BINARY-IPC系统:进程间通信的非阻塞接口
- LTK3D: Common Lisp中的基础3D图形实现
- Timer-Counter-Lister:官方源代码及更新发布
- Galaxia REST API:面向地球问题的解决方案
- Node.js模块:随机动物实例教程与源码解析
