Hadoop大数据实战:从入门到精通
需积分: 18 36 浏览量
更新于2024-07-19
1
收藏 3.11MB PDF 举报
"《孙国宇Hadoop大数据实战手册》"
本书主要涵盖了Hadoop技术的多个核心组件,包括Hadoop的入门与实践、Hadoop生态圈的介绍、HDFS文件系统的特性和操作、MapReduce计算框架的工作原理、Zookeeper的数据管理和协调、HBase分布式数据库的使用、Hive数据仓库的操作以及流式计算解决方案Storm的详解。此外,书中还涉及了数据挖掘领域的推荐系统。
在Hadoop入门与实践中,作者强调了实际应用的重要性,旨在帮助读者快速理解和掌握Hadoop,避免过多的理论探讨。书中介绍了Hadoop的版本衍化历史,展示了其发展脉络,以及Hadoop生态圈中的相关项目,如HDFS、MapReduce、YARN等。
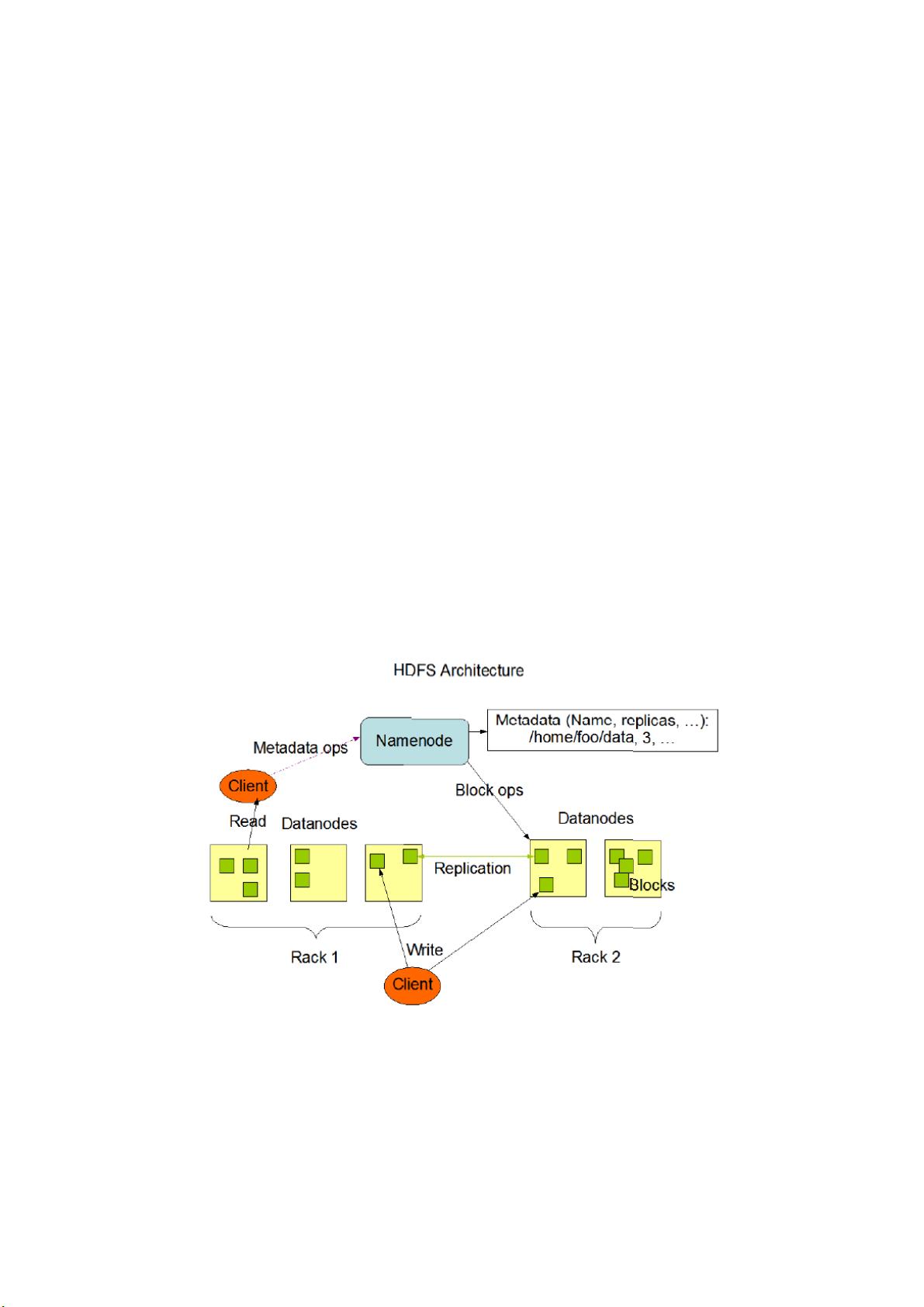
HDFS章节详细解析了Hadoop分布式文件系统的特点,例如高容错性、可扩展性和流式数据访问。同时,指出了HDFS不适合的场景,如低延迟数据访问。书中详细阐述了HDFS的体系结构,数据块复制策略,以及数据读写流程,并提供了操作HDFS的基本命令示例,便于读者进行实践操作。
MapReduce作为Hadoop的核心计算框架,书中讲解了MapReduce编程模型,如何通过Map和Reduce阶段处理数据。同时,详细描述了MapReduce的执行流程、数据本地化策略,以及错误处理机制,使读者能够深入理解并编写MapReduce程序。
Zookeeper章节则介绍了Zookeeper的数据模型、访问控制和实际应用场景,这对于分布式协调和管理至关重要。HBase部分涵盖了Hbase的基本原理、数据模型、架构及其组件,还包括容错与恢复机制,以及基础操作,帮助读者理解如何在实践中运用HBase存储和查询大数据。
Hive部分讲解了其作为数据仓库的基础原理和操作,适合于离线批处理查询。而Storm章节则对比了Storm与Hadoop的区别,阐述了Storm的实时流处理特性,包括其系统架构、容错机制以及基础配置,适合需要实时处理数据的场景。
最后,关于数据挖掘和推荐系统,书中简单介绍了数据挖掘和机器学习的概念,并重点讲解了推荐系统中基于内容和协同过滤的推荐算法,为读者提供了将数据科学应用于业务场景的思路。
这本书不仅提供了Hadoop及其相关组件的理论知识,更注重实际应用,是初学者和有经验的开发者深入了解和掌握大数据处理技术的实用指南。

6) 启动 Hadoop:
初始化:在 master 机器上,进入/home/hadoop/hadoop-1.2.1/bin 目录
在安装包根目录下运行./hadoop namenode –format来初始化hadoop的文件系统。
启动
执行./start-all.sh,如果中间过程提示要判断是否,需要输入 yes
输入 jps,查看进程是否都正常启动。
如果一切正常,应当有如上的一些进程存在。
7) 测试系统
输入./hadoop fs –ls /
能正常显示文件系统。
如此,hadoop 系统搭建完成。否则,可以去/home/hadoop/hadoop-1.2.1/logs 目
录下,查看缺少的进程中,对应的出错日志。


剩余84页未读,继续阅读
2017-12-27 上传
2023-06-09 上传
2023-04-08 上传
2023-06-07 上传
2023-06-07 上传
2024-09-14 上传
2024-06-21 上传

beyonderya
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- AccessControl-4.3-cp37-cp37m-win_amd64.whl.zip
- super-mario-master:用javascript游戏
- recommendations
- 沙发检测数据集+4600数据
- OutdoorNinjaPractice:练习需要学习的概念以实现各种功能
- vertx-copycat
- Python库 | gecosistema_lite-0.0.277.zip
- 基于ssm+vue游泳会员管理系统.zip
- Node.js-compreh,java论坛源码,看过java
- ScrollView:各种ScrollView
- ITILServiceDesk:DotNetNuke的ITIL服务台程序
- Testing-Vue.js-Applications-Book-Exercises
- STM32F429 FreeRTOS实战:实现FreeRTOS互斥信号量操作【支持STM32F42X系列单片机】.zip
- Jasmine:Jasmine 尝试实现一个相当轻量但功能强大的纯 TCP 网关
- [吉林]滨水未来派活力理想社区住宅建筑方案
- 安卓Android源码——wifi信息扫描和rssi值检测.zip
