2023年人工智能竞赛:RLHF替代方法综述与比较
需积分: 0 174 浏览量
更新于2024-08-03
收藏 1.72MB PDF 举报
在这个关于RLHF(Reinforcement Learning with Human Feedback)的平替方法汇总的PDF文档中,主要介绍了三个AI领域的研究进展,集中在如何通过强化学习的方式让语言模型更好地与人类偏好相符。这些研究主要围绕在Kaggle竞赛中应用的人工智能算法,特别是自然语言处理(NLP)领域。
1. RRHF (RankResponsestoAlignLanguageModelswithHumanFeedbackwithouttears):
阿里巴巴在2023年4月发布的方法,旨在通过在预先标记的Ranking (RM) 数据集上直接优化语言模型,使模型选择的回答概率高于拒绝的回答。这种方法的核心是引入排名损失(RankingLoss),但作者发现单纯使用此损失会导致模型性能下降,因此加入了SFT (Soft Filter) 损失。尽管在HH数据集上的表现略优于PPO,但RRHF的优势在于其简便性和稳定性。
2. PRO (PreferenceRankingOptimizationforHumanAlignment):
阿里巴巴的另一项后续工作,由非同一团队提出,PRO方法在RRHF的基础上有所改进,如增加更多的负例样本(多对比较而非一对一)以及为不同负面例子赋予不同的惩罚权重。这种方法同样结合了SFT损失,整体效果优于RLHF和RRHF。
3. DPO (DirectPreferenceOptimization):
斯坦福大学在2023年5月底的研究,DPO采用了一个直接从PPO公式出发的平替方案,注重稳定性,同时考虑了SFT模型的约束。DPO在多个RM数据集上的实验显示出较低的超参数敏感性,效果更为稳定,并且在奖励得分上超越了RLHF。此外,微软在同年10月的论文中进一步探讨了DPO,关注排序数据的成本问题,并可能对其进行了优化。
这些研究展示了如何通过结合不同的强化学习策略、定制化负例处理和约束机制,提高语言模型在遵循人类偏好方面的性能。这些工作对于理解和改进人工智能在生成式对话系统中的应用具有重要意义,特别是在Kaggle竞赛这样的平台上,它们代表了当前AI研究人员在探索人机交互和模型伦理方面的重要进展。
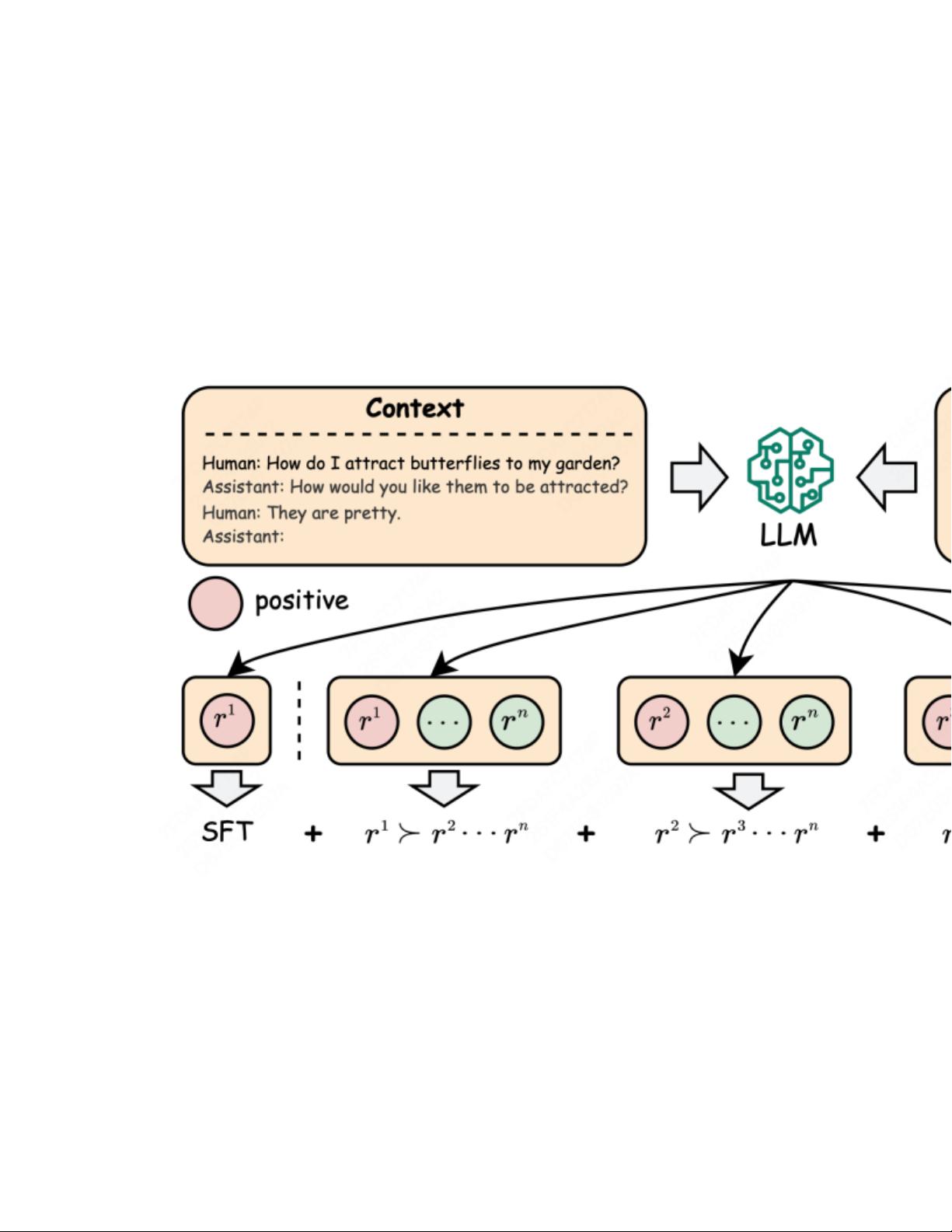
3. 循环执行2,类似强化的思维不断靠自身采样到更好的答案
最后的结论也比较符合直接,是3>2>1。
Preference Ranking Optimization for Human Alignment
后续阿里(非同作者)在2023.06又提出了一个PRO方法,核心思想跟RR
HF接近,但有两个不同:
1. 选用了更多负例,不止停留在pair-wise
2. 给不同负例不同的惩罚项(比如分数差的多就拉大一些)
PRO
同时也加上了SFT loss,最终效果比RLHF和RRHF都有些提升。
DPO
Direct Preference Optimization:Your Language Model is
Secretly a Reward Model
剩余13页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2023-03-31 上传
2023-10-18 上传
2024-07-03 上传
2023-12-06 上传
2024-02-06 上传
2024-02-06 上传


白话机器学习
- 粉丝: 1w+
- 资源: 7670
 我的内容管理
展开
我的内容管理
展开







