MongoDB索引详解:提升查询效率的关键
196 浏览量
更新于2024-08-30
收藏 122KB PDF 举报
本文主要介绍了MongoDB的索引概念及其重要性,并通过一个简单的示例展示了在大量数据中没有索引和使用索引查询的性能差异。
MongoDB的索引是一种用于快速查找文档的数据结构,它类似于传统图书的目录,能够帮助数据库系统高效地定位和检索数据。如果没有索引,MongoDB需要对整个集合进行全盘扫描,逐个检查文档以找到匹配查询条件的记录,这种操作在数据量大的情况下会非常慢。相反,如果创建了索引,MongoDB就能够直接跳转到目标位置,显著提高查询速度。
在提供的演示中,首先执行了一个脚本`insertUsers`,向名为`users`的集合中插入了100万条数据。每条数据包含`userid`、`username`、`age`和`createdate`四个字段,其中`username`是基于`wjg`加编号生成的随机字符串,`age`是0到99之间的随机整数,`createdate`是当前时间。插入这100万条数据耗时约8分钟,这显示了大量数据操作对系统资源的影响。
接下来,演示了未使用索引查询特定`username`的过程。使用`find`方法并添加`explain("allPlansExecution")`参数,可以查看查询计划和执行统计。结果显示,查询过程执行了全集合扫描(`COLLSCAN`),没有使用任何索引,因此检查了全部100万条文档,耗时865毫秒才找到匹配的记录。
在实际应用中,为了优化查询性能,应当为频繁查询的字段创建索引。例如,如果经常根据`username`字段进行查询,可以创建如下的索引:
```javascript
db.users.createIndex({ username: 1 })
```
这将为`username`字段建立升序索引。创建索引后,再次执行相同的查询,MongoDB将利用索引来快速定位目标文档,显著减少查询时间。
总结来说,MongoDB的索引对于大数据集的查询性能至关重要。合理地创建和使用索引能够提高查询效率,降低系统资源消耗。同时,理解如何使用`explain`命令分析查询计划有助于优化数据库的性能。在处理大规模数据时,应结合业务需求和查询模式,适时建立和维护索引,以实现最佳的数据库性能。
MongoDB的索引的索引
1、简介、简介
它就像是一本书的目录,如果没有它,我们就需要对整个书籍进行查找来获取需要的结果,即所说的全盘扫描;
而有了目录(索引)之后就可以通过它帮我们定位到目标所在的位置,快速的获取我们想要的结果。
2、演示、演示
第一步,向用户集合users中插入100W条数据
var insertUsers = function() {
var start = new Date().getTime();
for (var i = 1; i <= 1000000; i++) {
db.users.insert({
"userid": i,
"username": "wjg" + i,
"age": Math.floor(Math.random() * 100), //年龄为0~99的随机整数
"createdate": new Date()
})
}
var end = new Date().getTime();
print("插入100W条数据共耗时" + (end - start) / 1000 + "秒");
}
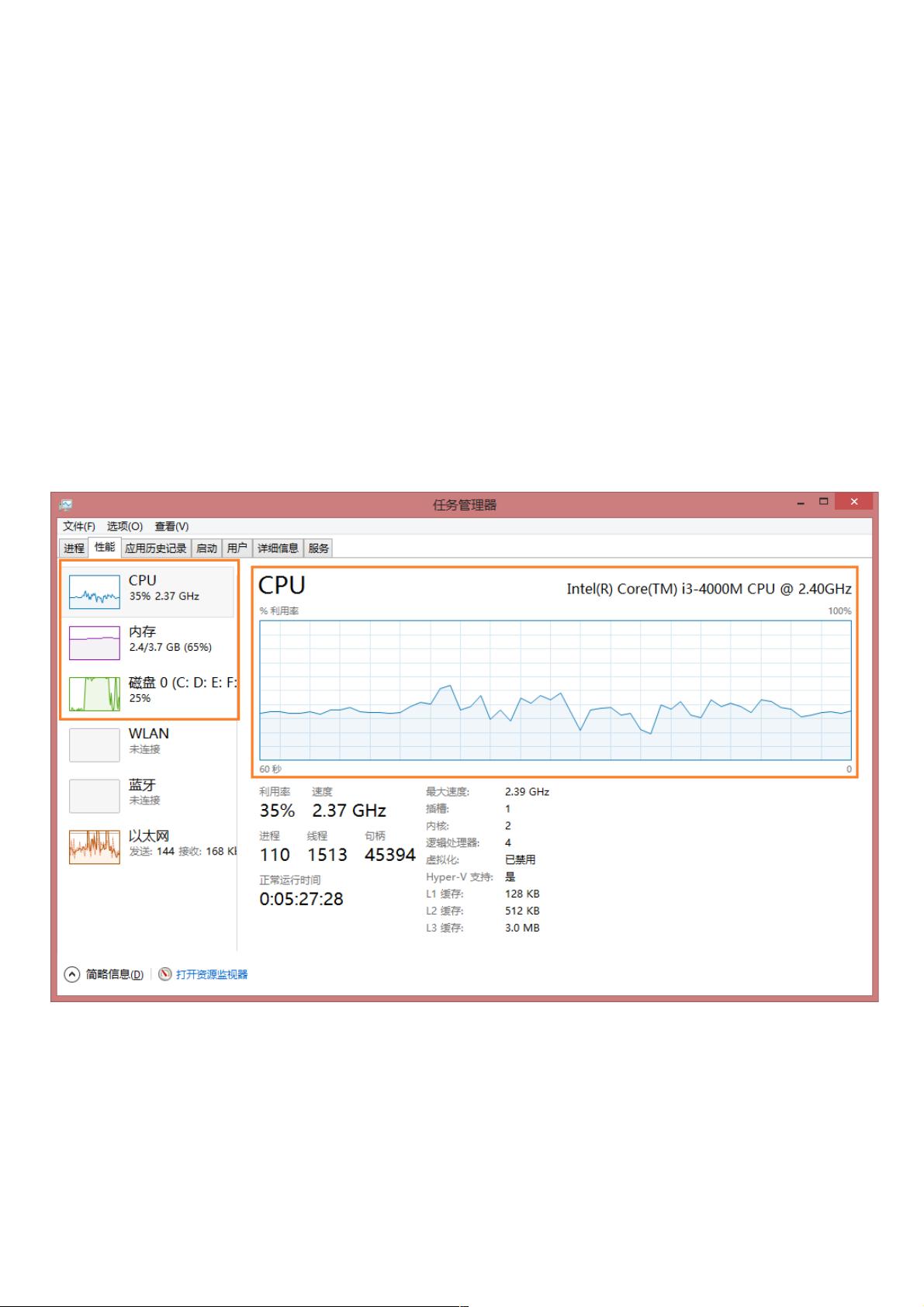
LZ的渣渣I3和4G内存总共耗时了484.623秒,约8分多钟。任务管理器里边可以很清楚的看到当时CPU、内存和磁盘使用率都普遍的增
高。
第二步:查询用户名为“wjg465413”的文档对象
db.users.find({username:"wjg465413"}).explain("allPlansExecution")
{
"queryPlanner" : {
"plannerVersion" : 1,
"namespace" : "test.users",
"indexFilterSet" : false,
"parsedQuery" : {
"username" : {
"$eq" : "wjg465413"
}
},
"winningPlan" : {
"stage" : "COLLSCAN",
"filter" : {
"username" : {
下载后可阅读完整内容,剩余3页未读,立即下载
129 浏览量
142 浏览量
275 浏览量
231 浏览量
2022-07-11 上传
2022-07-11 上传
2022-07-11 上传
131 浏览量
2023-06-10 上传

weixin_38734276
- 粉丝: 11
- 资源: 901
 我的内容管理
展开
我的内容管理
展开







最新资源
- FonePaw_Video_Converter_Ultimate_2.9.0.93447.zip
- 162100头像截图程序 4.1
- subclass-dance-party
- JavaScript:Curso完成JavaScript
- Medical_Payment_Classification:确定医疗付款是用于研究目的还是用于一般用途
- P1
- javascript-koans
- 保险行业培训资料:寿险意义与功用完整版本
- ChandyMishraHaasOrAlgo
- maven-repo
- react-as-space
- eclipse-inst-mac64.dmg.zip
- bearsunday.github.io
- ks
- lazytoby.github.io
- 0.96寸OLED(IIC接口)显示屏的图像显示应用
