机器翻译入门:方法、挑战与现状解析
版权申诉
本资源是北京大学语言学课程系列的一部分,专注于自然语言处理技术,特别是机器翻译的概述。课程适合希望深入理解或回顾自然语言处理基础知识的学生,包括对机器学习、数据平滑、分词、模型如n元模型、ME&CRF、深度学习等的讲解。机器翻译是课程中的一个重要章节,它介绍了机器翻译的定义和研究目标,即开发能够自动将一种自然语言(源语言)转化为另一种自然语言(目标语言)的计算机程序,以实现语言间的无障碍交流。
机器翻译研究的挑战在于创造全自动、高质量的机器翻译(FAHQMT),尽管至今尚未实现这一理想,但它仍然是一个持续的研究领域。课程详细讨论了机器翻译的不同方法,如:
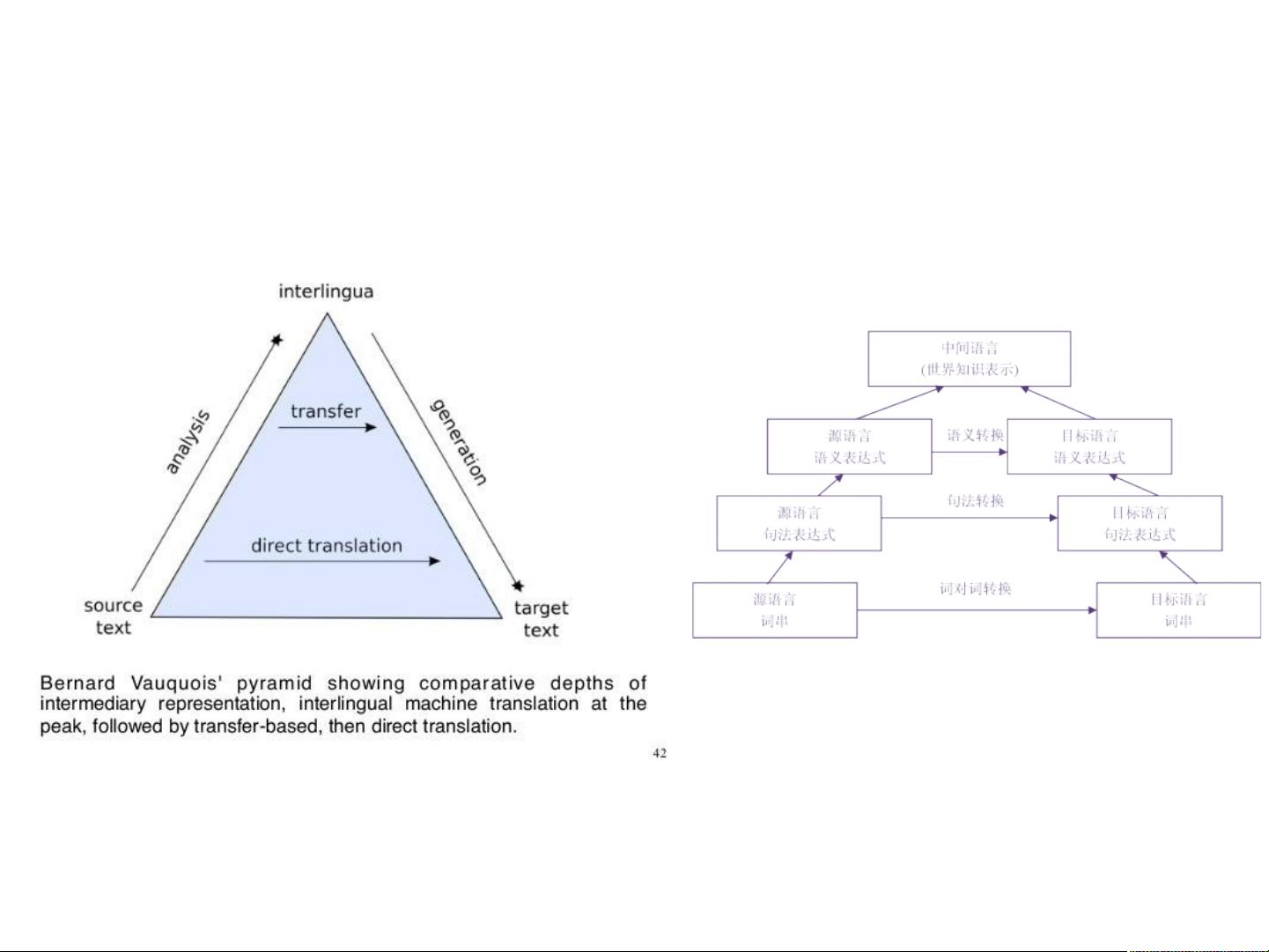
1. 基于规则的方法:早期主要采用直接翻译法,逐词翻译,但这种方法忽视了语言间的差异,导致翻译质量较低。中间语言法提出通过构建一种独立于具体语言的中间表示来解决这个问题,虽然理论上有优势,但在实践中由于中间语言定义困难且技术需求高,没有显著的成功案例。
2. 转换法:这是一种更为商业化的策略,首先分析源语言文本,将其转换为目标语言的内部表示,然后生成目标语言文本。这种方法涉及使用不同层次的内部表示,如浅层句法或深层语义表示,已有一些商品化规则机器翻译系统采用此法。
3. 基于语料库的机器翻译:这种方法依赖大量的双语平行语料库,通过统计分析找出语言之间的模式,虽然不能保证完美,但可以提供实用的翻译结果。
4. 神经机器翻译:这是近年来发展起来的一种先进方法,利用深度学习模型,尤其是循环神经网络(RNN)和Transformer架构,能够捕捉到更复杂的语言结构,是当前研究的热点。
值得注意的是,尽管各种方法都有其局限性,机器翻译的发展一直在不断进步,每种方法都在一定程度上推动了我们对语言结构和翻译过程的理解。课程提供的资源不仅有助于入门者建立坚实的基础,也为进阶研究者提供了丰富的理论背景和实践案例。全套课程链接可供下载,以便学生按需学习和深入探索。
机器翻译的基本方法
基于规则的翻译方法图示

剩余44页未读,继续阅读
2022-04-26 上传
2022-04-26 上传
点击了解资源详情
2022-04-26 上传
2022-02-03 上传
点击了解资源详情
2021-08-15 上传
2022-04-26 上传
2022-04-26 上传

passionSnail
- 粉丝: 452
- 资源: 6944
 我的内容管理
展开
我的内容管理
展开







最新资源
- 探索数据转换实验平台在设备装置中的应用
- 使用git-log-to-tikz.py将Git日志转换为TIKZ图形
- 小栗子源码2.9.3版本发布
- 使用Tinder-Hack-Client实现Tinder API交互
- Android Studio新模板:个性化Material Design导航抽屉
- React API分页模块:数据获取与页面管理
- C语言实现顺序表的动态分配方法
- 光催化分解水产氢固溶体催化剂制备技术揭秘
- VS2013环境下tinyxml库的32位与64位编译指南
- 网易云歌词情感分析系统实现与架构
- React应用展示GitHub用户详细信息及项目分析
- LayUI2.1.6帮助文档API功能详解
- 全栈开发实现的chatgpt应用可打包小程序/H5/App
- C++实现顺序表的动态内存分配技术
- Java制作水果格斗游戏:策略与随机性的结合
- 基于若依框架的后台管理系统开发实例解析
