
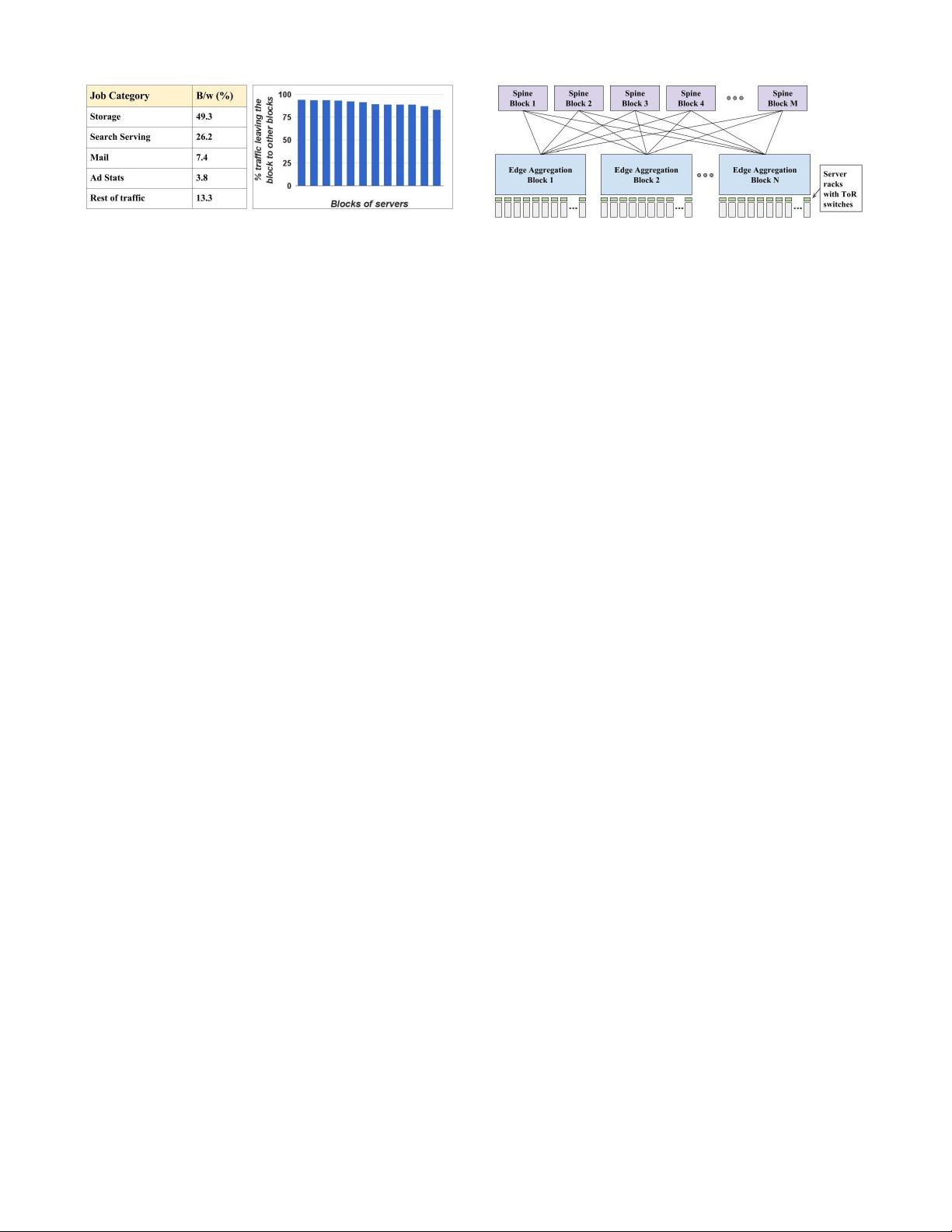
Figure 3: Mix of jobs in an example cluster with 12 blocks
of servers (left). Fraction of traffic in each block destined
for remote blocks (right).
width applications had to fit under a single ToR to
avoid the heavily oversubscribed ToR uplinks. Deploy-
ing large clusters was important to our services because
there were many affiliated applications that benefited
from high bandwidth communication. Consider large-
scale data processing to produce and continuously re-
fresh a search index, web search, and serving ads as
affiliated applications. Larger clusters also substan-
tially improve bin-packing efficiency for job scheduling
by reducing stranding from cases where a job cannot
be scheduled in any one cluster despite the aggregate
availability of sufficient resources across multiple small
clusters.
Maximum cluster scale is important for a more sub-
tle reason. Power is distributed hierarchically at the
granularity of the building, multi-Megawatt power gen-
erators, and physical datacenter rows. Each level of hi-
erarchy represents a unit of failure and maintenance.
For availability, cluster scheduling purposely spreads
jobs across multiple rows. Similarly, the required re-
dundancy in storage systems is in part determined by
the fraction of a cluster that may simultaneously fail as
a result of a power event. Hence, larger clusters lead to
lower storage overhead and more efficient job scheduling
while meeting diversity requirements.
Running storage across a cluster requires both rack
and power diversity to avoid correlated failures. Hence,
cluster data should be spread across the cluster’s failure
domains for resilience. However, such spreading natu-
rally eliminates locality and drives the need for uni-
form bandwidth across the cluster. Consequently, stor-
age placement and job scheduling have little locality in
our cluster traffic, as shown in Figure 3. For a rep-
resentative cluster with 12 blocks (groups of racks) of
servers, we show the fraction of traffic destined for re-
mote blocks. If traffic were spread uniformly across the
cluster, we would expect 11/12 of the traffic (92%) to
be destined for other blocks. Figure 3 shows approxi-
mately this distribution for the median block, with only
moderate deviation.
While our traditional cluster network architecture
largely met our scale needs, it fell short in terms of
overall performance and cost. Bandwidth per host was
severely limited to an average of 100Mbps. Packet drops
associated with incast [8] and outcast [21] were severe
Figure 4: A generic 3 tier Clos architecture with edge
switches (ToRs), aggregation blocks and spine blocks. All
generations of Clos fabrics deployed in our datacenters fol-
low variants of this architecture.
pain points. Increasing bandwidth per server would
have substantially increased cost per server and reduced
cluster scale.
We realized that existing commercial solutions could
not meet our scale, management, and cost requirements.
Hence, we decided to build our own custom data center
network hardware and software. We started with the
key insight that we could scale cluster fabrics to near
arbitrary size by leveraging Clos topologies (Figure 4)
and the then-emerging (ca. 2003) merchant switching
silicon industry [12]. Table 1 summarizes a number of
the top-level challenges we faced in constructing and
managing building-scale network fabrics. The following
sections explain these challenges and the rationale for
our approach in detail.
For brevity, we omit detailed discussion of related
work in this paper. However, our topological approach,
reliance on merchant silicon, and load balancing across
multipath are substantially similar to contemporaneous
research [2,15]. In addition to outlining the evolution of
our network, we further describe inter cluster network-
ing, network management issues, and detail our control
protocols. Our centralized control protocols running on
switch embedded processors are also related to subse-
quent substantial efforts in Software Defined Network-
ing (SDN) [13]. Based on our experience in the dat-
acenter, we later applied SDN to our Wide Area Net-
work [19]. For the WAN, more CPU intensive traffic
engineering and BGP routing protocols led us to move
control protocols onto external servers with more plen-
tiful CPU from the embedded CPU controllers we were
able to utilize for our initial datacenter deployments.
Recent work on alternate network topologies such as
HyperX [1], Dcell [17], BCube [16] and Jellyfish [22]
deliver more efficient bandwidth for uniform random
communication patterns. However, to date, we have
found that the benefits of these topologies do not make
up for the cabling, management, and routing challenges
and complexity.
3. NETWORK EVOLUTION
3.1 Firehose 1.0
Table 2 summarizes the multiple generations of our
剩余14页未读,继续阅读

xu23heng
- 粉丝: 0
- 资源: 3
 我的内容管理
展开
我的内容管理
展开







最新资源
- zlib-1.2.12压缩包解析与技术要点
- 微信小程序滑动选项卡源码模版发布
- Unity虚拟人物唇同步插件Oculus Lipsync介绍
- Nginx 1.18.0版本WinSW自动安装与管理指南
- Java Swing和JDBC实现的ATM系统源码解析
- 掌握Spark Streaming与Maven集成的分布式大数据处理
- 深入学习推荐系统:教程、案例与项目实践
- Web开发者必备的取色工具软件介绍
- C语言实现李春葆数据结构实验程序
- 超市管理系统开发:asp+SQL Server 2005实战
- Redis伪集群搭建教程与实践
- 掌握网络活动细节:Wireshark v3.6.3网络嗅探工具详解
- 全面掌握美赛:建模、分析与编程实现教程
- Java图书馆系统完整项目源码及SQL文件解析
- PCtoLCD2002软件:高效图片和字符取模转换
- Java开发的体育赛事在线购票系统源码分析
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


