Scrapy-Redis分布式爬虫架构解析
需积分: 0 165 浏览量
更新于2024-08-04
收藏 239KB DOCX 举报
"3.3_Srcapy+redis架构1"
Scrapy-Redis是一个扩展了Scrapy框架的组件,利用Redis作为中间件来实现分布式爬虫的功能。在传统的Scrapy框架中,虽然已经具备强大的网页抓取和数据提取能力,但面对大规模的数据爬取时,单机性能的局限性会变得明显,这时就需要采用分布式爬虫来提高效率和处理能力。
Scrapy-Redis的引入解决了这个问题。它的核心思想是通过Redis这个内存数据结构存储服务来管理待爬取的URL队列,确保所有分布式爬虫节点共享同一队列。每个节点从Redis中获取待爬取的URL,执行爬取任务,然后将结果存回Redis或直接保存到数据库。这样不仅实现了请求的去重,还能够根据Redis的特性实现高效的数据同步和调度。
在Scrapy-Redis架构中,Redis作为中央调度器,负责存储待爬取的Request对象,这些对象包含URL和相关的元数据。每个Scrapy爬虫实例都可以从Redis中取出Request,执行HTTP请求,然后解析响应内容,提取Items(结构化数据)和新的Requests。Items被发送到另一个Redis队列,等待进一步处理,如持久化存储。新的Requests再次进入爬取队列,整个过程形成一个循环。
Scrapy-Redis的工作流程大致如下:
1. **请求调度**:所有爬虫节点将待爬取的URL放入Redis的Request队列,Redis负责调度这些请求,确保每个节点公平地获取任务。
2. **去重机制**:Redis可以通过集合(Set)或者有序集合(Sorted Set)来避免重复爬取同一个URL,保证数据的唯一性。
3. **请求分发**:每个节点从Redis中取出Request,执行网络请求,避免了多个节点同时爬取相同URL的情况,提高了并发效率。
4. **结果处理**:Scrapy-Redis将解析得到的Items放入另一个Redis队列,以便后续处理或直接写入数据库。
5. **分布式扩展**:由于Redis和Scrapy-Redis的结合,系统可以根据需要添加更多的爬虫节点来提升抓取速度,达到分布式爬虫的效果。
在源代码层面,Scrapy-Redis重写了Scrapy的部分核心模块,如Scheduler和DupeFilter,使其能够与Redis通信。尽管Scrapy-Redis的代码量不多,但它有效地整合了Scrapy的爬虫逻辑和Redis的分布式特性,使得开发者可以专注于爬虫逻辑本身,而无需过多关注分布式系统的复杂性。
总结来说,Scrapy-Redis是Scrapy框架的分布式扩展,通过Redis实现URL队列的共享和去重,提高了大规模数据爬取的效率和可扩展性。理解其工作原理和架构对于构建高效、可靠的分布式爬虫系统至关重要。
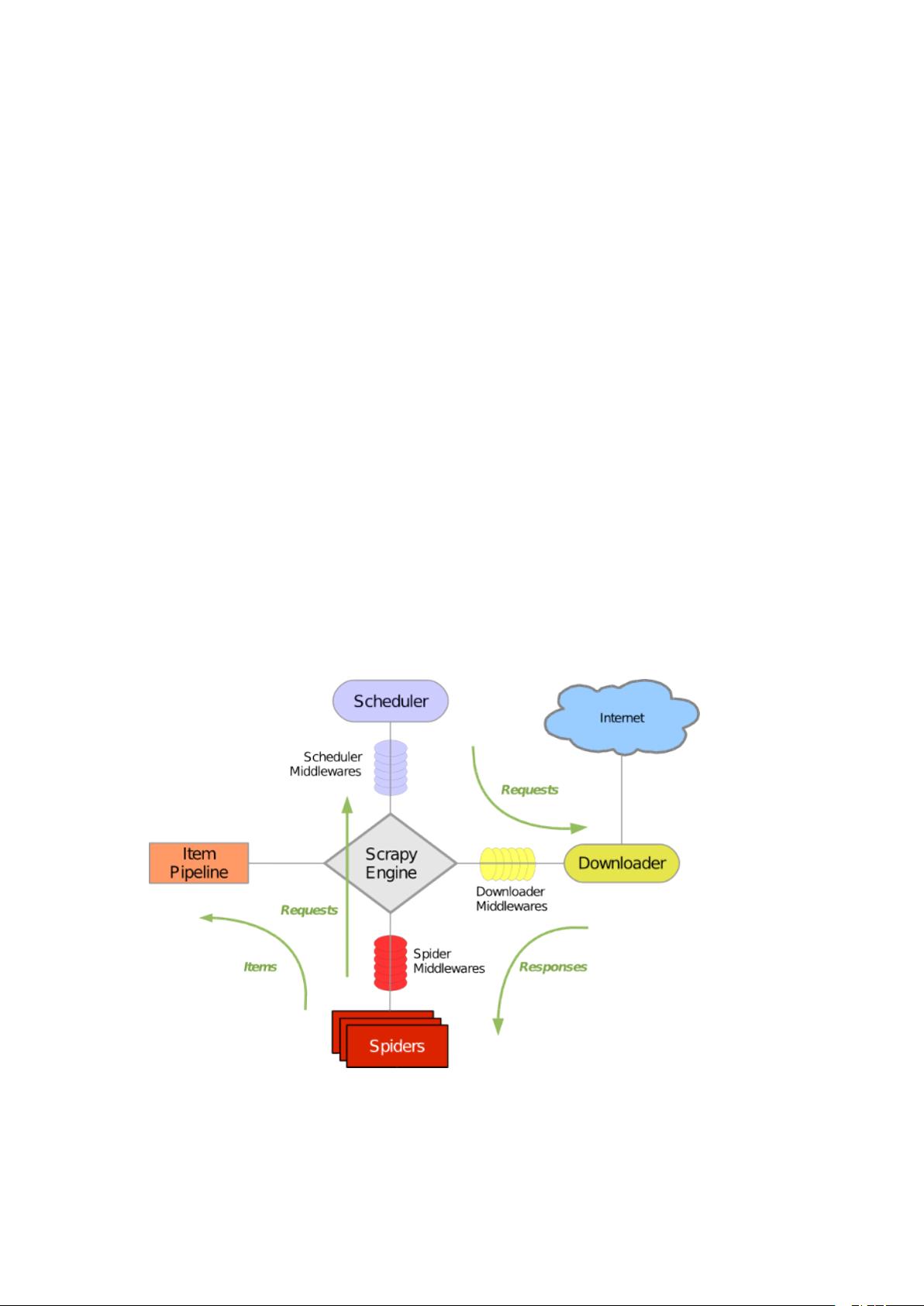
3.3Scrapy-redis 架构
为什么使用 Scrapy+redis 架构:
Scrapy,Python 开发的一个快速,高层次的屏幕抓取和 web 抓取框架,用于
抓取 web 站点并从页面中提取结构化的数据。Scrapy 用途广泛,可以用于数据
挖掘、监测和自动化测试。
Scrapy 框架已经可以完成很大的一部分爬虫工作了。但是如果遇到比较大规模
的数据爬取,直接可以用上 python 的多线程/多进程,如果你拥有多台服务器,
分布式爬取是最好的解决方式,也是最有效率的方法。
Scrapy-redis 是基于 redis 的一个 scrapy 组件,scrapy-redis 提供了维持待爬
取 url 的去重以及储存 requests 的指纹验证。原理是:redis 维持一个共同的 url
队列,各个不同机器上的爬虫程序获取到的 url 都保存在 redis 的 url 队列,各
个爬虫都从 redis 的 URL 队列获取 url,并把数据统一保存在同一个数据库里面。
3.3.1Scrapy+Redis 架构定义:
Scrapy 是一个比较好用的 Python 爬虫框架,你只需要编写几个组件就可以
实现网页数据的爬取。但是当我们要爬取的页面非常多的时候,单个主机的处理
能力就不能满足我们的需求了(无论是处理速度还是网络请求的并发数),这时
候分布式爬虫的优势就显现出来。
而 Scrapy-Redis 则是一个基于 Redis 的 Scrapy 分布式组件。它利用 Redis
对用于爬取的请求(Requests)进行存储和调度(Schedule),并对爬取产生的项目
(items)存储以供后续处理使用。scrapy-redis 重写了 scrapy 一些比较关键的
代码,将 scrapy 变成一个可以在多个主机上同时运行的分布式爬虫。
原生的 Scrapy 的架构是这样子的:
scrapy-redis 的官方文档写的比较简洁,没有提及其运行原理,所以如果想
全面的理解分布式爬虫的运行原理,还是得看 scrapy-redis 的源代码才行,不
过 scrapy-redis 的源代码很少,也比较好懂,很快就能看完。
scrapy-redis 工程的主体还是 redis 和 scrapy 两个库,工程本身实现的东西
下载后可阅读完整内容,剩余3页未读,立即下载
2022-07-07 上传
2024-09-22 上传
2021-10-02 上传
2018-11-19 上传
2021-02-05 上传
2021-05-15 上传
210 浏览量
2022-11-18 上传

巴蜀明月
- 粉丝: 42
- 资源: 301
 我的内容管理
展开
我的内容管理
展开







最新资源
- 管理系统系列--用C#(ADO.NET)实现的一个简单的图书管理系统.zip
- food-delivery:带有React Native的送餐应用
- smart-triage:在COVID-19期间加快医院患者分诊的解决方案
- 开发人员如何转型项目经理
- Android半透明3D图像显示源代码
- 电子功用-多功能充电插排
- Mezzanit.Hoard-开源
- Java进阶高手课-必知必会MySQL
- 【转】STM32系统板设计,打样验证可以使用-电路方案
- graduate-datascientist:数据科学,大数据,数据分析和人工人工智能(机器学习,深度学习,神经网络)
- MTA-SA
- Chat-Socket-Java:聊天系统ServerSocket e Socket na linguagem Java
- django-tastypie-backbone-todo-tutorial:将待办事项从 API 读取到主干应用程序的教程示例应用程序
- python实例-07 抖音表白.zip源码python项目实例源码打包下载
- learning_JS
- react-tmdb:TMDb
