应用驱动:百度林仕鼎解析数据中心计算的未来
需积分: 10 47 浏览量
更新于2024-07-25
收藏 1.35MB PDF 举报
在第五届中国云计算大会上,百度的林仕鼎分享了关于"应用驱动的数据中心计算"的主题。他强调了数据中心计算如何从搜索引擎的基本原理出发,利用流式处理、内存记录以及日志基础结构来优化数据处理和存储。这种计算模式的核心在于:
1. **应用驱动**:数据中心的设计和架构应紧密围绕实际应用需求,确保计算资源的高效利用,而不是单纯追求技术层面的先进性。
2. **Stream Block结构**:系统采用流式数据块(Stream Block)作为基本存储单元,通过In-Memory Records快速处理实时和非结构化数据,同时支持批量Commit和高吞吐量的存储模型。
3. **Log-based结构**:日志机制被用来处理写入、更新和合并操作,通过LogBlock和LogX记录数据变化,保证数据一致性,同时减少文件系统和RAID的复杂性。
4. **无文件系统设计**:通过去除传统文件系统,直接进行Direct I/O,实现更高效的磁盘访问,降低I/O层次,最大化并行度。
5. **数据交换与重组**:为了提高性能和效率,系统采用Merge-Sort对数据进行排序,并通过SortedStream生成中间表,进一步通过Merge操作整合数据,形成Table。
6. **分布式存储体系**:系统设计了一个包括基础数据块(BaseStream)、修改流(ModStream)、索引流(IndexStream)和补丁流(PatchStream)在内的多层次结构,允许在不同层次进行分区和复制,以平衡复杂度和可靠性。
7. **分区和复制策略**:确定在哪个层次进行分区和复制粒度的选择至关重要,需要考虑性能、数据分布和可靠性之间的权衡。
8. **分布式挑战与优势**:转变为分布式系统意味着更高的扩展性和容错能力,但同时也带来了额外的Commit开销。然而,通过本地I/O的优势,可以显著提升整体性能。
9. **可靠性与成本**:虽然分布式系统增加了复杂性,但提高了数据的可靠性和可用性。需要在系统设计时充分评估这些因素,以确保整体系统的性价比。
林仕鼎在会议上探讨了如何通过应用驱动的方法,优化数据中心的计算模型,以满足不断增长的数据处理需求,同时兼顾性能、可扩展性和可靠性。这种技术在现代云计算环境中扮演着关键角色,对于理解数据中心基础设施的优化和演进具有重要意义。
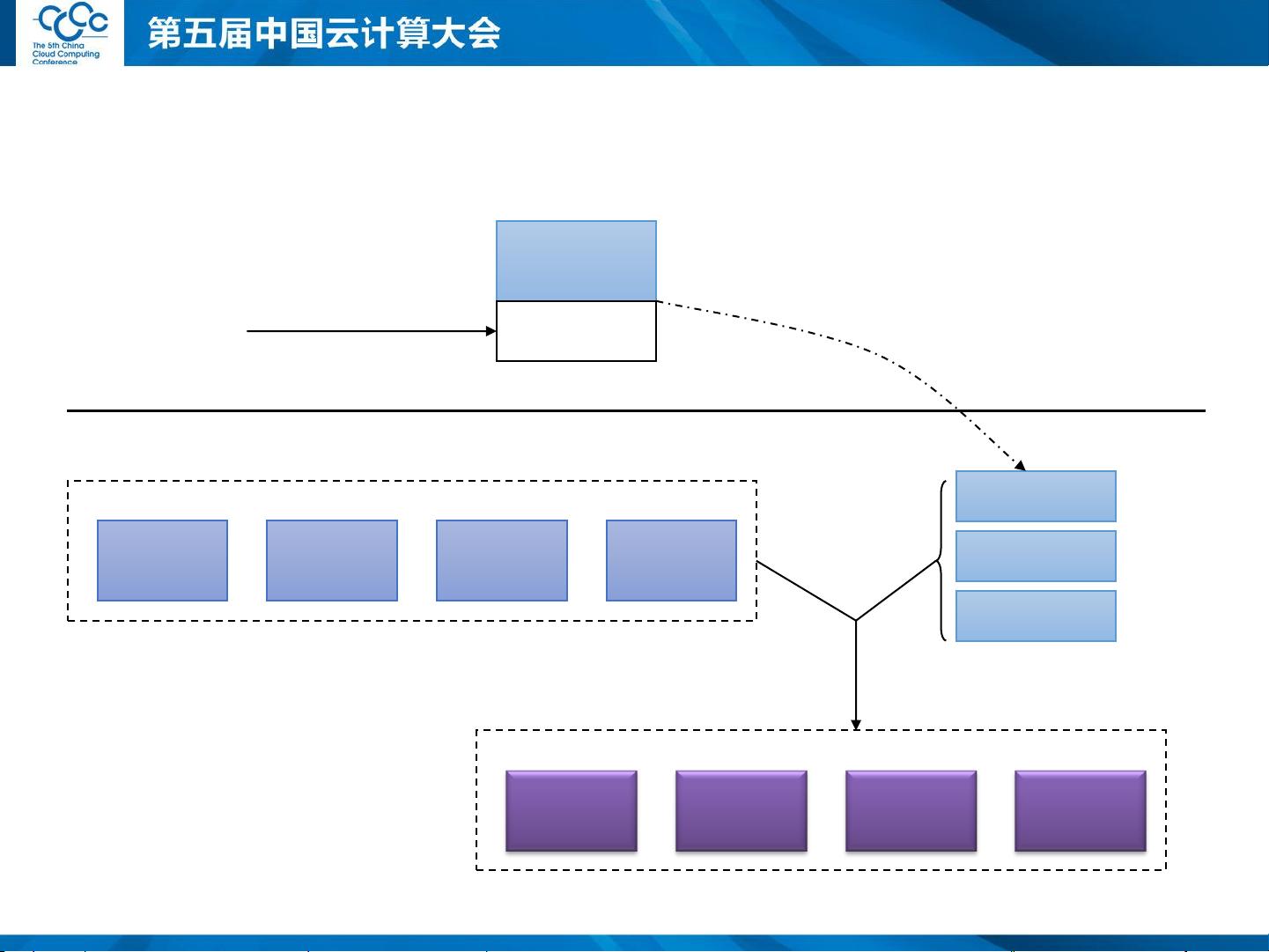
Data1 Data2 … DataN
Log
Record
…
LogX
Log1
Data blocks
New data blocks
Merge-sort
Dump
通过Merge-Sort生成Sorted Stream
Memory
Disk
Data1’ Data2’ … DataM’
剩余20页未读,继续阅读
2013-06-16 上传
2014-05-29 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

战歌IT
- 粉丝: 122
- 资源: 2405
 我的内容管理
展开
我的内容管理
展开







最新资源
- 前端面试必问:真实项目经验大揭秘
- 永磁同步电机二阶自抗扰神经网络控制技术与实践
- 基于HAL库的LoRa通讯与SHT30温湿度测量项目
- avaWeb-mast推荐系统开发实战指南
- 慧鱼SolidWorks零件模型库:设计与创新的强大工具
- MATLAB实现稀疏傅里叶变换(SFFT)代码及测试
- ChatGPT联网模式亮相,体验智能压缩技术.zip
- 掌握进程保护的HOOK API技术
- 基于.Net的日用品网站开发:设计、实现与分析
- MyBatis-Spring 1.3.2版本下载指南
- 开源全能媒体播放器:小戴媒体播放器2 5.1-3
- 华为eNSP参考文档:DHCP与VRP操作指南
- SpringMyBatis实现疫苗接种预约系统
- VHDL实现倒车雷达系统源码免费提供
- 掌握软件测评师考试要点:历年真题解析
- 轻松下载微信视频号内容的新工具介绍
