入门指南:XPath+BeautifulSoup实战教程
需积分: 49 130 浏览量
更新于2024-07-15
收藏 2.93MB PDF 举报
本资源是一份关于Python爬虫的详细学习资料,主要关注于数据提取技术,特别是通过正则表达式、XPath和BeautifulSoup库进行操作。爬虫数据提取是网络数据抓取的重要部分,对于理解网页结构和提取关键信息至关重要。
**1. 正则表达式基础**
这部分介绍了正则表达式的单字符匹配(如`a`匹配任何单个'a'字符)、多字符匹配(如`.html`匹配任何包含'.html'的字符串),以及一些基本的模式匹配概念,如开始、结束、贪婪和非贪婪匹配。正则表达式在数据清洗和筛选过程中扮演着核心角色,尤其是在处理文本数据时。
**2. XPath语法与应用**
XPath是一种强大的查询语言,用于XML和HTML文档中的信息检索。主要内容包括如何在谷歌浏览器上安装XPath插件(如XPathHelper和TryXPath),以及XPath节点类型(元素、属性、文本等)的深入理解。XPath语法中的谓语(如`[@lang='en']`)是关键,它用于定位具有特定属性值的节点。同时,课程还讲解了`/`(仅获取子节点)和`//`(获取所有子孙节点)的区别,这对于处理不同层级的HTML结构至关重要。
**3. BeautifulSoup4库**
BeautifulSoup4是一个用于解析HTML和XML文档的Python库,是数据抓取中的常用工具。课程首先介绍了BeautifulSoup的基本概念,然后深入讲解了四种常见对象(如`Tag`、`NavigableString`等)的使用方法。通过实战,学员可以学习如何使用BeautifulSoup爬取豆瓣电影Top250的数据。
**4. 实战案例**
课程提供了丰富的实战案例,如爬取赶集网租房信息和糗事百科段子,这些例子展示了如何将理论知识应用到实际场景中。通过这些实例,学生能够掌握如何结合正则表达式和XPath进行数据抓取,并能编写出高效、稳定的爬虫脚本。
这份笔记为初学者提供了一个从基础到进阶的Python爬虫教程,通过理论与实践相结合的方式,帮助读者理解和掌握数据抓取的关键技术,为数据分析师、网站开发者和SEO优化人员提供实用技能。无论是对新手还是有一定经验的开发者,都能从中受益匪浅。
BeautifulSoup4库的基本了解
BeautifulSoup4库
和 lxml 一样,Beautiful Soup 也是一个HTML/XML的解析器,主要的功能
也是如何
解析和提取 HTML/XML 数据。
lxml 只会局部遍历,而Beautiful Soup 是基于HTML DOM(Document Object
Model)的,会载入整个文档,解析整个DOM树,因此时间和内存开销都会大
很多,
所以性能要低于lxml。
Beautiful Soup 3 目前已经停止开发,推荐现在的项目使用Beautiful Soup 4。
中文文档:
https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html
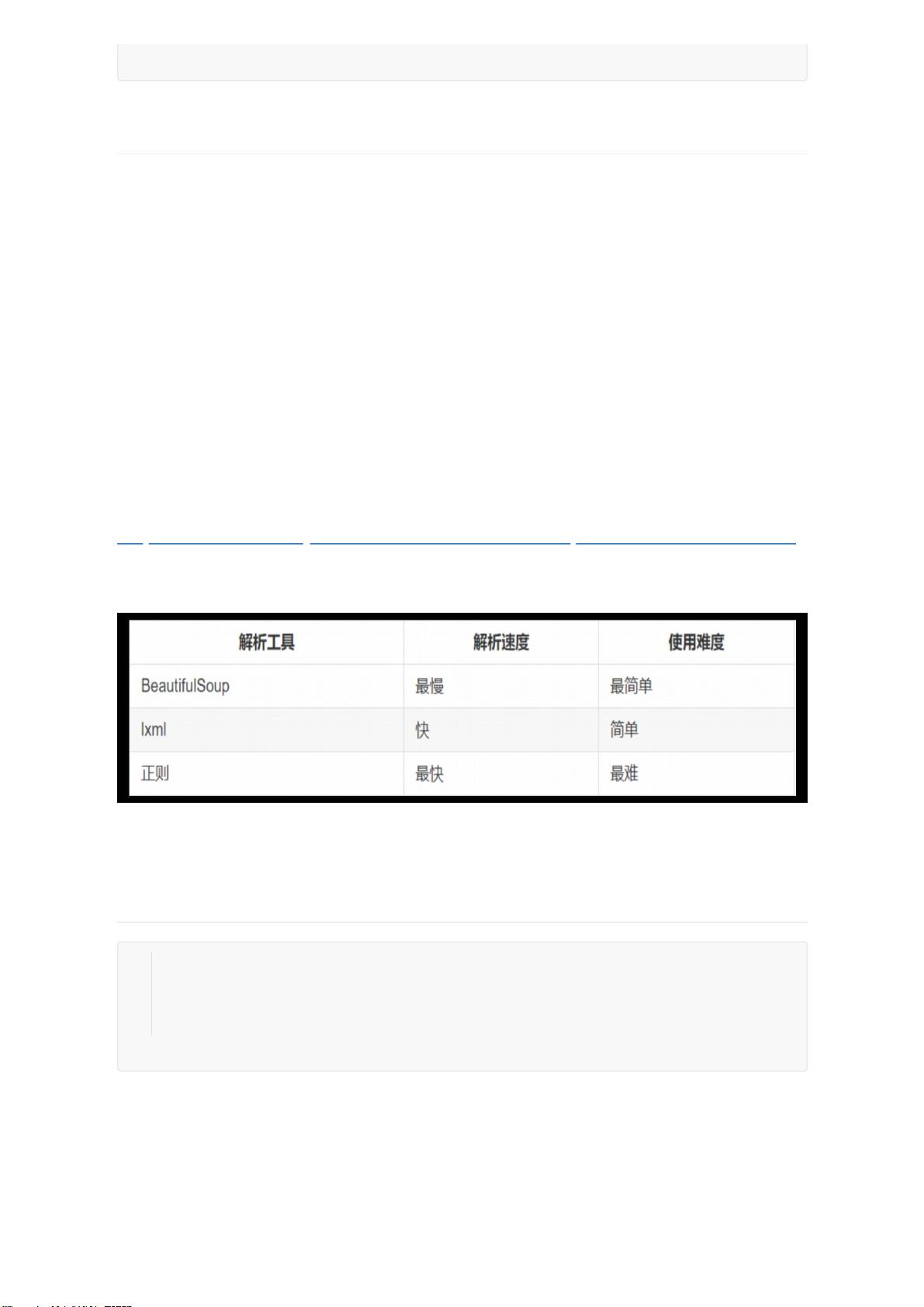
几大解析工具的对比
BeautifulSoup4库的基本使用
save(info, f)59
from bs4 import BeautifulSoup #导入库包
soup = BeautifulSoup(html,'lxml') ## 创建 Beautiful Soup 对
象,使用lxml来进行解析
print(soup.prettify()) #使数据看着美化
1
2
3
剩余23页未读,继续阅读
2019-07-09 上传
2021-06-28 上传
2021-06-28 上传
2022-07-10 上传
2022-11-23 上传
2022-11-23 上传
2019-12-09 上传

习惯了一个人面对所有
- 粉丝: 16
- 资源: 5
 我的内容管理
展开
我的内容管理
展开







