Java容器深度解析:从基础到高级
96 浏览量
更新于2024-09-01
收藏 120KB PDF 举报
"Java容器全览,包括基础概念和常用数据结构"
在Java编程中,容器是用来存储对象的集合,提供了灵活的数据管理方式。本文主要介绍Java中的各种容器,包括它们的基本特性和使用场景。
首先,我们要理解的是泛型。泛型是Java SE 5.0引入的一个重要特性,它允许在定义类、接口或方法时,指定一个或多个类型参数,使得容器在运行时能够适应多种类型的元素。例如,`ArrayList<E>`就是一个泛型类,其中的`E`代表元素类型,可以在实例化时指定,如`ArrayList<String>`或`ArrayList<Integer>`。这样做的好处是提高了代码的类型安全性和效率,避免了强制类型转换。
接下来,我们讨论`Comparable`和`Comparator`。`Comparable`是一个接口,实现了这个接口的类可以进行自然排序。比如,`Integer`、`String`等类都实现了`Comparable`接口,它们之间的比较可以通过`compareTo`方法完成。返回值规则是:负数表示小于,零表示等于,正数表示大于。而`Comparator`是一个可以自定义比较逻辑的接口,它提供了`compare`方法,可以根据实际需求定制比较规则。
容器主要分为两大类:集合(Collection)和映射(Map)。集合又分为List、Set和Queue。
1. **List**:有序、可重复的元素集合。常见的List实现有`ArrayList`、`LinkedList`和`Vector`:
- `ArrayList`基于动态数组,适用于随机访问,插入和删除效率相对较低。
- `LinkedList`是链表实现,适合于频繁的插入和删除操作,但随机访问效率低。
- `Vector`与`ArrayList`类似,但它是线程安全的,性能稍逊。
2. **Set**:无序、不重复的元素集合。常见的Set实现有`HashSet`、`LinkedHashSet`和`TreeSet`:
- `HashSet`是基于哈希表实现的,不保证元素顺序,不允许重复元素。
- `LinkedHashSet`保留了插入顺序,也遵循了`HashSet`的基本特性。
- `TreeSet`使用红黑树实现,保证元素按特定顺序排列,支持`Comparable`或通过`Comparator`定制排序。
3. **Queue**:用于处理先进先出(FIFO)的元素序列。常见的Queue实现有`LinkedList`(作为队列使用)、`ArrayQueue`和`PriorityQueue`:
- `ArrayQueue`基于固定大小的数组,空间效率高,但不支持并发。
- `PriorityQueue`是一个优先级队列,元素根据其自然顺序或自定义`Comparator`进行排序。
4. **Stack**:栈是一种后进先出(LIFO)的数据结构,Java中的`Stack`类是`Vector`的子类,提供了基本的栈操作。
5. **Map**:存储键值对的容器。常见的Map实现有`HashMap`、`TreeMap`和`ConcurrentHashMap`:
- `HashMap`提供快速的查找,基于哈希表实现,不保证迭代顺序。
- `TreeMap`使用红黑树,按照键的自然顺序或`Comparator`进行排序,保证迭代顺序。
- `ConcurrentHashMap`是线程安全的Map,适合多线程环境。
遍历容器的方法主要有两种:`Iterator`和`ListIterator`。`Iterator`适用于遍历任何集合,而`ListIterator`只适用于List,它提供了更丰富的操作,如向前和向后移动,以及修改元素的能力。
`Collections`是一个工具类,提供了大量对集合进行操作的静态方法,如排序、搜索、填充等。需要注意的是,`Collections`和`Collection`是不同的概念,前者是工具类,后者是集合框架的顶级接口。
总结来说,Java容器提供了丰富多样的数据结构,满足不同场景的需求,理解并熟练运用这些容器,可以极大地提升代码的灵活性和效率。在实际开发中,选择合适的容器类型并正确使用泛型、`Comparable`和`Comparator`,对于优化程序性能和保持代码整洁至关重要。
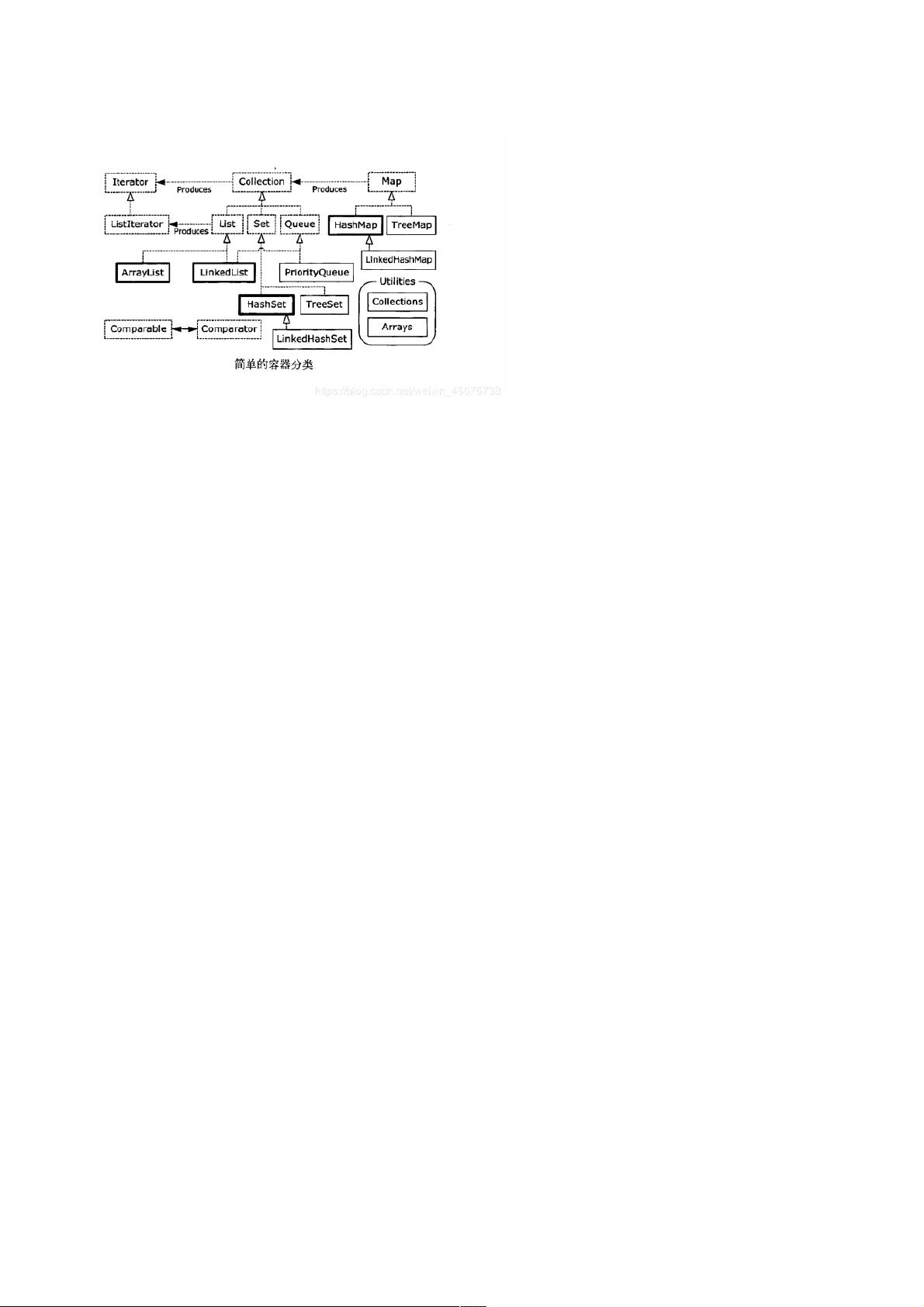
java容器大全(容器大全(java基础篇)基础篇)
java容器介绍容器介绍
本文目录本文目录java容器介绍泛型的简单介绍Comparable和
ComparatorCollectionListArrayListLinkedListVectorSetHashSetLinkedHashSet+ComparableTreeSetQueueLinkedListArrayQueuePriorityQueueStackMapHashMapTreeMap
容器的遍历Iterator+listIterator遍历List方法一Iterator遍历List方法二listIterator遍历Set遍历Map方式一遍历Map方式二Collections是工具类不要Collection混淆
本文将会一一介绍图中的容器
泛型的简单介绍泛型的简单介绍
容器中泛型出现频率有点高,所以先介绍介绍泛型。当参数类型不确定,或者要经常变动时就可以用泛型来解决。直接看代码就可以了解泛型的用法。
注意泛型接口只能给泛型类来实现。泛型对泛型
public class GenericDemo {
//在类名后面加上代表E是编译时给什么类型就什么类型
//可以把E看作对像
static class A{
private E name;
public E getName() {
return name;
}
public void setName(E name) {
this.name = name;
}
}
// 泛型定义在方法上
public static void demo01(E e){
};
// 泛型定义在方法上 返回值也是泛型
public static E demo02(E e){
return e;
};
public static void main(String[] args) {
//这么new A类中的E就代表是String
//?问号代表通配符
A a1 = new A();
//这么new A类中的E就代表是Integer
a1= new A();
//如果不用通配符 只能定义两个变量
A a = new A();
A b = new A();
}
}
Comparable和和Comparator
Comparable可以认为是一个内比较器,实现了Comparable接口的类有一个特点,就是这些 类是可以和自己比较的。一般用在类去实现其接口,实现compareTo方法。返回
值负数:小于,0:等于,正数:大于。
Comparator。是外比较器。一般用于作为参数传达。如sort(,,)。要怎么排序就用到了Comparator接口。要实现compare方法。返回值负数:小于,0:等于,正数:
大于。
Collection
从文章开头的图可知Collection接口被List,set,Queue接口给继承了。所以Collection有的方法List和Set也有。先介绍其基本的方法
import java.util.ArrayList;
import java.util.Collection;
public class CollectionDemo {
public static void main(String[] args) {
//需要选择一个实现Collection的接口。
Collection c1 = new ArrayList();
//add();往里面加一个函数
c1.add("张三");
c1.add("李四");
Collection c2 = new ArrayList();
//add();往里面加一个函数
c2.add("zhangsan");
c2.add("lisi");
//获取集合的长度
下载后可阅读完整内容,剩余5页未读,立即下载









