GPU加速分析:Apache Spark上的数据处理革命
需积分: 5 26 浏览量
更新于2024-06-21
1
收藏 7.15MB PDF 举报
“藏经阁-LEVERAGING GPU-ACCELERATED ANA.pdf”是一份关于利用GPU加速Apache Spark上数据分析的文档,由MapD的创始人兼CEO Todd Mostak在2017年6月6日发表。该文档探讨了GPU在处理日益增长的数据量时相比CPU的优势,并介绍了MapD Core和MapD Immerse两款软件产品,它们是为高速硬件优化的内存数据库和可视化分析引擎。
在当前的信息时代,数据的增长速度远超CPU计算能力的提升。CPU每年的性能提升大约为20%,而数据量的增长达到了40%。这种不对称性导致了计算的瓶颈,GPU(图形处理器)的出现提供了一条前进的道路。GPU的处理能力每年提升约50%,同时具备更高的内存带宽,这使得它们在处理大量数据时的性能优于CPU。GPU不仅在浮点运算能力上有显著优势,还具有强大的数据读取能力,这对于数据密集型应用来说至关重要。
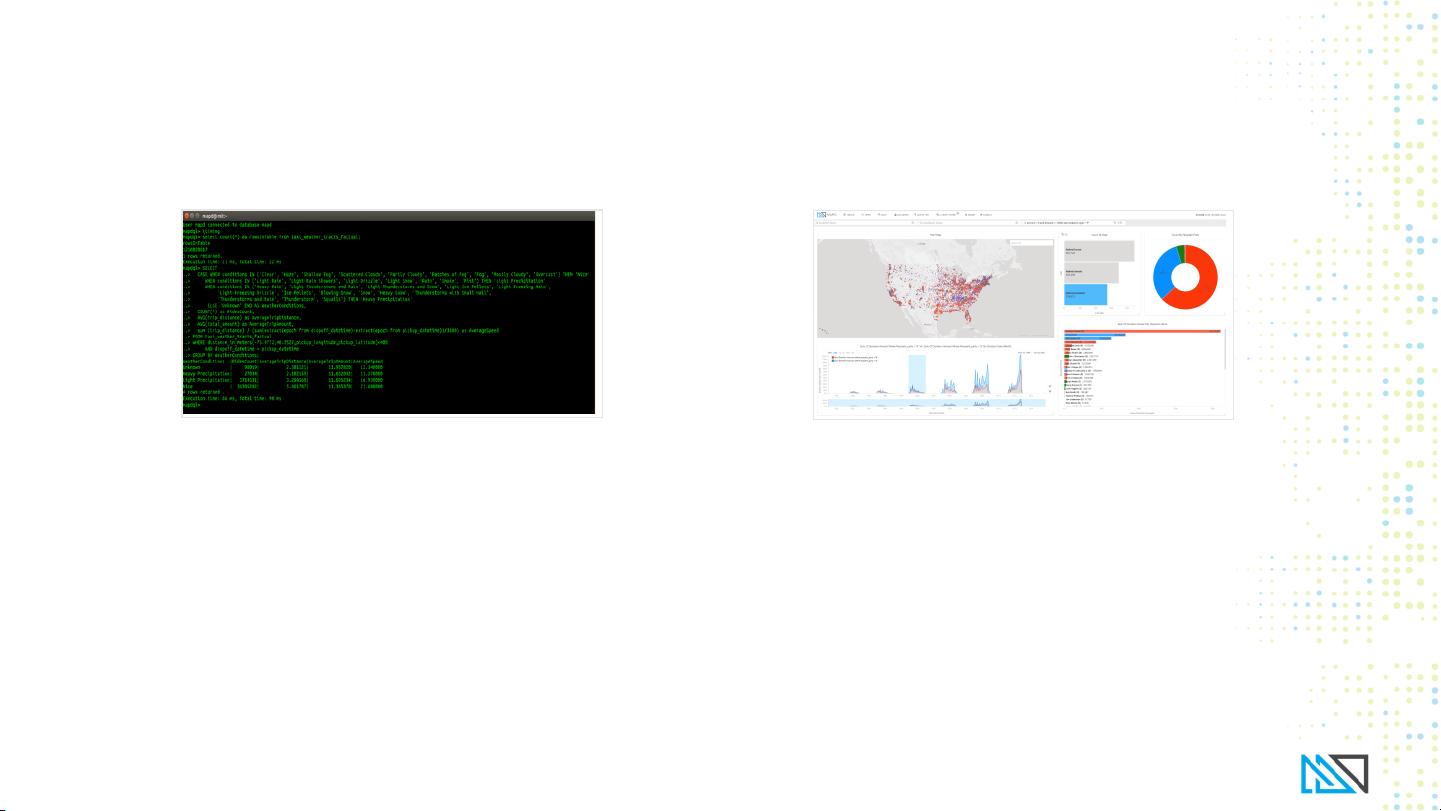
MapD Core是一款基于GPU的内存数据库系统,设计用于应对大数据的挑战。它利用GPU的并行计算能力,实现了比传统CPU数据库快100倍的查询速度,真正实现了“思维速度”的数据分析。这款软件将数据以列式存储,从而更高效地处理分析任务。
MapD Immerse则是一个视觉分析引擎,它充分利用MapD Core的速度和渲染能力,提供实时、交互式的数据可视化。用户可以通过MapD Immerse进行快速的数据探索,与Tableau或其他第三方可视化工具集成,或者通过JDBC和Hadoop接口进行非可视化输出。
此外,MapD在数据流处理领域也有一席之地,能够处理实时数据流,提供即时分析结果。这种结合GPU加速和Apache Spark的能力,使得MapD成为大数据分析领域的一个创新解决方案,尤其适用于需要高性能计算和快速响应时间的应用场景。
总结来说,这份文档揭示了GPU在大数据分析中的潜力,以及MapD如何利用GPU技术优化Apache Spark上的数据分析和可视化,为用户提供前所未有的快速体验。通过MapD Core和MapD Immerse,企业和分析师可以更快地获取洞察,更好地应对海量数据的挑战。
5
MapD Core MapD Immerse
MapD: software optimized for the fastest hardware
An in-memory, relational, column
store database powered by GPUs
A visual analytics engine that
leverages the speed + rendering
capabilities of MapD Core
+
100x Faster Queries Speed of Thought Visualization
剩余23页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2023-08-26 上传
2023-09-01 上传
2023-09-09 上传
2023-08-26 上传

weixin_40191861_zj
- 粉丝: 87
- 资源: 1万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- 高质量c++ c编程指南
- WPF技术白皮书 下一代互联网主流开发技术
- 整合Flex和Java--配置篇.pdf
- unix 编程艺术指导
- 词法分析器的设计与实现
- TD7.6管理员指南
- ACE Programming Guide
- 手机游戏门户网站建设方案
- 搜索引擎技术手工索引
- 衡水信息港投资计划书 网站建设方案
- 地方门户网站策划书(转载)
- [计算机科学经典著作].SAMS.-.Tricks.Of.The.Windows.Game.Programming.Gurus.-.Fundamentals.Of.2D.And.3D.Game.Programming.[eMule.ppcn.net].pdf
- Embedded_Linux_on_ARM.pdf
- SQL语言艺术(英文版)
- Windows File Systems _FAT16, FAT32, NTFS_.pdf
- C Programming Language 2nd Edition(K & R).pdf
