"藏经阁:深入了解SPARK的可扩展数据科学"
需积分: 5 179 浏览量
更新于2024-03-16
收藏 663KB PDF 举报
In the document "藏经阁-SCALABLE DATA SCIENCE.pdf" authored by Felix Cheung, Principal Engineer at Microsoft, the concept of scalable data science with Spark is explored in depth. Spark, a powerful distributed computing framework, is increasingly being utilized for its ability to handle large datasets and streamline the data science process.
The document delves into the key features and advantages of Spark, highlighting its ability to process data in memory and efficiently distribute workloads across a cluster of machines. This enables data scientists to perform complex analyses on massive datasets with speed and precision.
Cheung discusses the various components of Spark, including Spark Core, Spark SQL, and MLlib, each of which plays a crucial role in the data processing pipeline. These tools provide a unified platform for data manipulation, querying, and machine learning, simplifying the data science workflow and allowing for seamless integration of different tasks.
Furthermore, the document explores practical applications of Spark in the realm of data science, demonstrating how it can be used to solve real-world problems in industries ranging from finance to healthcare. By harnessing the power of Spark, organizations can gain valuable insights from their data, make informed decisions, and drive innovation.
Overall, "藏经阁-SCALABLE DATA SCIENCE.pdf" serves as a comprehensive guide to leveraging Spark for scalable data science. Through insightful analysis, practical examples, and expert guidance from Felix Cheung, readers are equipped with the knowledge and tools needed to harness the full potential of Spark for data-driven decision-making.
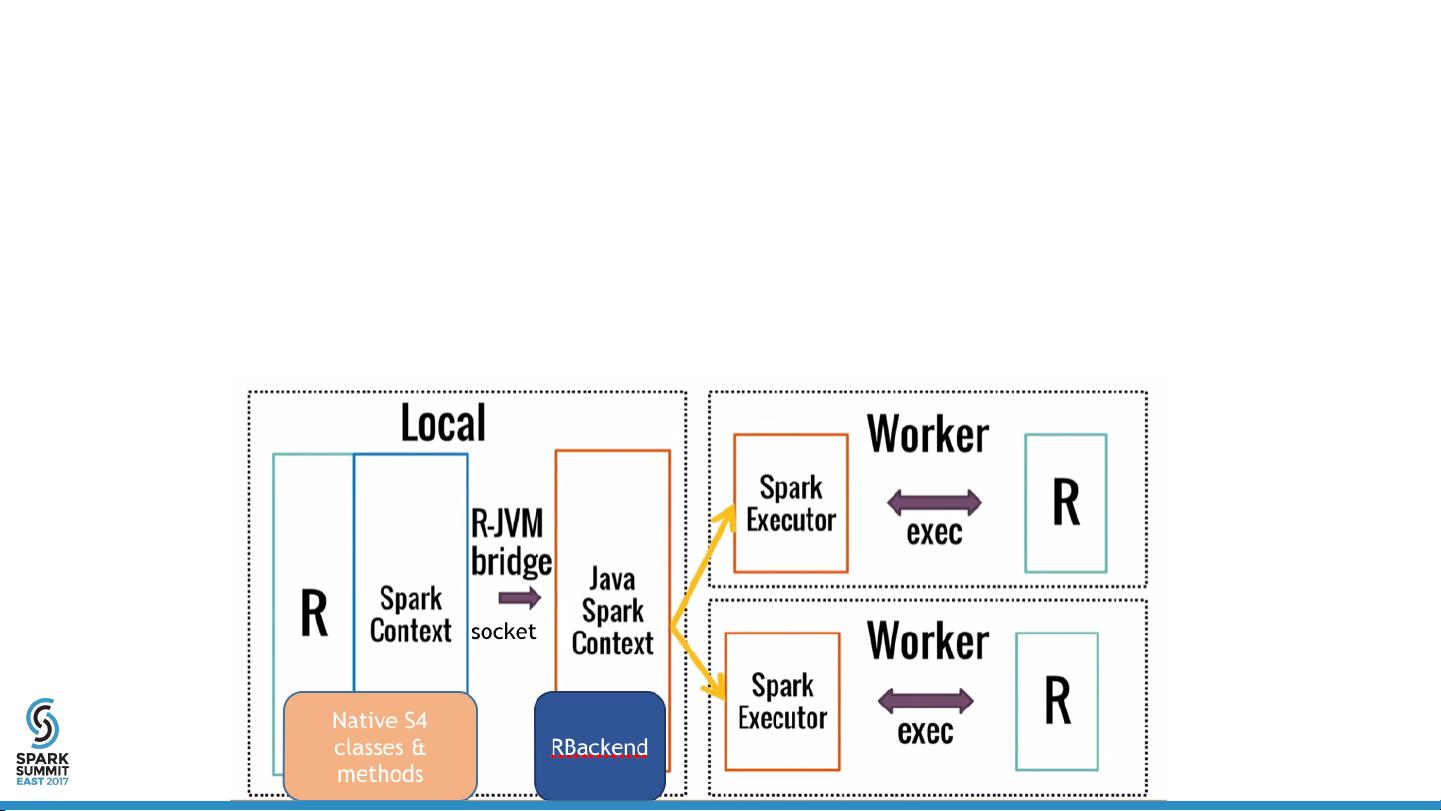
Architecture
•
Native R classes and methods
•
RBackend
•
Scala “helper” methods (ML pipeline etc.)
www.slideshare.net/SparkSummit/07-venkataraman-sun

剩余45页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2023-08-30 上传
2023-08-26 上传
2023-08-26 上传

weixin_40191861_zj
- 粉丝: 86
- 资源: 1万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- cljs-node:cljs 的节点编译器
- 中国一汽大采购体系降本工作计划汇报v7.rar
- lettergenerator:用StackBlitz创建:high_voltage:
- 毕业设计&课设--该版本微信小程序可以为学员提供学车报名、线上模拟考试、预约练车服务及驾校管理及教练管理。该小程序仅.zip
- rival:RiVal推荐系统评估工具包
- node-patch-manager:序列化 MIDI 配置的合成器音色并响应 MIDI 程序更改
- suhrmann.github.io
- Excel模板00多栏式明细账.zip
- EnergyForGood
- pytorch-CycleGAN-and-pix2pix-master
- KDM_ICP4
- 毕业设计&课设--大二J2EE课程设计 毕业设计选题系统(架构:spring+struts+hibernate) .zip
- Excel模板软件测试用例.zip
- google-map-react:uk
- Flight-Booking-System-JavaServlets_App::airplane:基于使用Java Servlet,Java服务器页面(JSP)制成的Model View Controller(MVC)架构的土耳其航空公司的企业级航班预订系统(Web应用程序)。 此外,还实现了对用户的身份验证和授权。 该Web应用程序还可以防止SQL注入和跨站点脚本攻击
- Algorithm:算法分析与设计作业
