HDFS HA高可用配置:解决NameNode单点故障
版权申诉
127 浏览量
更新于2024-08-07
收藏 6.12MB DOC 举报
"HDFS高可用配置文档主要介绍了如何解决Hadoop分布式文件系统(HDFS)中的NameNode单点故障问题,以及采用High Availability (HA)策略提升系统服务的可用性。文档详细阐述了HA的概念,强调了避免单点故障对业务连续性的重要性,并探讨了一主一备或多备架构的优缺点。"
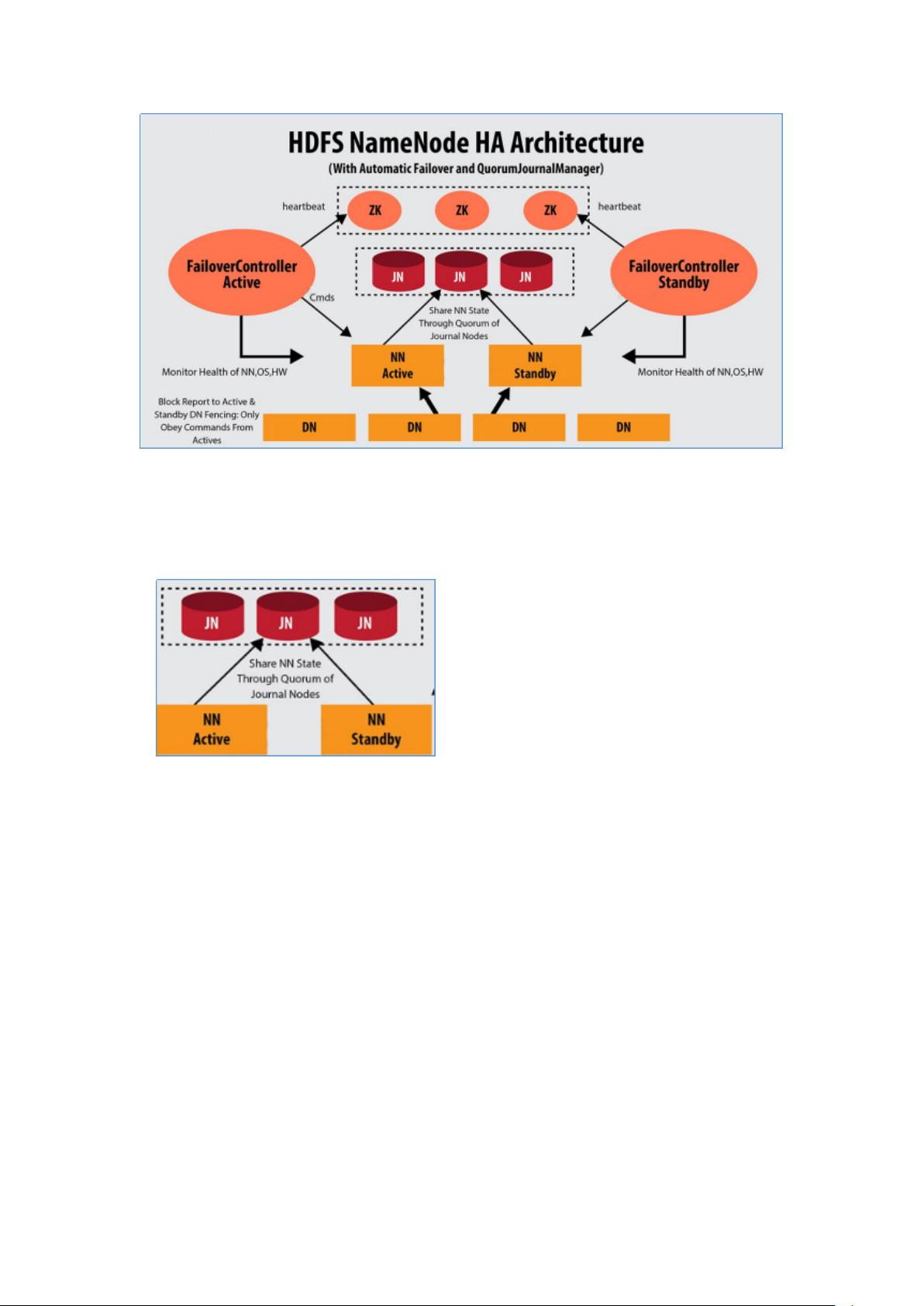
在Hadoop生态系统中,HDFS High Availability (HA) 是为了确保即使NameNode这样的关键组件出现故障,整个集群也能继续提供服务。在Hadoop 2.0.0之前,NameNode是HDFS的单点故障,它的宕机会导致整个集群不可用。为了解决这个问题,HDFS HA引入了双NameNode的机制,即Active和Standby两种状态。Active NameNode负责处理所有的客户端请求,而Standby NameNode则时刻保持与Active的同步,准备在需要时接管服务。
QJM(Quorum Journal Manager)是HDFS HA的一种实现方式,它依赖于Zookeeper的ZKFC(Zookeeper-based Failover Controller)来监控和协调NameNode的主备切换。QJM使用Journal Node (JN) 集群来存储和同步编辑日志(edits log),确保数据的一致性。当Active NameNode故障时,ZKFC会触发故障转移,Standby NameNode会接替Active的角色,继续处理客户端请求。
QJM的工作原理如下:
- **Journal Node集群**:JNs是共享日志的存储节点,它们接收并持久化来自NameNode的编辑日志。Active NameNode将更改写入多数(大多数)JNs,以保证数据的持久性和一致性。
- **Zookeeper中的ZKFC**:每个NameNode都运行一个ZKFC进程,它在Zookeeper中注册并监控NameNode的状态。在检测到Active NameNode故障后,ZKFC会协调选举新的Active NameNode。
- **主备切换**:当Standby NameNode发现它可以从多数JNs中读取最新的编辑日志时,它会成为新的Active,而旧的Active在修复后变为Standby。
通过这种方式,HDFS HA能够提供几乎无中断的服务,减少了因NameNode故障导致的集群不可用时间。然而,这种解决方案也需要更多的硬件资源,如额外的NameNode实例和Journal Node集群,以及Zookeeper集群来支持高可用性。
HDFS HA配置旨在提高Hadoop集群的稳定性和可靠性,通过冗余和智能故障转移机制,确保在硬件或软件故障时,数据服务能够迅速恢复,从而满足企业对持续服务的需求。
2.1-QJM—主备数据同步问题解决
Journal Node(JN)集群是轻量级分布式系统,主要用于高速读写数据、存储数据。通常
使用 2N+1 台 JournalNode 存储共享 Edits Log(编辑日志)。
任何修改操作在 Active NN 上执行时,JournalNode 进程同时也会记录 editslog 到至少半数
以上的 JN 中,这时 Standby NN 监测到 JN 里面的同步 log 发生变化了会读取 JN 里面的
edits log,然后重演操作记录同步到自己的目录镜像树里面,
当发生故障 ActiveNN 挂掉后,Standby NN 会在它成为 Active NN 前,读取所有的 JN 里
面的修改日志,这样就能高可靠的保证与挂掉的 NN 的目录镜像树一致,然后无缝的接替它
的职责,维护来自客户端请求,从而达到一个高可用的目的。
3-集群基础环境准备
配置三台主机
剩余11页未读,继续阅读
2019-06-17 上传
2009-03-24 上传
2015-02-05 上传
2024-07-24 上传
2022-08-04 上传
2022-07-11 上传
2022-03-05 上传
2022-11-21 上传

书博教育
- 粉丝: 1
- 资源: 2837
 我的内容管理
展开
我的内容管理
展开







最新资源
- C语言数组操作:高度检查器编程实践
- 基于Swift开发的嘉定单车LBS iOS应用项目解析
- 钗头凤声乐表演的二度创作分析报告
- 分布式数据库特训营全套教程资料
- JavaScript开发者Robert Bindar的博客平台
- MATLAB投影寻踪代码教程及文件解压缩指南
- HTML5拖放实现的RPSLS游戏教程
- HT://Dig引擎接口,Ampoliros开源模块应用
- 全面探测服务器性能与PHP环境的iprober PHP探针v0.024
- 新版提醒应用v2:基于MongoDB的数据存储
- 《我的世界》东方大陆1.12.2材质包深度体验
- Hypercore Promisifier: JavaScript中的回调转换为Promise包装器
- 探索开源项目Artifice:Slyme脚本与技巧游戏
- Matlab机器人学习代码解析与笔记分享
- 查尔默斯大学计算物理作业HP2解析
- GitHub问题管理新工具:GIRA-crx插件介绍
