深入理解Hive:高级编程与MapReduce解析
"Hive高级编程指南"
在大数据处理领域,Hive是一个基于Hadoop的数据仓库工具,它允许用户使用类SQL的查询语言(HiveQL)来查询、管理和存储大量结构化数据。本资源深入探讨了Hive的高级编程概念,涵盖了Hive组件、MapReduce工作原理以及Hive的SQL优化等多个方面。
首先,Hive的核心组件包括以下几个部分:
1. **HDFS**:Hive依赖于Hadoop的分布式文件系统HDFS来存储数据,确保数据的高可用性和可扩展性。
2. **Hive CLI**:Hive命令行接口,用户通过它与Hive交互,执行查询和管理任务。
3. **DDL**:定义了创建、修改和删除表等数据操作的语言。
4. **HiveQL**:类似于SQL的查询语言,用于查询和分析存储在Hive中的数据。
5. **MetaStore**:存储元数据,如表结构、分区信息等,通常通过Thrift API访问。
6. **SerDe**:序列化和反序列化库,用于将复杂的数据格式转换为Hive能理解的格式。
7. **Parser, Planner, Optimizer**:解析查询语句,规划执行计划,并进行优化,以提高查询效率。
8. **Execution Engine**:执行查询计划,利用MapReduce或Tez等计算框架处理数据。
接着,**MapReduce**是Hadoop处理大规模数据的基本计算模型,由Map和Reduce两个阶段组成:
- **Map阶段**:将输入数据分割,由多个Mapper任务并行处理,生成键值对。
- **Shuffle阶段**:Mapper的输出数据经过全局排序和分区,为Reduce阶段做准备。
- **Reduce阶段**:Reducer任务聚合键值对,生成最终结果。
在Hive中,**JOIN操作**是数据处理中的常见操作。例如,当执行如下HiveQL语句:
```sql
INSERT INTO TABLE pv_users
SELECT pv.pageid, u.age
FROM page_view pv JOIN user u ON (pv.userid = u.userid);
```
这会在MapReduce中实现,Map阶段会生成键值对,其中键是共同的`userid`,值是来自`page_view`和`user`表的相关记录。Shuffle阶段按键排序,确保相同`userid`的记录被发送到同一个Reducer。Reduce阶段则将匹配的记录组合起来,生成最终结果。
Hive的**优化**主要关注SQL查询的性能提升,这可能包括:
- **Partitioning**:将大表划分为小块,根据特定列的值进行存储,可以显著减少查询时间。
- **Bucketing**:在分区内部进一步切分数据,通过哈希函数确定数据的存储位置,有助于提高JOIN操作的效率。
- **索引**:虽然Hive原生不支持传统数据库的索引,但可以通过创建统计信息(如直方图、位图索引)来帮助优化器选择更好的执行计划。
- **列式存储**:相比于行式存储,列式存储在分析查询时更高效,因为可以只读取需要的列。
- **倾斜Join处理**:处理数据分布不均的JOIN操作,避免个别Reducer处理过多数据。
Hive高级编程涉及到对Hive组件的理解、MapReduce的工作流程,以及如何利用HiveQL和优化策略提高大数据查询的效率。通过深入学习这些内容,开发者可以更好地利用Hive进行大数据分析和处理。
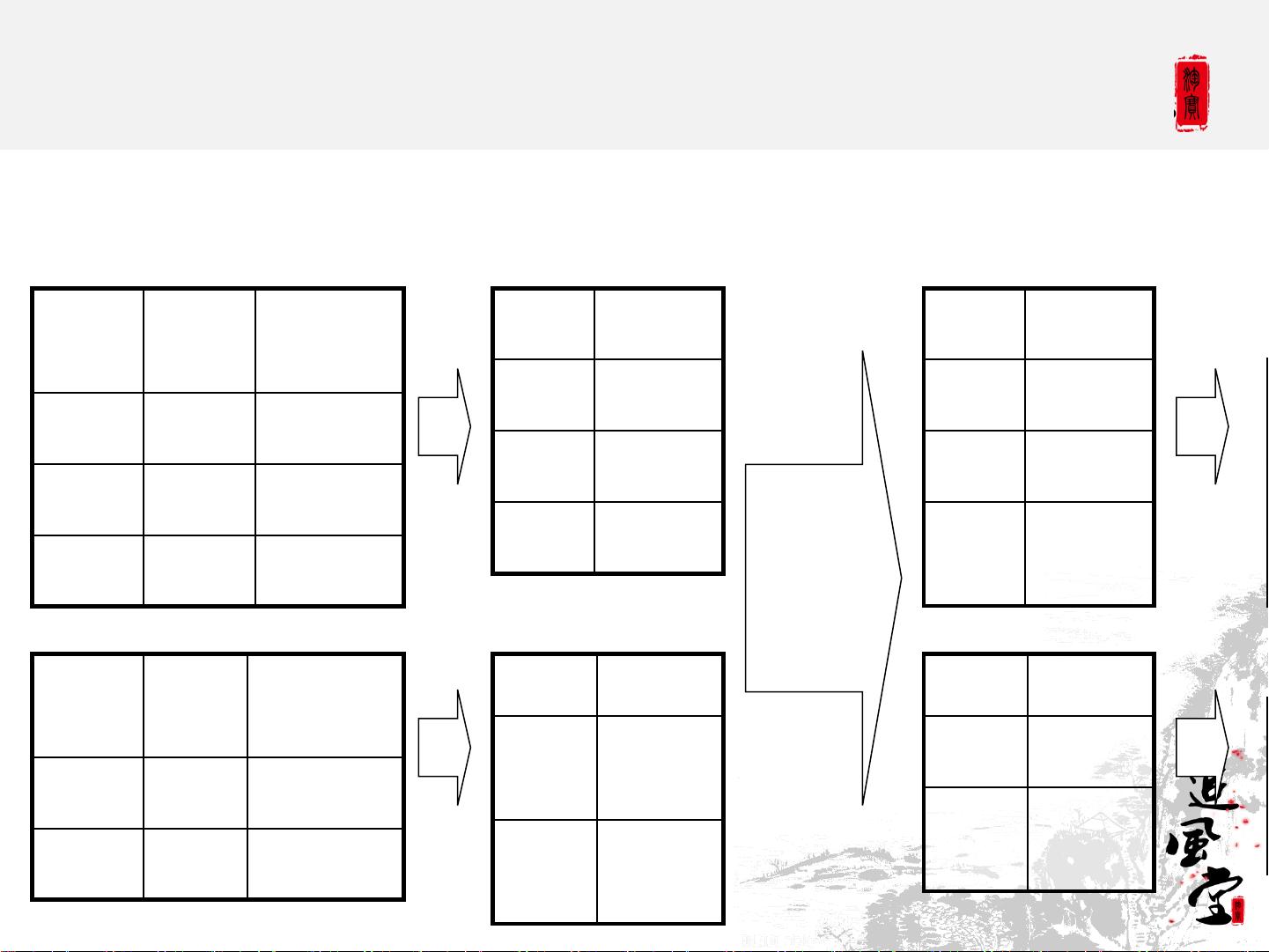
Hive QL – Join in Map Reduce
key value
111 <1,1>
111 <1,2>
222 <1,1>
pagei
d
useri
d
time
1 111 9:08:01
2 111 9:08:13
1 222 9:08:14
useri
d
age gender
111 25 female
222 32 male
page_view
user
key value
111 <2,25
>
222 <2,32
>
Map
key value
111 <1,1>
111 <1,2>
111 <2,25
>
key value
222 <1,1>
222 <2,32
>
Shuffle
Sort
pagei
pagei
Reduce
剩余26页未读,继续阅读
404 浏览量
2021-12-25 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

KDDOR
- 粉丝: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- 支付宝订单监控免签工具:实时监控与信息通知
- 一键永久删除QQ空间说说的绿色软件
- Appleseeds训练营第4周JavaScript练习
- 免费HTML转CHM工具:将网页文档化简成章
- 奇热剧集站SEO优化模板下载
- Python xlrd库:实用指南与Excel文件读取
- Genegraph:通过GraphQL API使用Apache Jena展示RDF基因数据
- CRRedist2008与CRRedist2005压缩包文件对比分析
- SDB交流伺服驱动系统选型指南与性能解析
- Android平台简易PDF阅读器的实现与应用
- Mybatis实现数据库物理分页的插件源码解析
- Docker Swarm实例解析与操作指南
- iOS平台GTMBase64文件的使用及解密
- 实现jQuery自定义右键菜单的代码示例
- PDF处理必备:掌握pdfbox与fontbox jar包
- Java推箱子游戏完整源代码分享
