Hive高级编程与MapReduce解析
“Hive高级编程,包括Hive组件、MapReduce、HiveQL、Hive优化和SQL优化,深入解析Hive在大数据处理中的应用。”
Hive是一个基于Hadoop的数据仓库工具,它允许通过类SQL语言(HiveQL)对存储在HDFS上的大规模数据进行查询和分析。Hive的主要组成部分包括:
1. **Hive Components**:Hive构建在HDFS之上,提供了一个交互式查询接口(Hive CLI)用于执行SQL样式的查询。DDL(Data Definition Language)用于定义表结构,而查询则由Hive解析器处理。元数据存储在MetaStore中,Thrift API允许远程访问元数据。SerDe(Serializer/Deserializer)处理数据的序列化和反序列化,支持多种数据格式如CSV、JSON等。执行引擎将HiveQL转换为MapReduce任务,进行分布式计算。
2. **MapReduce**:Hive的计算模型基于MapReduce,这是一种分布式计算框架,将大型任务分解为可并行处理的map任务和reduce任务。Map阶段将原始数据分割,键值对形式传递给reduce阶段,reduce阶段负责聚合结果。
- **Map阶段**:输入数据按键进行分区,每个分区由一个map任务处理。map任务接收键值对,进行本地处理,生成新的键值对。
- **Shuffle阶段**:全局排序和分区,将map阶段产生的中间键值对按照键排序,并分发到对应的reduce任务。
- **Reduce阶段**:根据排序后的键,将相同键的所有值传递给同一个reduce任务,进行聚合操作。
3. **HiveQL (Hive Query Language)**:类似于SQL,但针对大数据处理进行了优化。例如,HiveQL支持JOIN操作,如下所示的示例展示了如何通过JOIN连接`page_view`和`user`表,生成新的`pv_users`表,根据`userid`字段进行匹配。
```sql
INSERT INTO TABLE pv_users
SELECT pv.pageid, u.age
FROM page_view pv JOIN user u ON (pv.userid = u.userid);
```
4. **Hive优化**:为了提升性能,Hive提供了多种优化策略,包括:
- **Bucketing & Sampling**:通过哈希函数将数据分桶,使得JOIN操作更高效。
- **Partitioning**:将大表划分为多个小部分,按特定列值进行分割,减少查询时的数据扫描量。
- **Materialized Views**:预先计算并存储常用查询结果,提高查询速度。
- **Query Optimization**:如CBO(Cost-Based Optimization)根据数据统计信息选择最佳执行计划。
5. **SQL优化**:SQL查询优化主要关注查询效率,包括:
- **避免全表扫描**:使用WHERE子句过滤不必要的行。
- **有效使用JOIN**:避免笛卡尔积和大表JOIN,利用索引或分区缩小JOIN范围。
- **减少数据移动**:尽可能在map阶段完成计算,减少shuffle阶段的数据传输。
- **合理使用GROUP BY和ORDER BY**:避免无必要的全局排序,使用DISTRIBUTE BY和SORT BY进行局部排序。
Hive通过这些机制和优化,使得非专业程序员也能处理大规模的批处理查询,简化了大数据处理的复杂性,提高了效率。然而,由于其基于MapReduce,对于实时和低延迟查询,Hive可能不是最佳选择,更适合离线分析场景。
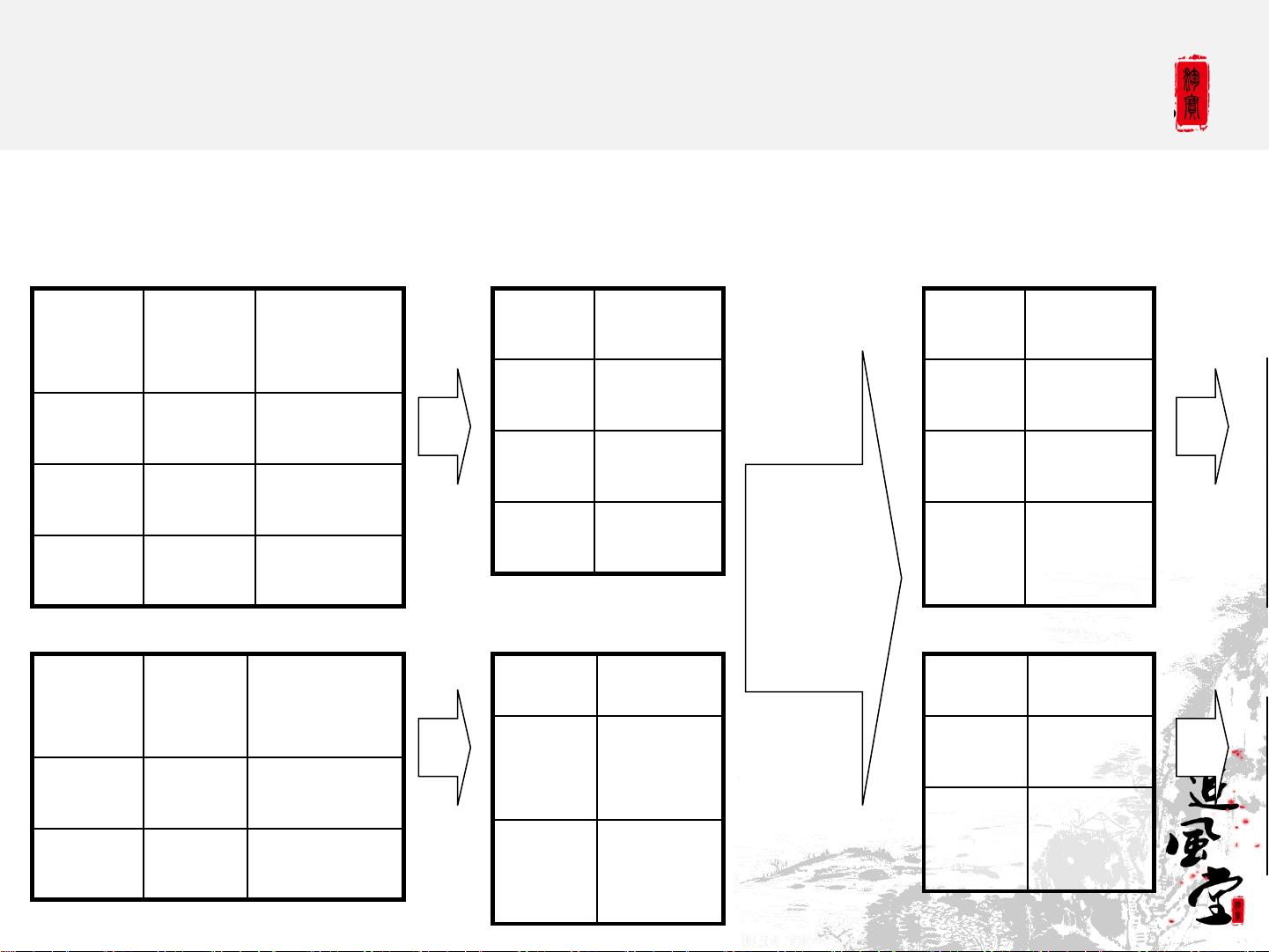
Hive QL – Join in Map Reduce
key value
111 <1,1>
111 <1,2>
222 <1,1>
pagei
d
useri
d
time
1 111 9:08:01
2 111 9:08:13
1 222 9:08:14
useri
d
age gender
111 25 female
222 32 male
page_view
user
key value
111 <2,25
>
222 <2,32
>
Map
key value
111 <1,1>
111 <1,2>
111 <2,25
>
key value
222 <1,1>
222 <2,32
>
Shuffle
Sort
pagei
pagei
Reduce
剩余26页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
167 浏览量
2021-12-25 上传
点击了解资源详情
2021-02-23 上传









