深入解析Hadoop HDFS源代码
"本文将对Hadoop中的HDFS进行源代码层面的分析,从Hadoop的基础概念、HDFS的主要组成部分到各个关键模块的实现方法,深入解析HDFS的工作原理。"
一、Hadoop系统基础
Hadoop是一个开源的分布式计算框架,由Apache Software Foundation在2005年创建,最初源于Nutch项目。它借鉴了Google的MapReduce编程模型和Google File System(GFS),并逐步发展成为处理和存储大量数据的强大工具。Hadoop的核心包括两个主要部分:HDFS(Hadoop Distributed File System)和MapReduce。HDFS是分布式的文件系统,负责数据的存储;MapReduce则是一个用于大规模数据集并行处理的计算框架。
1.4、Hadoop集群
Hadoop集群由多个节点组成,包括一个主节点(NameNode)和多个从节点(DataNode)。NameNode负责元数据管理,DataNode则存储实际的数据块。集群中的节点可以动态扩展,以适应数据量的增长。
二、Hadoop文件系统(HDFS)
HDFS设计的主要目标是提供高度容错性和高吞吐量的数据访问。它通过数据复制来保证数据的可靠性,通常每个数据块都有3个副本。
2.2、HDFS体系结构
HDFS由NameNode和DataNode构成。NameNode是元数据管理器,维护文件系统的命名空间和文件的块映射信息。DataNode则存储数据块,并根据NameNode的指令执行数据块的读写操作。
2.3、NameNode
NameNode是HDFS的关键组件,它管理文件系统的命名空间和文件的块信息。FSImage存储了文件系统的元数据,而FSEditLog记录了所有对元数据的修改操作。
2.4、DataNode
DataNode是HDFS的存储节点,它们负责存储数据块,并向NameNode和客户端报告其状态。当客户端请求读写操作时,DataNode会直接与客户端交互。
三、HDFS的实现代码分析
3.1、org.apache.hadoop.io
Hadoop的io包包含了各种基本的输入/输出类型,如Writable接口,它是所有可序列化数据类型的基类,使得数据能在网络间传输和持久化。
3.2、RPC的实现方法
Hadoop使用远程过程调用(RPC)进行节点间的通信。Client类负责发起RPC请求,Server类处理这些请求,而RPC类则是实现RPC协议的关键。
3.2.4、HDFS通信协议组
HDFS通信协议定义了NameNode、DataNode和客户端之间的交互方式,包括数据块的定位、心跳检测和错误报告等。
3.3、名称节点的实现方法
NameNode的实现涉及FSImage和FSEditLog类,它们分别负责持久化元数据和日志记录。FSNamesystem类是整个命名空间的逻辑视图,负责所有的文件操作。
3.4、数据节点的实现方法
DataNode的设计包括数据存储和处理两部分。它会定期向NameNode发送心跳信息,报告其状态,并响应NameNode的数据块复制命令。
3.5、客户端实现方法
客户端实现包括数据读取和写入的设计。在读取数据时,客户端首先从NameNode获取数据块位置,然后直接从相关的DataNode读取数据。写入数据时,数据会被分割成块,分别写入多个DataNode。
四、总结
通过对HDFS源代码的分析,我们可以更深入地理解Hadoop如何高效地处理大数据。无论是NameNode的元数据管理,DataNode的数据存储,还是客户端与节点间的通信机制,都展示了HDFS在设计上的精巧和实用性。这对于开发者来说,不仅有助于优化Hadoop应用,也能为构建自己的分布式系统提供参考。
Hadoop 中 HDFS 源代码分析
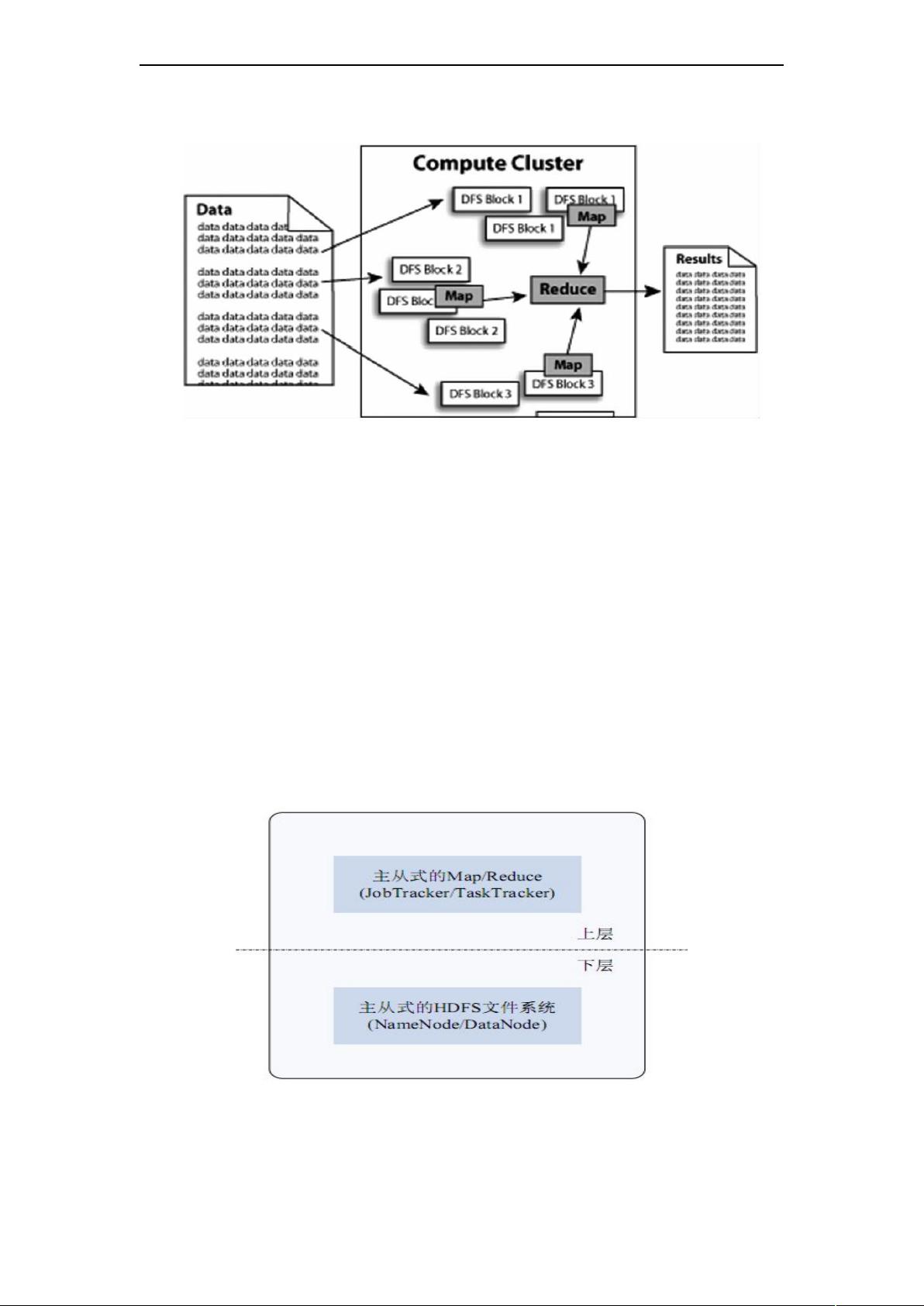
Hadoop 内 部 结 构 图
MapReduce 是依赖于 HDFS 实现的。通常MapReduce 会将被计算的数据
分为很多小块, HDFS 会将每个块复制若干份以确保系统的可靠性,同时它按
照一定的规则将数据块放置在集群中的不同机器上,以便MapReduce 在数据宿
主机器上进行最便捷的计算。
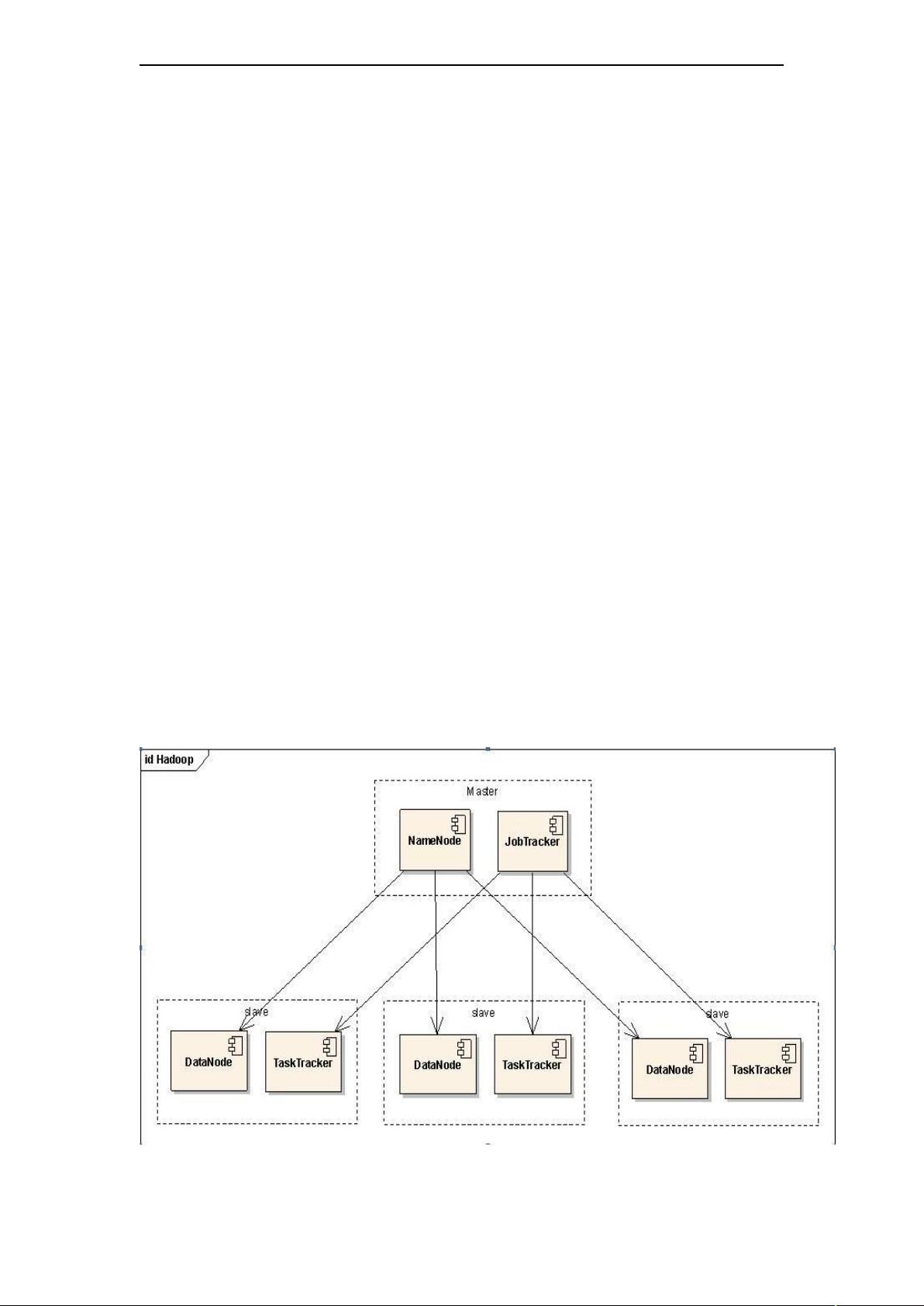
主从式是云计算系统的一种典型架构的方法,系统通过主节点屏蔽底层
的复杂结构,并向用户提供方便的文件目录映射。 Hadoop 中也采用了主从式
的架构技术,如图所示:
Hadoop 主 从 结 构
4
剩余38页未读,继续阅读
330 浏览量
2024-11-08 上传
2024-11-08 上传
206 浏览量
2024-11-08 上传
141 浏览量
156 浏览量

zx4866123
- 粉丝: 1
- 资源: 11
 我的内容管理
展开
我的内容管理
展开







