GraphX源码解析:Spark分布式图计算框架发展史与性能优化
需积分: 9 11 浏览量
更新于2024-07-17
收藏 4.8MB DOC 举报
本章节深入剖析了Apache Spark的GraphX库,它是在Spark 1.6版本中集成的分布式图计算引擎。GraphX的主要目标是提供一个简单易用的接口,封装复杂的分布式存储和并行计算,以便于专注于图模型的设计和使用,而不必过多关注底层的分布式实现细节。它的起源可以追溯到Spark早期的Bagel模块,经过0.8版本的独立分支开发,到0.9和1.0版本的稳定集成,GraphX经历了显著的成长。
GraphX的发展历程始于Spark 0.5版本的实验性Bagel模块,随着需求的增长,特别是在0.8版本后,Spark团队成立了专门的GraphX分支,受到GraphLab的影响。0.9版本的Alpha版虽然功能尚不完善,但已初具规模,而到了1.0版本,GraphX正式成为生产环境中的工具。GraphX在发展过程中不断优化,尤其是在代码结构和性能方面,每次版本升级都能带来10%至20%的性能提升。
在设计上,GraphX充分利用了当时的点分割(vertex-centric)和全局属性散列(GAS)技术,通过优化实现了一种在功能和性能之间取得平衡的方法。它与其他图计算框架如GraphLab相比,虽然可能在性能上有差距,但Spark的整体架构、社区的活跃以及快速迭代使其具有很高的竞争力。
学习GraphX时,推荐的参考资料包括《Apache Spark Graph Processing》这本书,适合入门者阅读,而《Advanced Analytics with Spark》的第七章则深入介绍了其应用,尽管阅读难度较高。同时,需要注意的是,市面上的一些教程可能存在质量参差不齐的问题,比如《Spark+GraphX大规模图计算和图挖掘》虽包含源代码,但可能主要依赖复制粘贴,缺乏深度分析。
理解GraphX的关键在于掌握其设计理念、核心数据结构和API,以及如何在Spark的生态系统中有效地利用它进行图计算和分析。随着Spark的持续演进,GraphX的功能和技术将继续扩展,为大规模图处理提供强大支持。

!
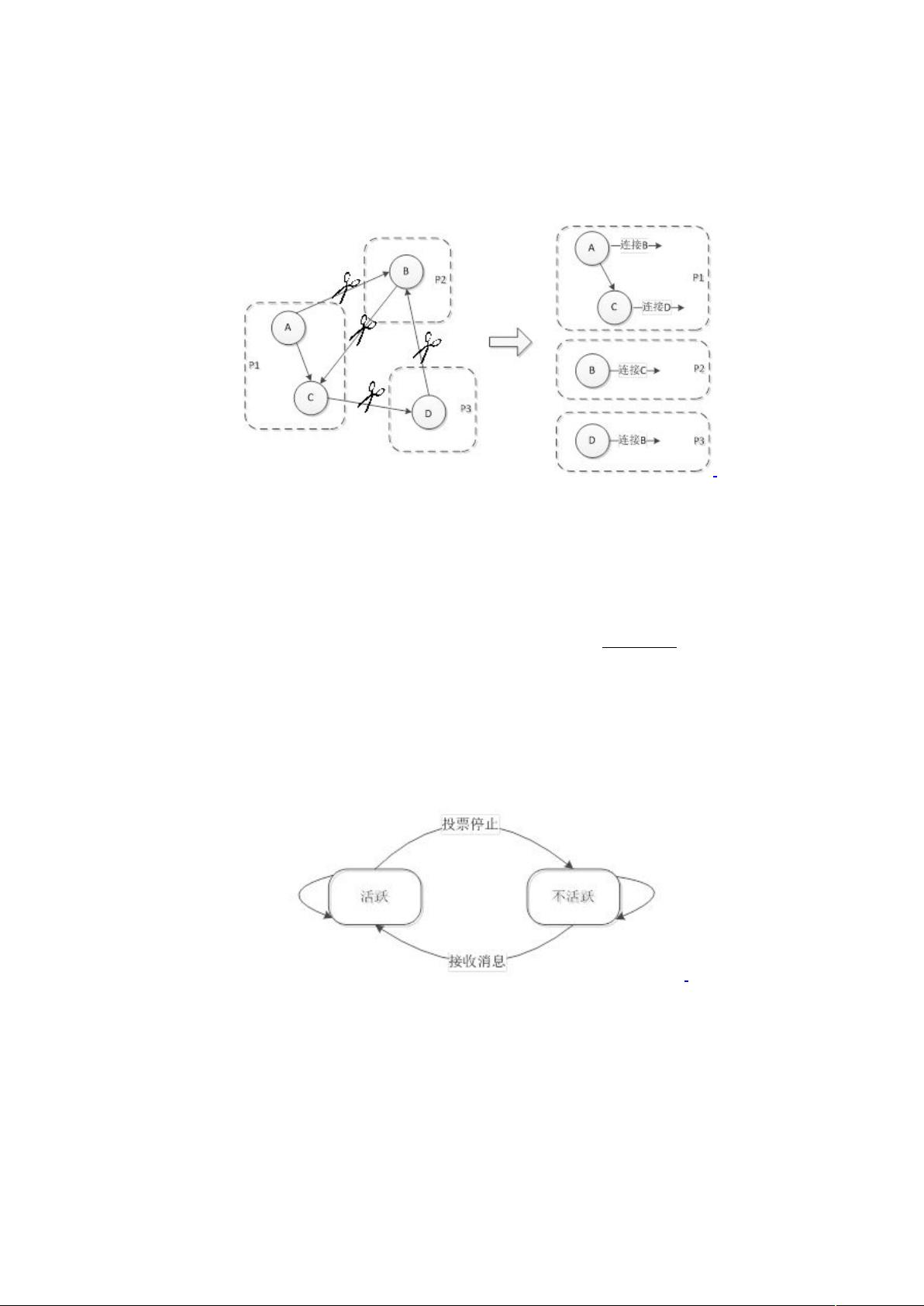
我的理解:按顶点切割以后,源顶点在哪个机器(分区),边就存在哪个机器(分
区)。
一.4.4.2 RandomVertexCut*
&,=+9,
2,2$&
根据源顶点和目标顶点的哈希值来把边分配到分区,最后所有相同方向的边被放在两
个顶点之间。
一.4.4.3 CanonicalRandomVertexCut*
&,=+
( 标 准 的 ) 9,2,&
9D
用规范的方法计算出源顶点和目标顶点的哈希值来把边分配到分区9最后所有边被放在
了两个顶点中,而不管方向是怎样。
一.4.4.4 EdgePartition2d
,+DP2 (稀
疏边邻接矩阵)9,QBO8,2:Q&,(点复制)
一.5 GraphX 使用 GAS 图计算模型
一.5.1 BSP 计算模式
目前的图计算框架基本上都遵循 #(#,,)计算模式。在 #
中,一次计算过程由一系列全局超步(超级计算步)组成,每一个超步由并发计算、通信
和栅栏同步三个步骤组成。同步完成,标志着这个超步的完成及下一个超步的开始。#
模式很简洁。基于 # 模式,目前有两种比较成熟的图计算模型。
一.5.1.1 Pregel 模型——像顶点一样思考
框 架 由 谷 歌 提 出 , 用 于 解 决 机 器 学 习 的 数 据 同 步 和 算 法 迭 代 , 是 基 于
#(#,,2)思想的图并行计算框架,它以顶点为中心,不断
在顶点上进行算法迭代和数据同步。
在 计算模型中,输入数据是一个有向图,该有向图的每一个顶点包含顶点 =+ 和
属性值,这些属性可以被修改,其初始值由用户定义。有向边记录了源顶点和目的顶点的
=+,并且也拥有用户定义的属性值。 以顶点为中心,对边进行切割,将图数据分成
剩余55页未读,继续阅读
2023-01-12 上传
696 浏览量
192 浏览量
2024-01-23 上传
2023-03-25 上传
2023-06-08 上传
2023-09-14 上传
2023-06-09 上传
2023-05-21 上传

BrotherDongDong
- 粉丝: 63
- 资源: 25
 我的内容管理
展开
我的内容管理
展开







最新资源
- SSM Java项目:StudentInfo 数据管理与可视化分析
- pyedgar:Python库简化EDGAR数据交互与文档下载
- Node.js环境下wfdb文件解码与实时数据处理
- phpcms v2.2企业级网站管理系统发布
- 美团饿了么优惠券推广工具-uniapp源码
- 基于红外传感器的会议室实时占用率测量系统
- DenseNet-201预训练模型:图像分类的深度学习工具箱
- Java实现和弦移调工具:Transposer-java
- phpMyFAQ 2.5.1 Beta多国语言版:技术项目源码共享平台
- Python自动化源码实现便捷自动下单功能
- Android天气预报应用:查看多城市详细天气信息
- PHPTML类:简化HTML页面创建的PHP开源工具
- Biovec在蛋白质分析中的应用:预测、结构和可视化
- EfficientNet-b0深度学习工具箱模型在MATLAB中的应用
- 2024年河北省技能大赛数字化设计开发样题解析
- 笔记本USB加湿器:便携式设计解决方案
