TensorFlow驱动的NLP深度学习实践
78 浏览量
更新于2024-08-29
收藏 673KB PDF 举报
"深度学习在NLP中的应用,特别是TensorFlow框架下的模型,如词向量、RNN/LSTM和自动翻译模型"
深度学习是近年来在自然语言处理(NLP)领域取得突破的关键技术,它利用复杂的神经网络模型来理解和生成人类语言。TensorFlow作为一个强大的开源库,为开发和部署这些模型提供了便利。本篇文章将深入探讨TensorFlow在NLP中的应用,特别是词向量生成、语言建模以及自动翻译。
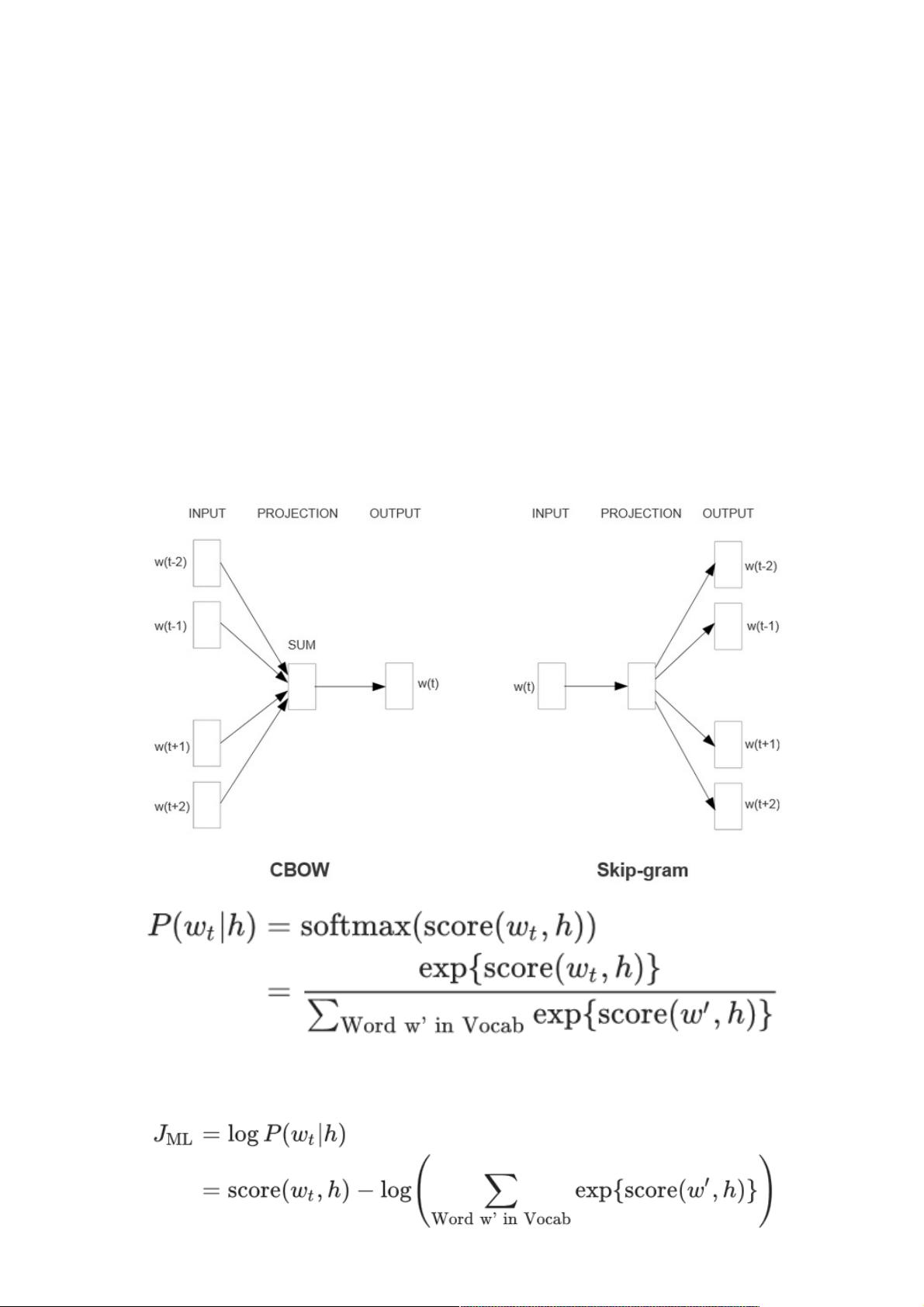
首先,词向量是深度学习NLP的基础,它将词汇转化为数值向量,使得机器能够理解和比较词汇间的语义关系。Word2Vec是实现这一转换的代表性算法,包含CBOW和Skip-gram两种模型。CBOW模型通过上下文词汇预测中心词,而Skip-gram则是预测上下文词给定中心词。这两个模型都通过最小化损失函数来优化词向量,以提高上下文词对中心词的预测能力。训练过程通常采用负采样或Hierarchical Softmax等策略降低计算成本。
其次,循环神经网络(RNN)和长短时记忆网络(LSTM)在语言建模中发挥着重要作用。RNN是一种能处理序列数据的网络,它保留了时间步骤的信息,但容易遇到梯度消失问题。LSTM通过引入门控机制解决了这个问题,使其在处理长序列时仍能保持有效学习。在TensorFlow中,可以构建并训练这些模型,用于生成连续的文本序列,例如预测下一个单词,或者进行文本生成任务。
最后,TensorFlow的tf-seq2seq框架支持自动翻译模型的构建,它基于编码器-解码器架构,其中编码器将源语言序列转化为固定长度的向量表示,解码器则从这个向量开始生成目标语言序列。这种模型在处理多语言翻译任务时表现出色,显著提高了翻译的准确性和流畅性。
TensorFlow提供的工具和库极大地简化了NLP模型的开发和实验,使得研究人员和开发者能够快速迭代和优化模型。通过词向量学习、RNN/LSTM的语言建模以及自动翻译模型,TensorFlow不仅推动了NLP技术的发展,也为实际应用带来了巨大的价值,比如智能助手、情感分析、文本摘要和信息检索等领域。随着深度学习和NLP的持续融合,未来将有更多的创新和突破出现。
深度学习利器:深度学习利器:TensorFlow与与NLP模型模型
前言
自然语言处理(简称NLP),是研究计算机处理人类语言的一门技术,NLP技术让计算机可以基于一组技术和理论,分析、理
解人类的沟通内容。传统的自然语言处理方法涉及到了很多语言学本身的知识,而深度学习,是表征学习(representation
learning)的一种方法,在机器翻译、自动问答、文本分类、情感分析、信息抽取、序列标注、语法解析等领域都有广泛的应
用。
2013年末谷歌发布的word2vec工具,将一个词表示为词向量,将文字数字化,有效地应用于文本分析。2016年谷歌开源自动
生成文本摘要模型及相关TensorFlow代码。2016/2017年,谷歌发布/升级语言处理框架SyntaxNet,识别率提高25%,为40种
语言带来文本分割和词态分析功能。2017年谷歌官方开源tf-seq2seq,一种通用编码器/解码器框架,实现自动翻译。本文主
要结合TensorFlow平台,讲解TensorFlow词向量生成模型(Vector Representations of Words);使用RNN、LSTM模型进
行语言预测;以及TensorFlow自动翻译模型。
Word2Vec数学原理简介
我们将自然语言交给机器学习来处理,但机器无法直接理解人类语言。那么首先要做的事情就是要将语言数学化,Hinton于
1986年提出Distributed Representation方法,通过训练将语言中的每一个词映射成一个固定长度的向量。所有这些向量构成词
向量空间,每个向量可视为空间中的一个点,这样就可以根据词之间的距离来判断它们之间的相似性,并且可以把其应用扩展
到句子、文档及中文分词。
Word2Vec中用到两个模型,CBOW模型(Continuous Bag-of-Words model)和Skip-gram模型(Continuous Skip-gram
Model)。模型示例如下,是三层结构的神经网络模型,包括输入层,投影层和输出层。
其中score(wt, h),表示在的上下文环境下,预测结果是的概率得分。上述目标函数,可以转换为极大化似然函数,如下所
示:
下载后可阅读完整内容,剩余5页未读,立即下载
2023-10-07 上传
2018-03-24 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_38638647
- 粉丝: 7
- 资源: 993
 我的内容管理
展开
我的内容管理
展开







最新资源
- Android圆角进度条控件的设计与应用
- mui框架实现带侧边栏的响应式布局
- Android仿知乎横线直线进度条实现教程
- SSM选课系统实现:Spring+SpringMVC+MyBatis源码剖析
- 使用JavaScript开发的流星待办事项应用
- Google Code Jam 2015竞赛回顾与Java编程实践
- Angular 2与NW.js集成:通过Webpack和Gulp构建环境详解
- OneDayTripPlanner:数字化城市旅游活动规划助手
- TinySTM 轻量级原子操作库的详细介绍与安装指南
- 模拟PHP序列化:JavaScript实现序列化与反序列化技术
- ***进销存系统全面功能介绍与开发指南
- 掌握Clojure命名空间的正确重新加载技巧
- 免费获取VMD模态分解Matlab源代码与案例数据
- BuglyEasyToUnity最新更新优化:简化Unity开发者接入流程
- Android学生俱乐部项目任务2解析与实践
- 掌握Elixir语言构建高效分布式网络爬虫
