网易云Kafka实战:部署、运维与一体化解决方案
需积分: 9 87 浏览量
更新于2024-07-16
收藏 1.18MB PDF 举报
《Kafka在网易云上的实践》是一份由网易的架构师分享的技术文档,主要探讨了Kafka在大型企业级环境中,如网易云的部署与实践。随着业务的快速发展,Kafka作为分布式流处理平台在网易云中的重要性日益凸显。以下是文档中涉及的关键知识点:
1. **Kafka上云的必要性**:
随着业务规模的扩大,网易内部不同部门维护各自的Kafka集群导致运维复杂度上升,包括部署、升级、问题定位和监控等方面都需要专业的团队支持。此外,高昂的运维成本和资源浪费也促使网易寻求更高效的一站式服务解决方案。
2. **一站式服务与统一运维**:
网易云提供了Kafka服务,旨在简化管理,如一键部署,快速交付,以及可视化管理(Kafka集群、Topic和Connect集群)。它还提供了OpenAPI,使得资源伸缩变得容易,用户可以根据需求自行调整。同时,云服务提供了在线升级功能和全面的性能监控,确保服务的稳定性和灵活性。
3. **产品架构挑战与解决方案**:
上云过程中,网易云Kafka面临网络、存储、运维和安全等方面的挑战。例如,通过独立部署Broker和Zookeeper,以及多租户管理来保障隔离性和安全性。云监控技术对操作系统、数据磁盘、Kafka进程和Topic性能进行深入监控,确保高效运行。
4. **技术架构与关键特性**:
网易云Kafka基于网易云基础设施,支持独立集群和多租户模式,通过流量控制和多IP策略提高可用性。其技术架构强调了资源的弹性,包括集群缩放(增加或减少虚拟机)、数据迁移以及在线升级功能。在安全方面,确保数据的安全性和隐私保护。
5. **运维优势**:
网易云Kafka的运维优势在于其多年积累的Kafka使用经验和对开源社区的兼容性,能够提供专业的运维支持,并已在游戏、电商、区块链等多个领域得到验证。
《Kafka在网易云上的实践》详细阐述了Kafka在网易云环境中的实施策略和核心优势,突显了云计算时代对企业IT架构的深远影响,以及如何通过标准化和专业化服务来优化Kafka的使用和管理。这对于企业考虑Kafka上云以及寻求高效运维解决方案具有重要的参考价值。
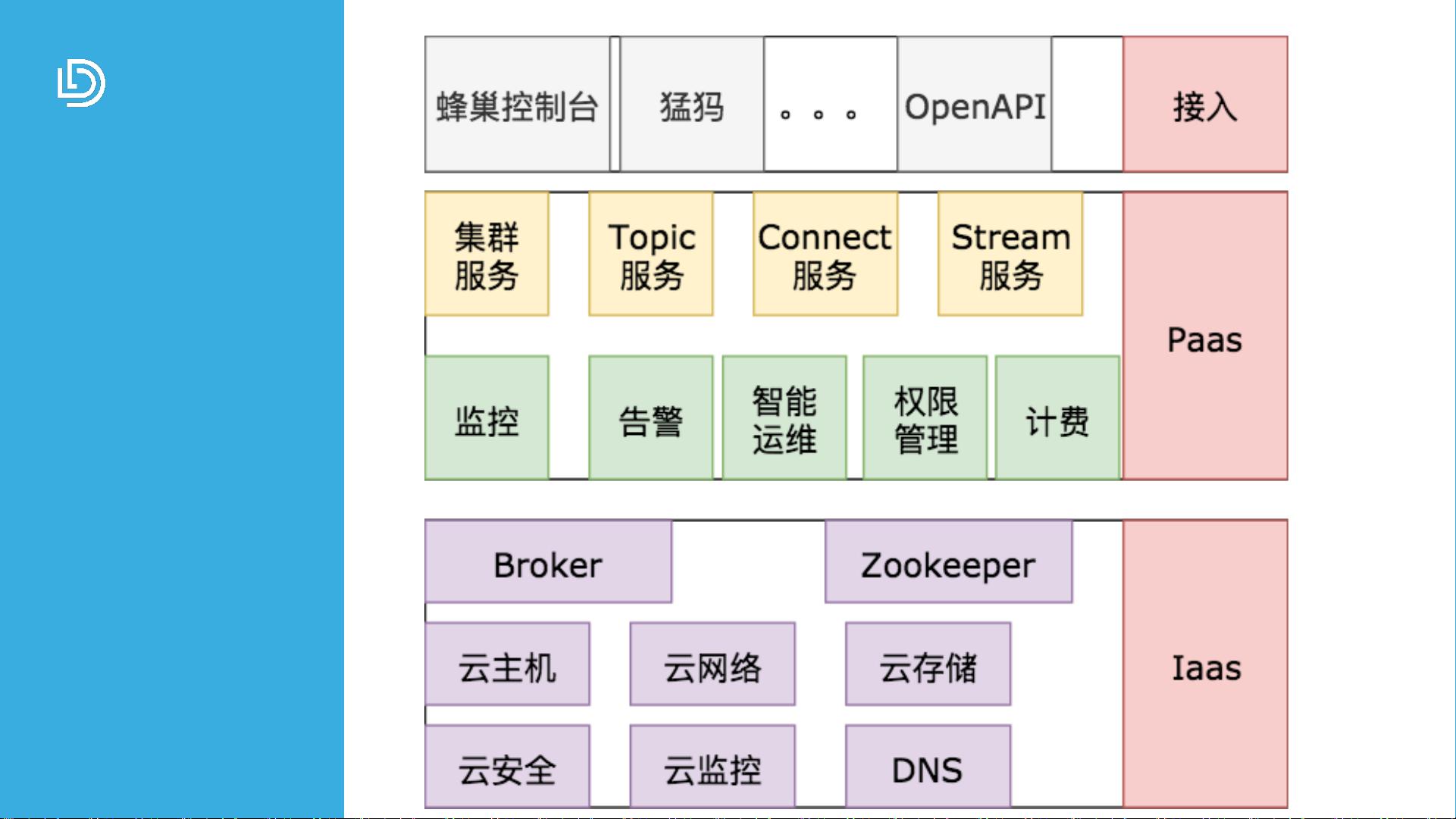
网易云Kafka
产品架构
剩余16页未读,继续阅读
2021-10-19 上传
2019-07-22 上传
2021-10-19 上传
2023-08-20 上传
2023-06-10 上传
2023-03-30 上传
2023-07-12 上传
2023-05-24 上传
2023-05-30 上传

朱晶
- 粉丝: 35
- 资源: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- 手把手教你用VMware在linux下安装oracle10g RAC
- asp.net常用代码
- EMI_EMC设计秘籍电子工程师必备
- CAN总线学习心得:zlg关于can帖子汇总(一.pdf
- JSP数据库编程指南.pdf
- TD移动通信系统--很经典的TD入门教程
- FusionChartsFree中文开发指南
- Thinking.In.Java.3rd.Edition.Chinese.eBook
- 数据库DB2快速入门
- 全差分运算放大器设计
- C语言 学习资料 入门级别
- JAVA 面试题(达内内部资源)
- hibernate 3.31参考文档 (pdf)
- Serv-U FTP的建立和维护手册(增补稿) BY Hermit.pdf
- CSSPCMS项目文档
- 经典的PCB设计经验
