掌握SparkStreaming:流式计算实战与DStream详解
需积分: 10 85 浏览量
更新于2024-09-10
收藏 634KB DOCX 举报
SparkStreaming是Apache Spark的一个扩展模块,专注于实时流式数据处理,其设计初衷是解决大规模数据流的高效计算问题。它在Spark生态系统中扮演着至关重要的角色,结合了Spark的内存计算模型和容错能力,使得实时数据处理变得既易用又强大。
课程目标主要聚焦于理解SparkStreaming的工作原理,掌握如何有效地利用其API来构建和执行流式计算任务。SparkStreaming的特点包括:
1. 高吞吐量:能够处理大量的实时数据流,适合处理实时或近实时的数据处理场景。
2. 容错性:SparkStreaming具有自动恢复机制,当出现故障时能从最近的已成功处理的数据点重新开始计算,确保数据处理的连续性和完整性。
SparkStreaming支持多种数据输入源,如Kafka、Flume、Twitter等,这极大地扩展了其应用范围。DStream是SparkStreaming的核心抽象,代表了时间分片的数据流,它是通过一系列连续的RDD(弹性分布式数据集)来表示的,每个RDD包含一定时间窗口内的数据。DStream操作大致可以分为两类:Transformations(转换),如map、reduce、join等,这些操作类似于RDD操作;和OutputOperations(输出)操作,如将处理结果持久化到HDFS或其他存储系统。
特别值得关注的是UpdateStateByKeyOperation,这是一种特殊类型的转换操作,用于维护状态信息,如在WordCount示例中跟踪单词出现的频率。如果没有使用UpdateStateByKey,每次数据处理完后,结果不会被持久化,这体现了SparkStreaming对状态管理的灵活性。
TransformOperation则允许在DStream上执行自定义的RDD-to-RDD函数,提供了强大的灵活性,开发者可以根据实际需求进行复杂的数据转换。
Spark与Storm相比,SparkStreaming更加易用,因为它构建在Spark基础之上,共享了Spark的许多优点,如内存计算、容错机制和分布式计算能力。然而,Storm更适合低延迟、毫秒级响应的实时流处理,而SparkStreaming更偏向于处理批量化的实时数据。
SparkStreaming是大数据工程师必备的技能之一,对于实时数据处理和监控,以及与机器学习(MLlib)和图形处理(Graphx)的集成有着不可忽视的价值。通过深入学习和实践,开发者可以更好地应对不断增长的实时数据挑战。
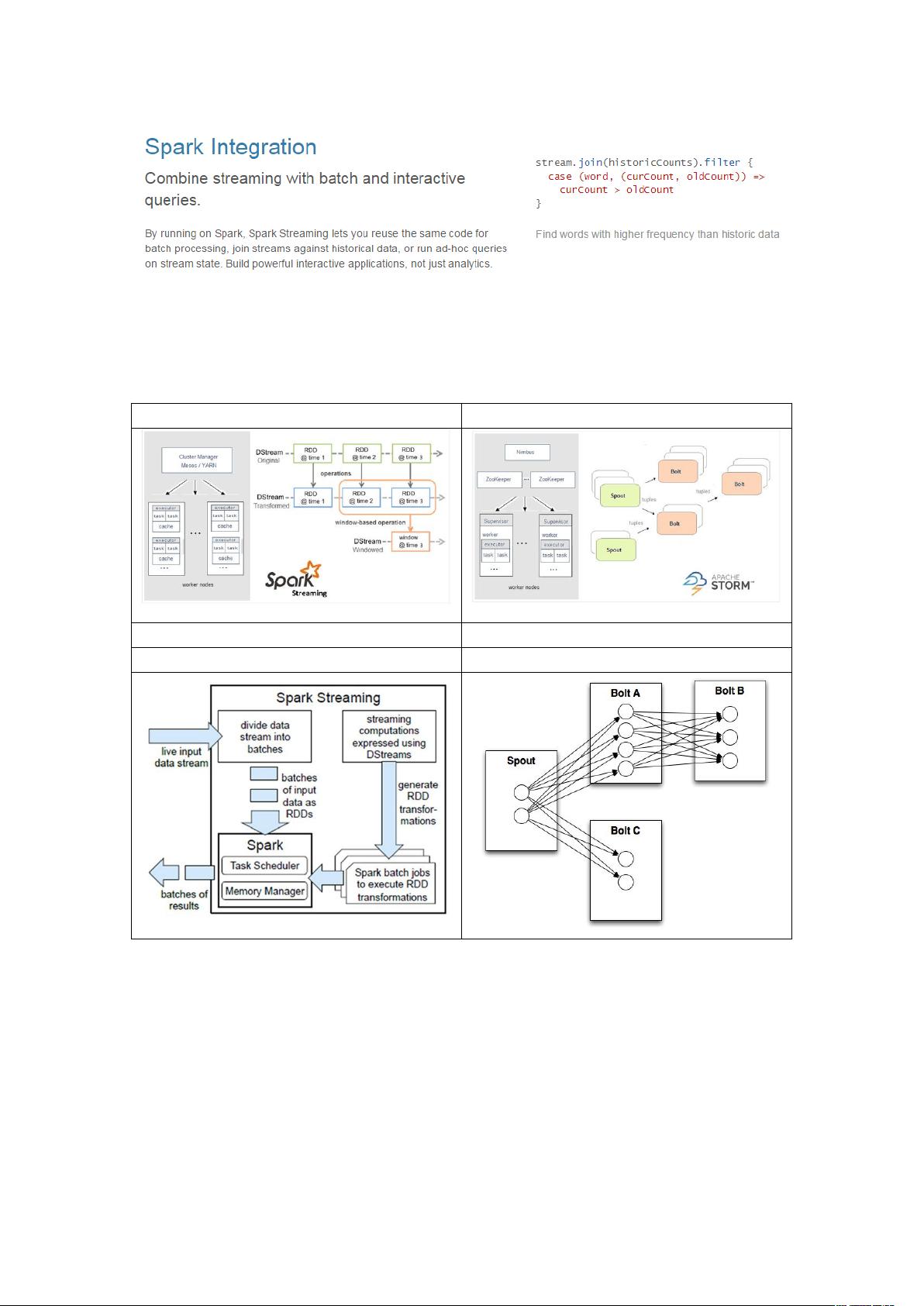
2.1.3. Spark 与 Storm 的对比
Spark Storm
开发语言:Scala 开发语言:Clojure
编程模型:DStream 编程模型:Spout/Bolt
剩余10页未读,继续阅读
367 浏览量
397 浏览量
170 浏览量
365 浏览量
160 浏览量
178 浏览量
2023-04-23 上传
216 浏览量
107 浏览量

dengddddw
- 粉丝: 1
- 资源: 52
 我的内容管理
展开
我的内容管理
展开







最新资源
- android_hybird:android_hibird 框架
- ABOV芯片 项目01 代码.zip
- 【深层神经网络实战代码】识别猫 吴恩达深度学习笔记
- teste-indt-master.zip
- 互联网大厂C++复习经验
- maolan:毛兰DAW的GUI
- CS-518:CS 518课程的作业
- 安全摄像头原理图及PCB
- ArduinoRequestResponse:Arduino固件与ORSSerialPort RequestResponseDemo示例应用程序一起使用
- VC操作MD5.rar
- buildz-api
- portal-web-ecoleta:下一级别的活动周日,Rocketseat实用工具TypeScript,NodeJS,ReactJS和React Native。 紧急情况下的集体诉讼,请在以下情况下填写您的姓名:(必要的)取消必要的附加条件
- wiki:一个简洁的个人 wiki,使用 vue.js 和 markdown-js
- aura:气候仪表板
- 最简单的SysTick延时程序
- 安全摄像头程序源码(好用)
