详述Hadoop2.6.0伪分布式安装步骤与常见问题
需积分: 8 55 浏览量
更新于2024-09-09
收藏 290KB DOCX 举报
"本文档详细介绍了在单台机器上进行Hadoop 2.6.0伪分布式安装的步骤,包括解决安装过程中遇到的问题,如JDK版本错误和下载了源码版Hadoop。"
在进行Hadoop 2.6.0伪分布式安装时,首先要确保你的系统已经正确安装了Java环境,因为Hadoop依赖于Java运行。在本例中,安装者遇到了JDK版本不兼容的问题,但通过某种方法解决了这个问题。在开始安装之前,请确保你的系统中安装的是与Hadoop兼容的JDK版本。
接下来,你需要下载Hadoop的二进制发行版,而不是源码版。这里选择了Hadoop 2.6.0的tar.gz文件。将Hadoop解压到指定目录,例如 `/opt/yarn`。为了管理Hadoop的不同组件,通常会创建多个用户和用户组,如`hadoop`用户组以及`yarn`, `hdfs`, `mapred`这三个用户。
安装过程中,还需要创建数据和日志目录,并设置适当的权限。这些目录通常包括NameNode、SecondaryNameNode和DataNode的数据存储路径,以及NodeManager的日志目录。确保这些目录的所有者和用户组设置为相应的Hadoop用户。
配置Hadoop的核心文件包括`core-site.xml`、`hdfs-site.xml`、`mapred-site.xml`和`yarn-site.xml`。在`core-site.xml`中,主要设置`fs.default.name`来指定NameNode的主机名和端口号,以及`hadoop.http.staticuser.user`来设定默认的HDFS用户名。`hdfs-site.xml`中,关键配置是`dfs.replication`,由于是伪分布式,将其设置为1即可。同时,需要指定NameNode、SecondaryNameNode和DataNode的数据目录。
`mapred-site.xml`中,主要配置`mapreduce.framework.name`为`yarn`,表明MapReduce将在YARN上运行。在`yarn-site.xml`中,需要设置`yarn.nodemanager.aux-services`以支持MapReduce Shuffle服务。
在环境变量配置中,需要修改`hadoop-env.sh`、`mapred-env.sh`和`yarn-env.sh`,特别是设置`JAVA_HOME`指向正确的JDK安装路径。
完成所有配置后,执行HDFS的格式化操作,这一步将初始化NameNode的状态。如果出现警告提示,可能是由于JDK位数与系统不匹配,但不影响基本功能。使用`jps`命令检查HDFS服务是否正常启动。
接着启动YARN服务,包括ResourceManager和NodeManager,再次使用`jps`确认它们都已经启动。最后,你可以通过Web界面来验证Hadoop服务是否正常运行,分别访问`http://IP:50070`来查看NameNode的状态,以及`http://IP:8088`来检查ResourceManager的Web界面。
通过以上步骤,你将在单台机器上成功部署Hadoop 2.6.0的伪分布式环境,可以进行本地的Hadoop测试和学习。在实际生产环境中,可能会涉及到多节点集群的配置,需要考虑更多的网络、安全性及资源调度策略。
先说遇到的几个问题:
开始是 jdk 装错版本了,后来找了个方法解决;
第二就是 hadoop 一开始下了 src 版本,东西都配了好多才发现。。真是蠢到极致。
以下是安装步骤:
1.首先确保机器上 java 安装成功。
2.下载 hadoop2.6.0.tar.gz
3.创建/opt/yarn,命令如下:
mkdir -p /opt/yarn
cd /opt/yarn
tar xvzf hadoop2.6.0.tar.gz 所在目录的绝对路径
4.创建用户和组,以下创建了 hadoop 用户组和三个账号(yarn、hdfs、mapred)
5.创建数据和日志目录,并设置其所有者和用户组
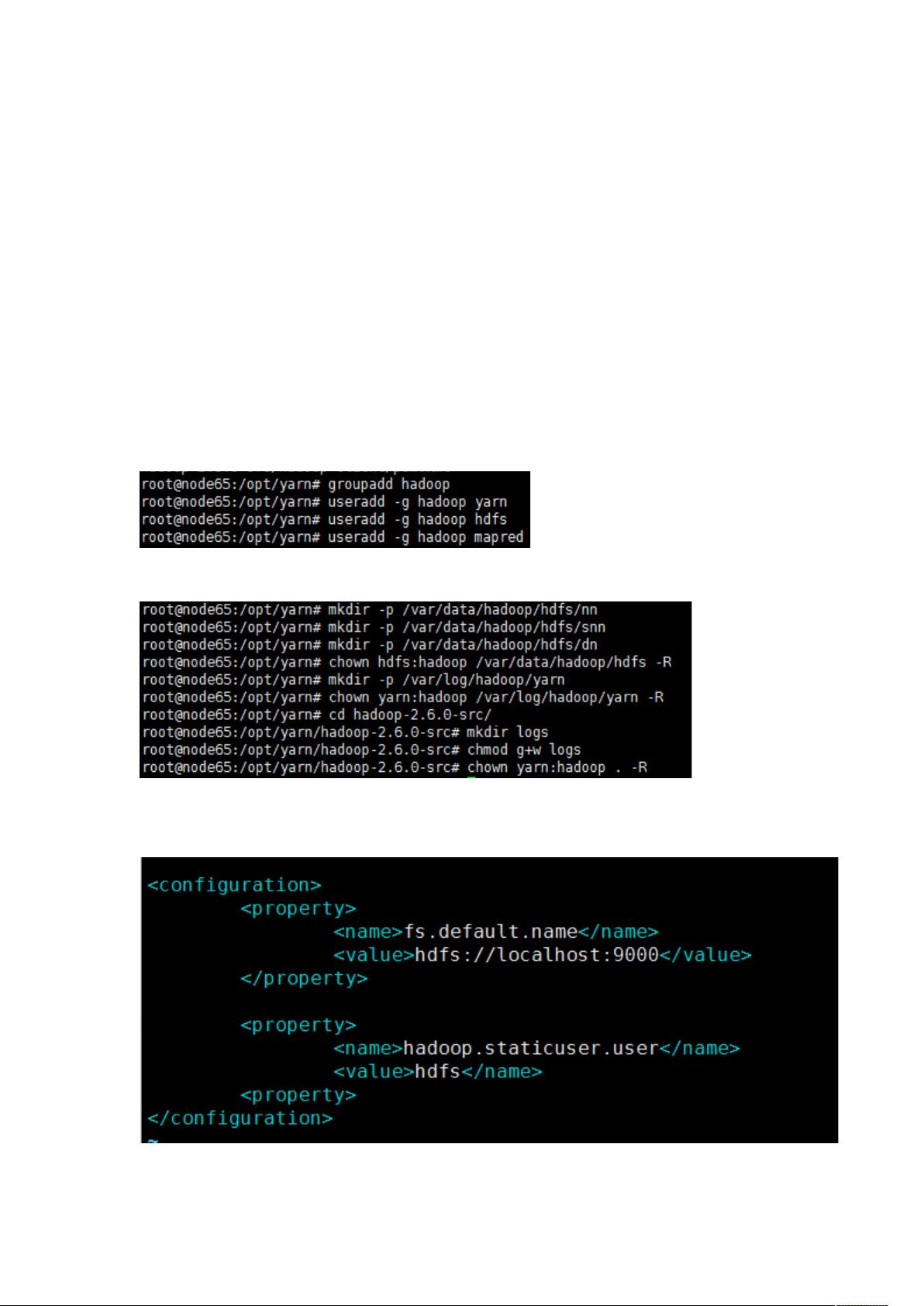
6.配置 core-site.xml
fs.default.name 配置 NameNode 的主机名和端口号;hadoop.http.staticuser.user 指定 hdfs 的默认用户名:
下载后可阅读完整内容,剩余4页未读,立即下载
390 浏览量
774 浏览量
253 浏览量
2025-01-08 上传
303 浏览量
386 浏览量
2022-08-03 上传
1247 浏览量

blueskyliulan
- 粉丝: 7
- 资源: 8
 我的内容管理
展开
我的内容管理
展开







最新资源
- 适合做手机展示的点击图片放大效果
- opencv-3.4.3.rar
- P-SCAN接口EMC设计标准电路与技术资料-综合文档
- Programacion-III-Proyecto-Final
- sahmieyab:Sahmieyab
- flutter_boost:FlutterBoost是一个Flutter插件,可以以最少的工作量将Flutter混合集成到您现有的本机应用程序中
- WAH壁挂式控制箱产品电子样本.zip
- 图片墙桌面效果
- 通讯录源码java-protobuf-AddressBook:GoogleProtobuf和Java。来源:https://github.co
- laravel-shop:Laravel商店套餐
- 基卡德
- OpenIoTHub::sparkling_heart:一个免费的物联网(IoT)平台和私有云。 [一个免费的物联网和私有云平台,支持内网穿透]
- Ajax-ljq_weixin.zip
- jquery实现图片放大效果
- 精通direct3d图形及动画程序设计源代码下载
- JRoll:平滑滚动移动网络
