Kafka集群配置全攻略:从JDK到Hadoop
需积分: 5 156 浏览量
更新于2024-06-22
收藏 500KB DOCX 举报
"Kafka配置步骤.docx"
在配置Apache Kafka之前,我们需要先准备好相关的软件环境。以下是详细的步骤:
1. 安装JDK
Kafka运行依赖于Java开发工具集(JDK),因此首先需要安装JDK。这里推荐的是JDK 8版本,例如`jdk-8u271-linux-x64.tar.gz`。您可以在Oracle官方网站上下载:[https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html](https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html)。安装完成后,确保`JAVA_HOME`环境变量已设置,并且能够在命令行中通过`java -version`验证JDK是否正确安装。
2. 安装Zookeeper
Kafka通常与Zookeeper一起使用来管理集群。需要下载`apache-zookeeper-3.5.8-bin.tar.gz`,可在Zookeeper的官方发布页面找到:[https://zookeeper.apache.org/releases.html](https://zookeeper.apache.org/releases.html)。安装后,需要配置Zookeeper的`zoo.cfg`文件,包括数据目录、客户端连接端口等参数。
3. 下载并安装Kafka
获取Kafka的二进制包,如`kafka_2.12-2.6.0.tgz`,可以从Apache Kafka的下载页面获取:[http://kafka.apache.org/downloads](http://kafka.apache.org/downloads)。解压后,配置Kafka的`server.properties`文件,主要设置包括broker.id、zookeeper.connect、log.dirs等。
4. 安装Hadoop
虽然Hadoop不是Kafka的必需组件,但某些场景下可能需要配合使用。Hadoop可以提供分布式存储和计算能力。您可以从Apache Hadoop的发布页面下载`hadoop-3.2.1.tar.gz`:[https://hadoop.apache.org/releases.html](https://hadoop.apache.org/releases.html)。安装后,配置Hadoop的`core-site.xml`和`hdfs-site.xml`文件,设定HDFS的相关参数。
5. 配置IP地址
在服务器上配置静态IP地址,这对于集群中的节点间通信至关重要。进入`/etc/sysconfig/network-scripts`目录,编辑`ifcfg-eth0`文件,将IPADDR设置为您想要的IP地址,例如`192.168.18.141`,并将PREFIX设为子网掩码,如`24`。配置完后,重启网络服务以应用更改。
6. 配置JDK环境
确保服务器上已安装了JDK,并且可以在命令行中通过`java -version`检查版本。如果使用RPM包管理器安装的JDK,可以使用`rpm -qa | grep java`来查看已安装的Java版本。如果需要设置环境变量,可以编辑`~/.bashrc`或`~/.bash_profile`文件,并添加`JAVA_HOME`、`PATH`等相关环境变量。
7. 启动和测试
配置完成后,启动Zookeeper和Kafka服务。然后,可以使用Kafka提供的命令行工具(如`kafka-topics.sh`、`kafka-console-producer.sh`和`kafka-console-consumer.sh`)进行测试,创建主题、生产消息以及消费消息,以确保Kafka运行正常。
以上是Kafka配置的基本步骤,每个环节都需要仔细处理,确保配置无误。在实际部署时,还需要考虑高可用性、安全性以及监控等高级设置。对于大型生产环境,建议遵循最佳实践和安全指南进行操作。
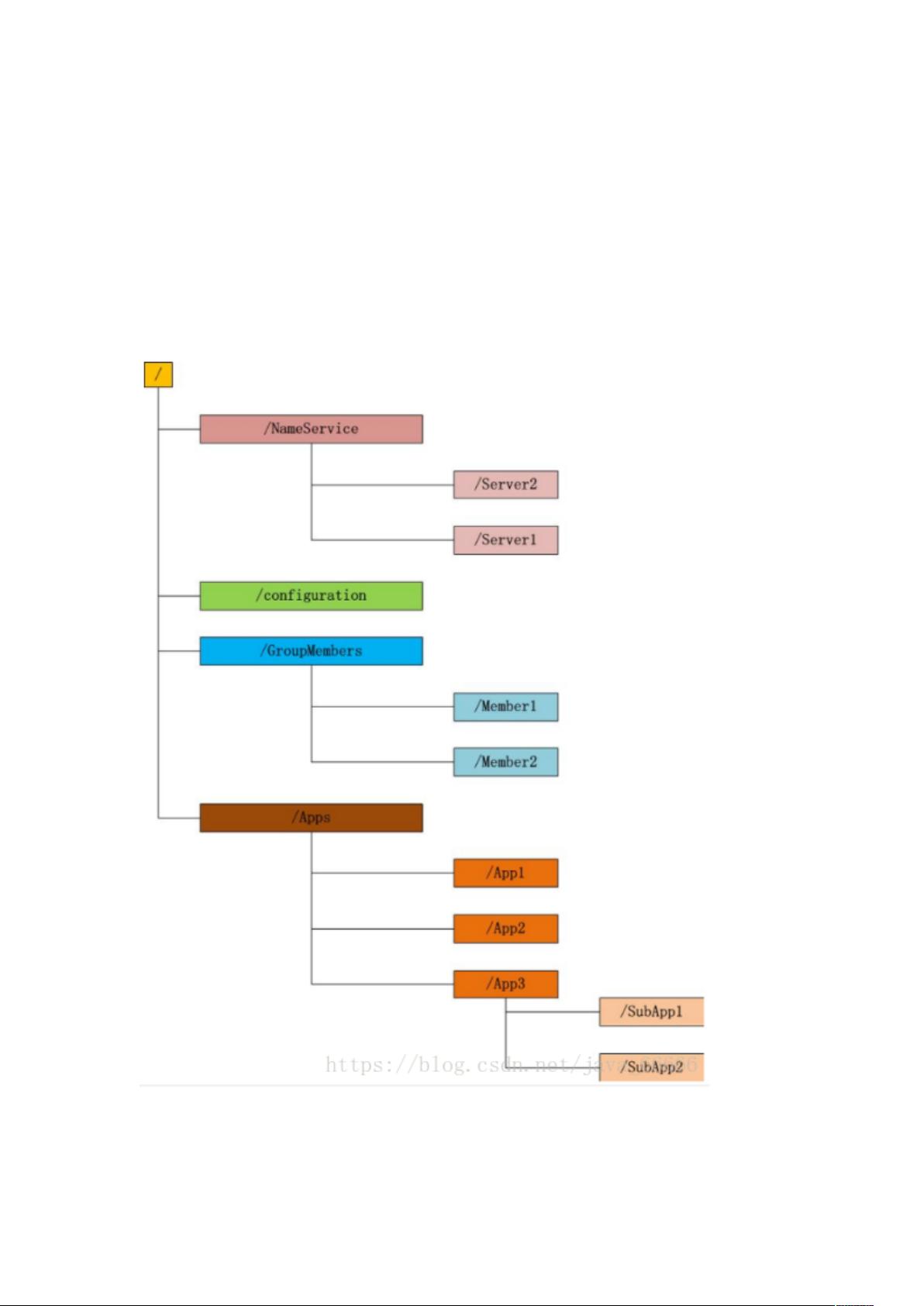
官方文档上这么解释 zookeeper,它是一个分布式服务框架,是 Apache Hadoop 的
一个子项目,它主要是用来解决分布式应用中经常遇到的一些数据管理问题,如:统一命
名服务、状态同步服务、集群管理、分布式应用配置项的管理等。
上面的解释有点抽象,简单来说 zookeeper=文件系统+监听通知机制。
4.7.1、 文件系统
Zookeeper 维护一个类似文件系统的数据结构:
剩余26页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-09-13 上传
2020-06-18 上传
2021-10-26 上传
2021-04-21 上传
2019-12-15 上传
2021-02-05 上传

不货之年
- 粉丝: 21
- 资源: 3
 我的内容管理
展开
我的内容管理
展开







最新资源
- foxcast:福克斯广播公司
- widgets_practice
- opennebula_ng:OpenNebula CloudVM管理软件的厨师食谱
- Tiện ích đặt hàng Đạt Linh Logistics-crx插件
- T-Host:没有像127.0.0.1(Termux)这样的地方
- Python库 | python-evtx-0.2.3.zip
- contacts:第一个教育应用
- ASPNETCore-mvc
- js模仿微信语音播放的动画效果
- capital-bikeshare:作业 14 - Capital Bikeshare
- Engine:CommunityGame的游戏引擎
- draftboard-ui:Redzone隆隆声草稿用户界面
- Купить цветы в Минске - Flower Lab:registered: магазин-crx插件
- Traversal:遍历文件
- 解决Basemap库.zip
- Python库 | python-dikbm-adapter-0.1.7.zip
