快速恢复:多路径分集策略提升数据中心传输效率
4 浏览量
更新于2024-08-26
收藏 1.24MB PDF 举报
"快速谨慎:利用多路径分集进行数据中心传输损失恢复(Fast and Cautious: Leveraging Multi-path Diversity for Transport Loss Recovery in Data Centers)"这篇研究论文探讨了在数据中心网络(DCNs)中实现低TCP流完成时间(Flow Completion Time, FCT)时,如何有效地应对传输损失问题。传统的做法往往依赖于超时机制来检测并恢复数据包丢失,但这可能导致额外的网络拥堵。为了克服这一挑战,论文提出了一种创新的损失恢复方法FUSO(Fast Unidirectional Switching of Operations)。
FUSO的核心思想是利用多路径的多样性来提高恢复效率。当一个多路径传输的发送端怀疑某个子流出现损失时,FUSO不会等待这个子流的超时,而是立即通过另一条不太或同样损失但拥塞窗口余量充足的子流发送恢复数据包。这种设计使FUSO具有快速恢复的能力,因为它能迅速响应传输故障,减少了等待时间。
然而,FUSO的“谨慎”体现在它对拥塞控制算法的尊重上。在切换子流的同时,它会确保不违反网络的流量管理规则,防止因恢复操作引起全局的拥塞,从而维护网络的稳定性和服务质量。作者通过实验台测试和模拟结果展示了FUSO在实际应用中的效果,证明了它能够在保持高效率的同时,有效地平衡快速恢复和网络稳定性。
该研究为数据中心网络设计提供了一种新颖且有效的解决方案,旨在通过智能利用多路径的冗余性和控制策略,优化传输性能,降低FCT,同时保持网络的正常运行。这对于提升数据中心的可用性和响应速度具有重要意义,是现代数据中心网络管理和优化的重要理论依据。
10
−3
10
−2
10
−1
10
−3
10
−2
10
−1
10
0
Packet Loss Rate
Timeout Pr.
100KB (testbed)
100KB (analysis)
10KB (testbed)
10KB (analysis)
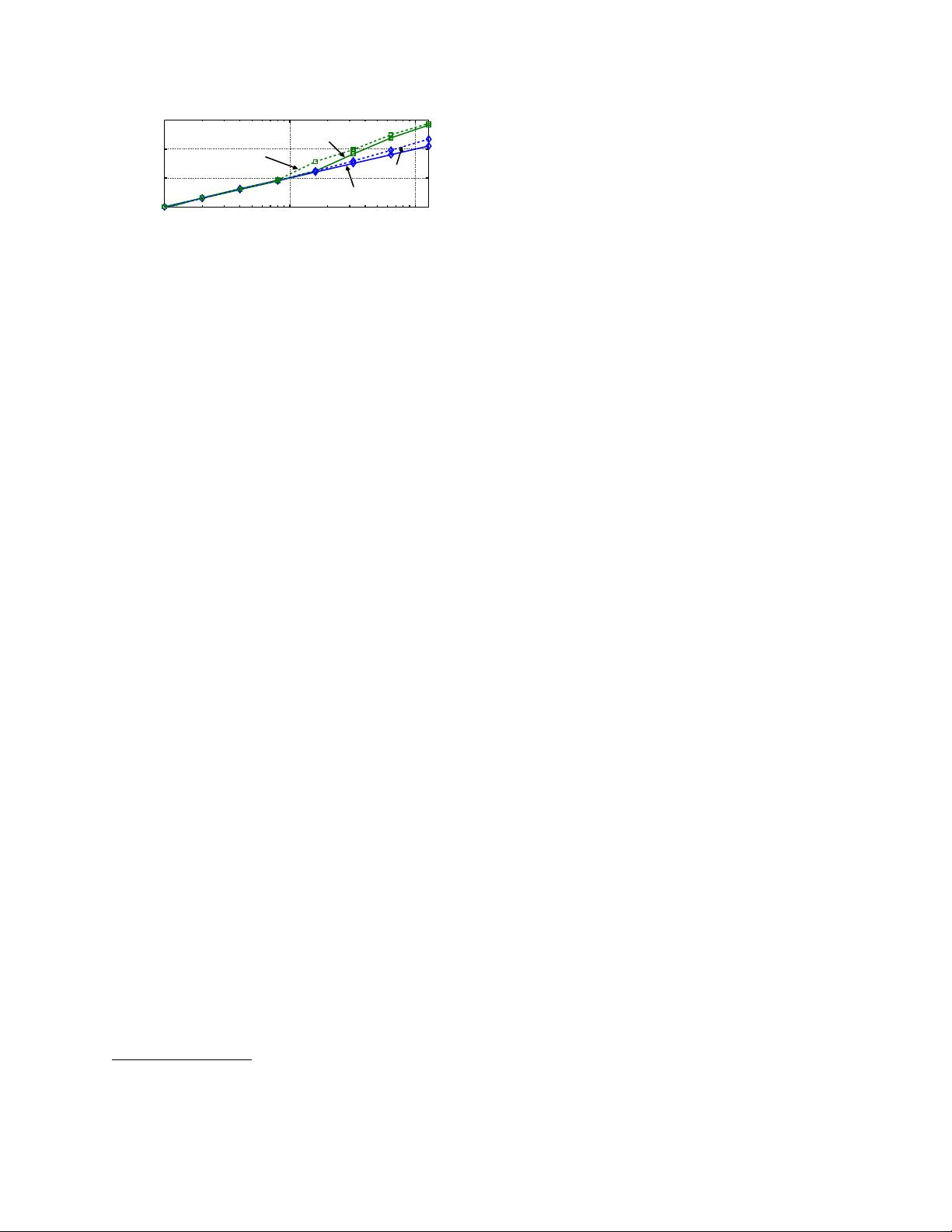
Figure 2: Timeout probability of various flows passing a path with
different random packet loss rate.
ToR, i.e., level1-3). About 22%, 24%, 25% and 29%
of lossy links are located respectively at server↔ToR,
ToR↔Agg, Agg↔Spine and Spine↔Core.
In summary, even in well-engineered modern data
center networks, packet losses are inevitable. Although
the overall loss rate is low, the packet loss rate in some ar-
eas (e.g., links) can exceed several percents, when there
are failures such as malfunctioning hardware or severe
congestions. Moreover, most losses happen in the net-
work instead of the edge.
2.2 Impact of Packet Loss
Once a packet gets lost in the network, TCP needs to
recover it to provide reliable communication. There are
two existing loss detection and recovery mechanisms in
TCP
1
: fast recovery and retransmission timeout (RTO).
Fast recovery detects a packet loss by monitoring dupli-
cated ACKs (or DACKs) and starts to retransmit an old
packet once a certain number (i.e., three) of DACKs have
been received. If there are not enough DACKs, TCP has
to rely on RTO and retransmits all un-ACKed packets
after the timeout. To prevent premature timeouts and
also limited by the kernel timer resolution, the RTO value
is set rather conservatively, usually several times of the
round-trip-time (RTT). Specifically, in a production data
center, the minimum RTO is set to be 5ms [1,3] (the low-
est value supported in current Linux kernel [16]), while
the RTT is usually hundreds of µs [1, 3, 16]. As a con-
sequence, for a latency-sensitive flow, which is usually
small in size, encountering merely one RTO would al-
ready increase its completion time by several times and
cause unacceptable performance degradation.
Therefore, the core issue in achieving low FCT for
small latency-sensitive flows when facing packet losses
is to avoid RTO. However, current TCP still has to rely
on RTO to recover from packet loss in the following three
cases [4, 17, 18]. i) The last packet or a series of consec-
utive packets at the tail of a TCP flow are lost (i.e., tail
loss), where the TCP sender cannot get enough DACKs
to trigger fast recovery and will incur an RTO. ii) A
whole window worth of packets are lost (i.e., whole win-
dow loss). iii) A retransmitted packet also gets lost (i.e.,
retransmission loss).
1
Many production data centers also use DCTCP [1] as their network
transport protocol. DCTCP has the same loss recovery scheme as TCP.
Thus, for ease of presentation, we use TCP to stand for both TCP and
DCTCP while discussing the loss recovery.
To understand how likely RTO may occur to a flow,
we take both a simple mathematical analysis (estimated
lower bound) and testbed experiments to analyze the
timeout probability of a TCP flow with different flow
sizes and different loss rates. We consider one-way ran-
dom loss condition here for simplicity, but the impact
on TCP performance and our FUSO scheme are by no
means limited to this loss pattern (see §5).
Let’s first assume the network path has a loss proba-
bility of p. Assuming the TCP sender needs k DACKs
to trigger fast recovery, any of the last k packets get-
ting lost will lead to an RTO. This tail loss probability is
p
tail
= 1 − (1 − p)
k
. For standard TCP, k = 3, but recent
Linux kernel which implement’s early retransmit [19] re-
duces k to 1 at the end of the transaction. Therefore, if
we consider early retransmit, the tail loss probability is
simply p. The whole window loss probability can eas-
ily be derived as p
win
= p
w
, where w is the TCP win-
dow size. For retransmission loss, clearly, the proba-
bility that both the original packet and its retransmis-
sion are lost is p
2
. Let x be the number of packets in
a TCP flow. The probability that the flow encounters at
least one retransmission loss is p
retx
= 1 − (1 − p
2
)
x
. In
summary, the timeout probability of the flow should be
p
RTO
≥ max(p
tail
, p
win
, p
retx
). The solid lines in Fig. 2
show the analyzed lower bound timeout probability of
a TCP flow with different flow sizes under various loss
rates. Here, we consider the early retransmit (k = 1).
To verify our analysis, we also conduct a testbed ex-
periment to generate TCP flows between two servers. All
flows pass through a path with one-way random loss.
Netem [20, 21] is used to generate different loss rate on
the path. More details about the testbed settings can be
found in §4.2 and §5. The dotted lines in Fig. 2 shows
the testbed results, which verify that our analysis serves
as a good lower bound of the timeout probability.
There are a few observations. Firstly, for tiny flows
(e.g., 10KB), the timeout probability linearly grows with
the random loss rate. This is because the tail loss proba-
bility dominates. However, a tiny loss probability would
affect the tail of FCT. For example, a moderate rise of
the probability to 1% would cause a timeout probability
larger than 1%, which means the 99
th
percentile of FCT
would be greatly impacted. Secondly, when the flow size
increases, e.g., ≥100KB, the retransmission loss may
dominate, especially when the random hardware loss rate
is larger than 1%. We can see a clear rise in timeout prob-
abilities for the flows with 100KB in Fig. 2. In summary,
we conclude that a small random loss rate (i.e., >1%)
would already cause enough flows to timeout to affect
the 99
th
percentile of FCT. This can also explain why a
malfunctioning switch in the Azure datacenter that drops
∼2% of the packets causes great performance degrada-
tion of all the services that traverse this switch [3].
3
剩余13页未读,继续阅读
2011-12-11 上传
2021-11-11 上传
2022-02-10 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
2024-10-20 上传
2024-10-20 上传

weixin_38562130
- 粉丝: 10
- 资源: 978
 我的内容管理
展开
我的内容管理
展开







最新资源
- 明日知道社区问答系统设计与实现-SSM框架java源码分享
- Unity3D粒子特效包:闪电效果体验报告
- Windows64位Python3.7安装Twisted库指南
- HTMLJS应用程序:多词典阿拉伯语词根检索
- 光纤通信课后习题答案解析及文件资源
- swdogen: 自动扫描源码生成 Swagger 文档的工具
- GD32F10系列芯片Keil IDE下载算法配置指南
- C++实现Emscripten版本的3D俄罗斯方块游戏
- 期末复习必备:全面数据结构课件资料
- WordPress媒体占位符插件:优化开发中的图像占位体验
- 完整扑克牌资源集-55张图片压缩包下载
- 开发轻量级时事通讯活动管理RESTful应用程序
- 长城特固618对讲机写频软件使用指南
- Memry粤语学习工具:开源应用助力记忆提升
- JMC 8.0.0版本发布,支持JDK 1.8及64位系统
- Python看图猜成语游戏源码发布
