CUDA与OpenMP并行计算:共享内存策略详解
需积分: 50 3 浏览量
更新于2024-07-23
2
收藏 1.34MB PDF 举报
并行计算是现代计算机科学中的关键领域,它涉及到多个处理器或计算单元协同工作以加速任务执行。CUDA和OpenMP是两种主要的并行编程模型,分别在不同的硬件平台上被广泛应用。
首先,让我们来理解并行计算的基本概念。在传统的串行计算中,程序的每个指令按顺序执行,而在并行计算中,多个操作可以同时进行,通过分工合作提高整体性能。这主要依赖于共享内存(Shared Memory)的概念,这是一种在多核处理器中用于存储多个线程可以访问的数据的内存区域。共享内存使得数据传输更快,减少了全局内存访问的开销,对于提高计算密集型应用的效率至关重要。
CUDA是NVIDIA公司推出的一种并行计算平台和编程模型,专为图形处理单元(GPU)设计。GPU原本是为了渲染图形而设计,但其大量的并行处理单元使其成为执行大量计算任务的理想选择。CUDA编程模型允许开发者编写C/C++代码,并利用CUDA库进行高级的并行计算,如矩阵运算、图像处理等。它利用了GPU的单指令多数据(SIMD)架构,通过线程块和线程层级组织任务,实现大规模并行。
另一方面,OpenMP是一种编译器指令集,支持对多核CPU上的并行化。它不依赖特定硬件,而是通过编程语言本身的扩展来控制线程的创建、同步和通信,适合于多核处理器的并行编程。OpenMP通过共享内存区来协调不同线程之间的数据访问,提供了一种相对简单易用的方式实现并行计算。
两者共同的特点在于利用共享内存来提升性能,但在实现上有所区别:CUDA更专注于GPU并行编程,利用GPU的并行计算能力;而OpenMP则更广泛适用于多核CPU,提供了对现有C/C++代码的增量式并行化。在实际应用中,开发者可以根据项目的具体需求和硬件环境,灵活选择使用CUDA、OpenMP或者其他并行计算框架,以实现最佳的性能优化。
Norm Matloff博士,作为加州大学戴维斯分校计算机科学教授,具有丰富的并行计算背景,他的研究兴趣包括社交网络分析和回归方法论,这表明他在并行计算领域的理论与实践都有着深厚造诣。他不仅是CUDA和OpenMP的使用者,也可能是这些技术的教学者和推广者,为学生和业界提供了解决实际问题的并行计算工具和策略。
理解并行计算、CUDA和OpenMP的核心原理,以及如何有效地利用它们的共享内存机制,对于开发高效、可扩展的现代软件系统至关重要。掌握这些技术,无论是对于学术研究还是工业应用,都能极大地提升计算效率,推动科技进步。

2 CHAPTER 1. INTRODUCTION TO PARALLEL PROCESSING
need for these fast parallel computers. No one wants to wait hours just to generate a single image, and the
use of parallel processing machines can speed things up considerably. For example, consider ray tracing
operations. Here our code follows the path of a ray of light in a scene, accounting for reflection and ab-
sorbtion of the light by various objects. Suppose the image is to consist of 1,000 rows of pixels, with 1,000
pixels per row. In order to attack this problem in a parallel processing manner with, say, 25 processors, we
could divide the image into 25 squares of size 200x200, and have each processor do the computations for its
square.
Note, though, that it may be much more challenging than this implies. First of all, the computation will need
some communication between the processors, which hinders performance if it is not done carefully. Second,
if one really wants good speedup, one may need to take into account the fact that some squares require more
computation work than others. More on this below.
1.1.2 Memory
Yes, execution speed is the reason that comes to most people’s minds when the subject of parallel processing
comes up. But in many applications, an equally important consideration is memory capacity. Parallel
processing application often tend to use huge amounts of memory, and in many cases the amount of memory
needed is more than can fit on one machine. If we have many machines working together, especially in the
message-passing settings described below, we can accommodate the large memory needs.
1.2 Parallel Processing Hardware
This is not a hardware course, but since the goal of using parallel hardware is speed, the efficiency of our
code is a major issue. That in turn means that we need a good understanding of the underlying hardware
that we are programming. In this section, we give an overview of parallel hardware.
1.2.1 Shared-Memory Systems
1.2.1.1 Basic Architecture
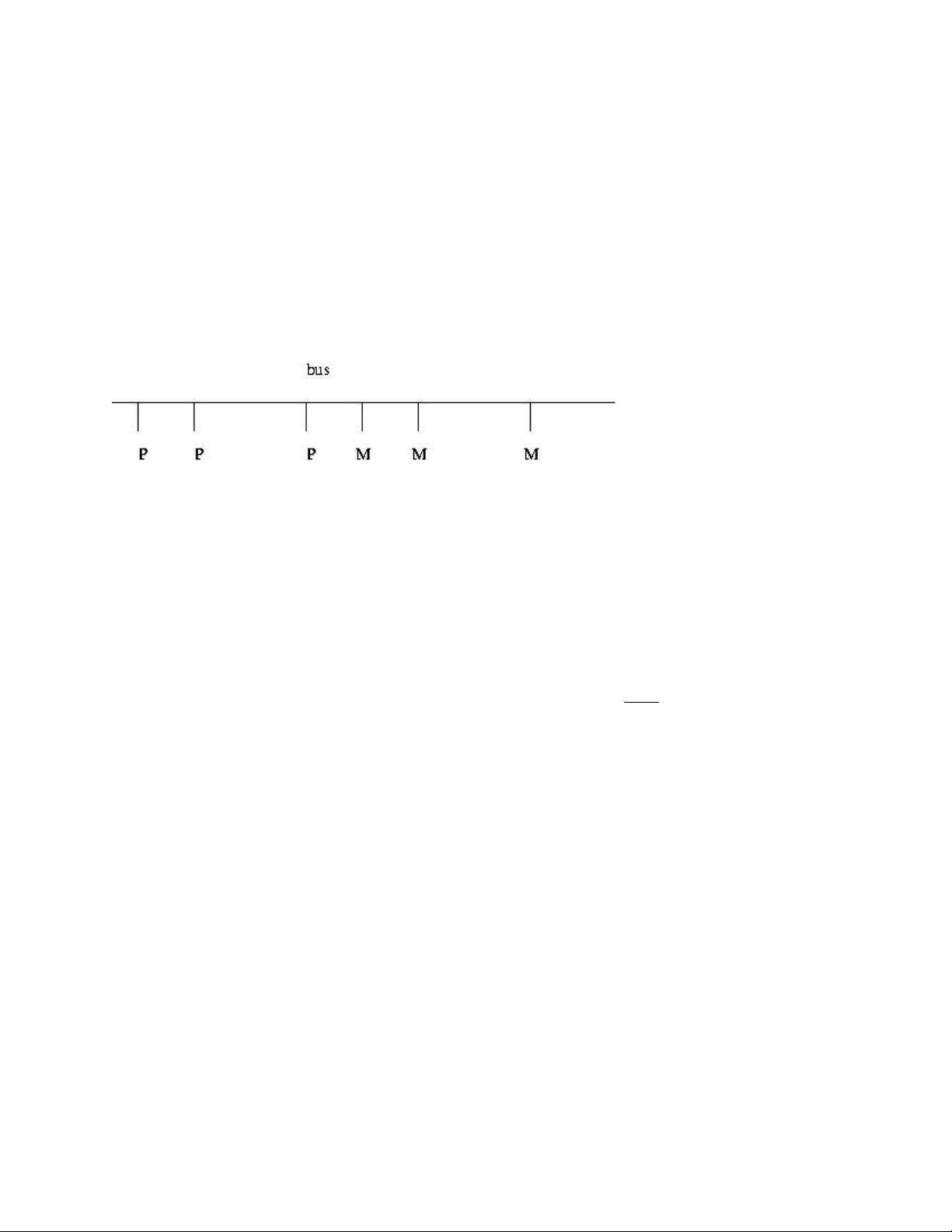
Here many CPUs share the same physical memory. This kind of architecture is sometimes called MIMD,
standing for Multiple Instruction (different CPUs are working independently, and thus typically are exe-
cuting different instructions at any given instant), Multiple Data (different CPUs are generally accessing
different memory locations at any given time).
Until recently, shared-memory systems cost hundreds of thousands of dollars and were affordable only by
large companies, such as in the insurance and banking industries. The high-end machines are indeed still



剩余244页未读,继续阅读
2021-07-14 上传
2021-04-11 上传
2018-02-27 上传
2021-09-24 上传
点击了解资源详情
点击了解资源详情

Shingleon
- 粉丝: 0
- 资源: 12
 我的内容管理
展开
我的内容管理
展开







最新资源
- oracle常用经典sql查询
- JSP+oracle数据库编程中文指南
- PCA特征提取K均值聚类matlab代码
- sql语句大全2是1的补充
- 天书夜读(完整版)PDF版
- 本人提供SQL语句大全(转载) 12009年04月28日 星期二 19:35SQL语句大全(转载)
- SWT-JFace-in-Action.pdf
- MyEclipse 6 开发中文手册
- ActionScript_3.0_Cookbook_中文版
- spring开发指南电子书
- cookie的简单操作
- 预处理命令的学习心得.txt
- xml期末考试试题 xml期末考试试题
- struts国际化的使用
- 仓库温湿度的监测系统论文
- Weblogic管理指南
