Red Hat Linux 9.0 Hadoop单机配置教程
版权申诉
4 浏览量
更新于2024-08-31
收藏 142KB PDF 举报
本文档详细介绍了如何在Red Hat Linux 9.0环境下进行Hadoop的单机配置。Hadoop是一个开源的大数据处理框架,由Apache基金会维护,包含两个主要部分:Hadoop Core,以及作为其扩展的HBase和Hive等子项目。在开始Hadoop的配置之前,有以下几个关键步骤需要注意:
1. **Hadoop获取与安装**:
- 首先,需要从Apache官方网站(http://apache.freelamp.com/hadoop/)下载Hadoop的最新版本,选择适合自己机器配置的操作系统(32或64位)和Java版本(推荐使用1.5.x及以上的Java,尤其是Sun官方版本)。
2. **依赖软件安装**:
- 安装Java是Hadoop的基础,确保已安装并正确版本。对于Ubuntu用户,可以使用`sudo apt-get install ssh` 和 `sudo apt-get install rsync` 进行安装,并设置SSH为开机自启动,可通过ntsysv工具进行操作。
- 对于Red Hat Linux 9,虽然默认安装了SSH,但需要确认版本,并将其设置为开机自启动。可以通过`rpm -q openssh-server`来查看版本,然后使用`/etc/init.d/sshd start`启动或`/etc/init.d/sshd stop`停止服务。
- 对于其他Linux版本,推荐下载并安装OpenSSH,具体可参考官网指南(http://www.openssh.com/portable.html)。
3. **跨节点通信的网络要求**:
Hadoop依赖SSH服务在集群节点间进行数据传输,因此确保所有安装Hadoop的节点之间的网络连接畅通至关重要。这意味着它们需要能够互相访问,以便Hadoop能够正常运行MapReduce任务和其他分布式计算功能。
这篇文档提供了在Red Hat Linux 9.0环境中配置Hadoop单机环境的详细指导,包括软件依赖的安装和配置,特别是SSH服务的设置,这对于理解和部署Hadoop集群的初学者来说是一份宝贵的参考资料。通过遵循这些步骤,读者将能够为自己的环境搭建起一个基础的Hadoop环境,从而进行大数据处理和分析工作。
Red Hat linux 9.0 下 Hadoop单机配置
詹坤林
1 hadoop 获取...................................................... 1
2 hadoop 安装前提 .................................................. 1
3 详细安装过程 .................................................... 2
1 hadoop 获取
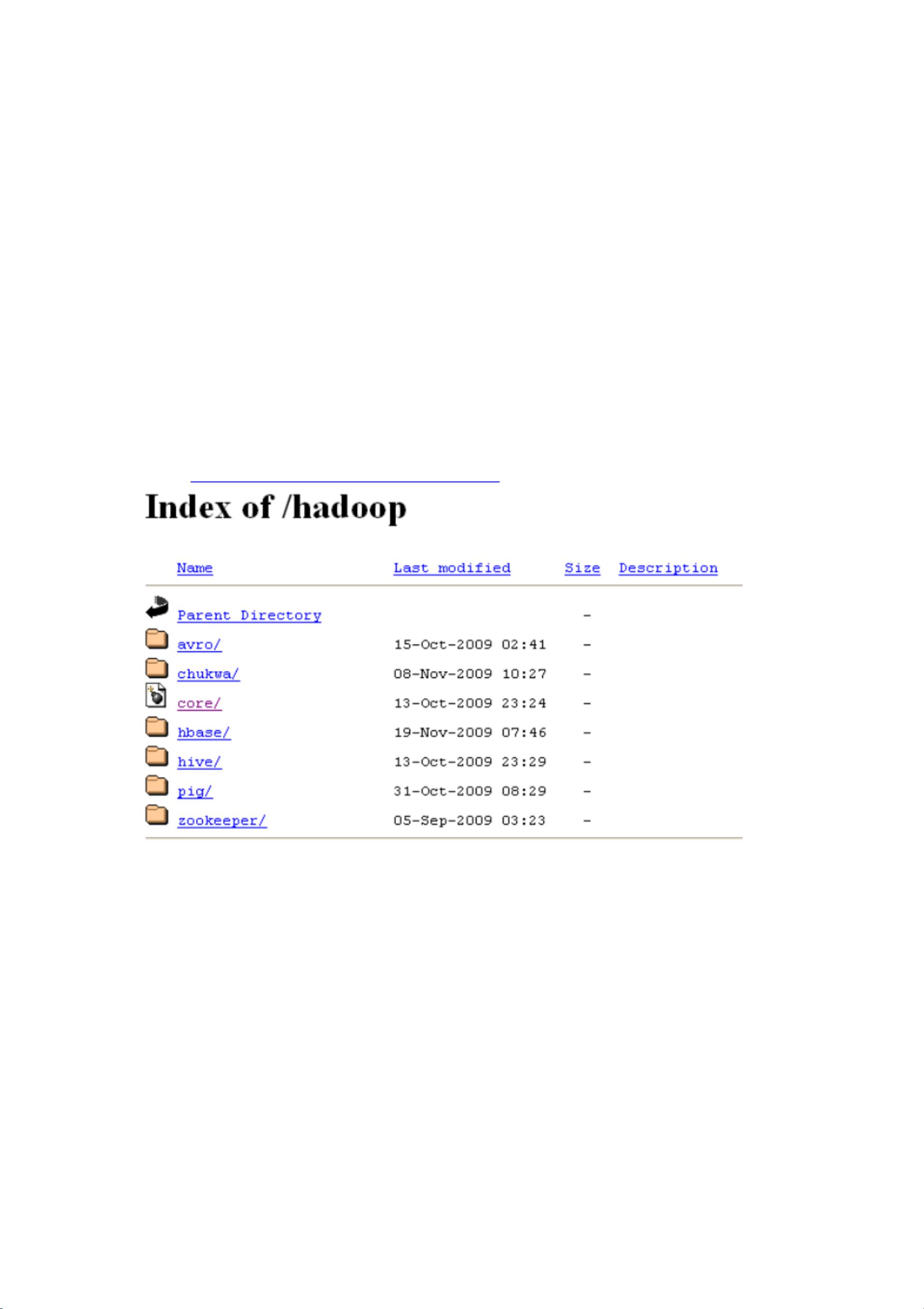
下载: http://apache.freelamp.com/hadoop/
Core 是 hadoop,Hbase,Hive 等都是子项目。
2 hadoop 安装前提
Hadoop 的安装与运行需要依赖以下程序,在安装 Hadoop之前,请确保在计算机上已经安
装了以下软件:
(1)Java?1.5.x 及以上版本, 推荐 Sun公司的官方版本 (http://www.java.com) , 必须安装。
下载后可阅读完整内容,剩余3页未读,立即下载
2022-02-12 上传
2021-12-01 上传
2022-01-07 上传
2021-10-01 上传
2021-11-05 上传
2022-02-15 上传
2021-12-24 上传









