三维时间序列聚类实验:随机生成与相关性距离度量
需积分: 0 9 浏览量
更新于2024-08-05
收藏 677KB PDF 举报
在"三维时间序列聚类的模拟实验1"中,研究者进行了一项针对三维时间序列的聚类验证工作。实验的核心步骤主要包括以下几个部分:
1. **随机序列生成与预处理**:
实验首先生成了三种类型的三维时间序列,每类序列包含三个指标,每个指标是基于特定函数(如正弦、对数、指数等)生成并添加随机噪声。这些函数定义了各维度特征的变化规律。为了确保数据的可比性,生成的序列进行了预处理,包括断点查找和标准化。断点查找有助于识别序列中的关键变化点,标准化则是为了消除指标间数值差异对距离计算的影响。
2. **相关性距离度量**:
在多维时间序列中,研究采用了基于相关系数的距离度量方法。这种方法考虑了序列中各个指标之间的关联性。对于两个三维时间序列,通过计算标准化后的指标值的差异(𝑑𝑖𝑗),然后计算每个维度的距离(𝑝𝑖),最后综合所有维度的距离来衡量两个序列的整体相似度。
3. **实验流程**:
- 生成随机序列A、B、C,每个序列包含三个特征序列,它们具有不同的数学表达式,如正弦、指数和对数函数组合。
- 对每个序列的特征序列进行断点查找,这有助于了解序列结构的变化点。
- 应用标准化方法对原始序列进行处理,确保在计算距离时不受各维度值差异的影响。
- 计算基于相关系数的距离度量,这在多维情况下可能涉及到复杂的矩阵运算,如计算相关系数矩阵和计算矩阵的平方根。
4. **结果展示与可视化**:
实验的结果通常会以图表的形式展示,包括生成的随机序列图、断点查找结果以及聚类后的时间序列分布图。这些可视化可以帮助评估模型的聚类效果,比如不同类别序列的区分度、聚类的稳定性等。
通过这个模拟实验,研究者旨在验证其提出的基于特征相关性的距离度量方法在三维时间序列聚类任务中的有效性,并为进一步优化和改进聚类算法提供依据。这种实验方法不仅适用于理论研究,也适用于实际应用中的大规模时间序列数据处理和分析。
三维时间序列聚类的模拟实验
该部分主要通过模拟生成 3 类三维时间序列来验证模型聚类效果。在此我们提出一种
新型的基于特征相关性的距离度量来刻画多维时间序列的距离。分析过程只要包括如下几部
分:
⚫ 随机三维序列的生成与数据预处理(包括断点查找与标准化)
⚫ 相关性距离的度量方法
⚫ 结果展示与可视化
一、生成随机序列
首先生成各类时间序列的特征序列,每类特征序列的表达式均由此生成:
其中
服从正态分布。均值为 0,方差为序列
方差的 0.6 倍。定义
表达式如下
表所示:
类 A
类 B
类 C
特征 1
特征 2
特征 3
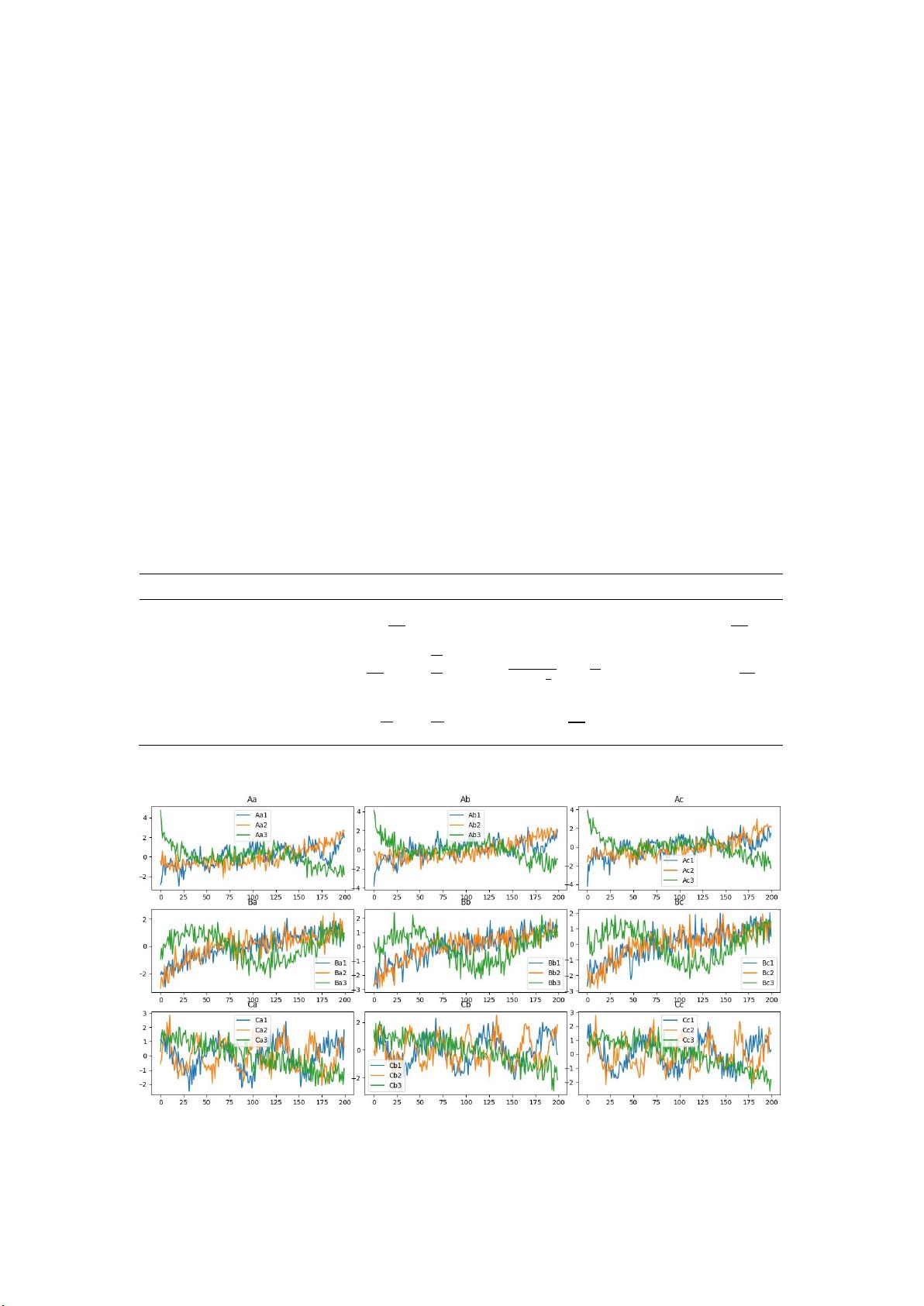
生成的序列图如下图所示。其中 Aa 表示第 A 类第 a 个三位序列,Aa1,Aa2,Aa3 分别表
示该三维时间序列的三个指标序列。
Figure 1
下载后可阅读完整内容,剩余3页未读,立即下载
2010-04-26 上传
点击了解资源详情
点击了解资源详情
2024-04-20 上传
2010-06-28 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

魏水华
- 粉丝: 18
- 资源: 282
 我的内容管理
展开
我的内容管理
展开







最新资源
- 构建基于Django和Stripe的SaaS应用教程
- Symfony2框架打造的RESTful问答系统icare-server
- 蓝桥杯Python试题解析与答案题库
- Go语言实现NWA到WAV文件格式转换工具
- 基于Django的医患管理系统应用
- Jenkins工作流插件开发指南:支持Workflow Python模块
- Java红酒网站项目源码解析与系统开源介绍
- Underworld Exporter资产定义文件详解
- Java版Crash Bandicoot资源库:逆向工程与源码分享
- Spring Boot Starter 自动IP计数功能实现指南
- 我的世界牛顿物理学模组深入解析
- STM32单片机工程创建详解与模板应用
- GDG堪萨斯城代码实验室:离子与火力基地示例应用
- Android Capstone项目:实现Potlatch服务器与OAuth2.0认证
- Cbit类:简化计算封装与异步任务处理
- Java8兼容的FullContact API Java客户端库介绍
